Vysokoškolské vzdělání se stává kritickým pilířem společenského a ekonomického života 21. století. Je to klíčové nejen ve vzdělávacím procesu, ale také pro zajištění dvou životně důležitých věcí:skvělého zaměstnání a finanční stability. Na druhou stranu předvídání přijetí na univerzitu může být extrémně náročné, protože žáci neznají přijímací standardy.
V tomto tutoriálu tedy vytvoříme vlastní model předpovědi přijetí na univerzitu pomocí programovacího jazyka Python.
Úvod do datové sady
Při podávání žádostí o magisterské studium v zahraničí je třeba zvážit několik proměnných. Kromě jiného musíte mít slušné skóre GRE, sop (prohlášení o účelu) nebo referenční dopis. Pokud nejste z anglicky mluvící země, musíte také odeslat skóre TOEFL.
K datové sadě se dostanete zde . Datová sada obsahuje následující atributy:
- Skóre GRE (z 340)
- Skóre TOEFL (ze 120)
- Hodnocení univerzity (z 5)
- Prohlášení o účelu a doporučená síla (z 5)
- Pregraduální GPA (z 10)
- Zkušenosti s výzkumem (buď 0 nebo 1)
- Šance na přijetí (v rozsahu od 0 do 1)
Implementace ochrany před přijetím na univerzitu v Pythonu
Celou implementaci kódu bychom rozdělili do několika kroků, jak je uvedeno níže:
Krok 1:Import nezbytných modulů/knihoven
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from keras.models import Sequential from keras.layers import Dense ,Dropout,BatchNormalization from keras.layers import Dense from keras.wrappers.scikit_learn import KerasRegressor
Krok 2:Načtení datové sady do programu
df = pd.read_csv('Admission_Predict.csv')
df.head()
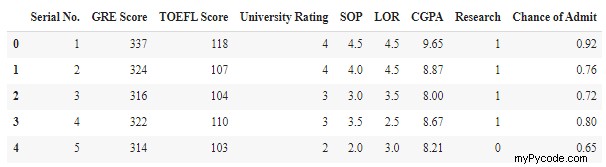
Krok 3:Předzpracování dat a rozdělení dat
Před vytvořením našeho hlavního modelu bychom vyžadovali určité předběžné zpracování, které zahrnuje odstranění jakéhokoli sloupce, který není pro model nezbytný.
Zde sloupec ‚Sériové číslo‘ není nutný pro predikci přijetí, takže jej z dat vynecháme.
df=df.drop("Serial No.",axis=1)
Poté bychom datovou sadu rozdělili na X a Y dílčí datové sady, kde X bude mít všechny informace a Y bude zahrnovat konečnou pravděpodobnost.
Y=np.array(df[df.columns[-1]]) X=np.array(df.drop(df.columns[-1],axis=1))
Nyní je dalším krokem rozdělení datové sady na trénovací a testovací datové sady pomocí pravidla 80:20 vlakového testovacího rozdělení, kde se 80 % dat použije pro trénování a zbývajících 20 % se použije pro testování.
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=0.2, random_state=0)
Předzpracování bude také zahrnovat normalizaci trénovací datové sady, které lze dosáhnout pomocí kódu uvedeného níže.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train=scaler.fit_transform(X_train) X_test=scaler.fit_transform(X_test)
Krok 3:Vytvoření modelu
Níže uvedený kód je hlavní funkcí, která popisuje celý model zahrnující deklaraci modelu a přidávání vrstev do modelu.
Funkce také zahrnuje sestavení modelu a výpočet ztráty.
def baseline_model():
model = Sequential()
model.add(Dense(16, input_dim=7, activation='relu'))
model.add(Dense(16, input_dim=7, activation='relu'))
model.add(Dense(16, input_dim=7, activation='relu'))
model.add(Dense(16, input_dim=7, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
Krok 4:Školení modelu
Dalším krokem je vytvořit objekt modelu a natrénovat jej na trénovací datové sadě, jak je uvedeno v kódu níže. Počet epoch si můžete ponechat podle vlastních preferencí.
estimator = KerasRegressor(build_fn=baseline_model, epochs=50, batch_size=3, verbose=1) estimator.fit(X_train,y_train)
Výstup školení je následující:
Epoch 1/50 107/107 [==============================] - 1s 3ms/step - loss: 0.1087 Epoch 2/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0065 Epoch 3/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0057 Epoch 4/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0052 Epoch 5/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0049 Epoch 6/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0050 Epoch 7/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0047 Epoch 8/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0049 Epoch 9/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0044 Epoch 10/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0043 Epoch 11/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0044 Epoch 12/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0044 Epoch 13/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0043 Epoch 14/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0041 Epoch 15/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0043 Epoch 16/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0042 Epoch 17/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0040 Epoch 18/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0043 Epoch 19/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0039 Epoch 20/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0040 Epoch 21/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0039 Epoch 22/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0042 Epoch 23/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0040 Epoch 24/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0038 Epoch 25/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0042 Epoch 26/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0038 Epoch 27/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0040 Epoch 28/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0042 Epoch 29/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0039 Epoch 30/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 31/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0038 Epoch 32/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0043 Epoch 33/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0040 Epoch 34/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 35/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0039 Epoch 36/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 37/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0038 Epoch 38/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0036 Epoch 39/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0036 Epoch 40/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0036 Epoch 41/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 42/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 43/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0036 Epoch 44/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 45/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 46/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0038 Epoch 47/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0036 Epoch 48/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0037 Epoch 49/50 107/107 [==============================] - 0s 4ms/step - loss: 0.0037 Epoch 50/50 107/107 [==============================] - 0s 3ms/step - loss: 0.0034 <keras.callbacks.History at 0x7f10c0173e10> [19] 0s
Krok 5:Testování modelu
Nyní se pokusme předpovědět hodnoty pro testovací datovou sadu a porovnat je s původními hodnotami.
prediction = estimator.predict(X_test)
print("ORIGINAL DATA")
print(y_test)
print()
print("PREDICTED DATA")
print(prediction)
Výstup vypadá nějak takto:
ORIGINAL DATA [0.71 0.7 0.79 0.73 0.72 0.48 0.77 0.71 0.9 0.94 0.58 0.89 0.72 0.57 0.78 0.42 0.64 0.84 0.63 0.72 0.9 0.83 0.57 0.47 0.85 0.67 0.44 0.54 0.92 0.62 0.68 0.73 0.73 0.61 0.55 0.74 0.64 0.89 0.73 0.95 0.71 0.72 0.75 0.76 0.86 0.7 0.39 0.79 0.61 0.64 0.71 0.8 0.61 0.89 0.68 0.79 0.78 0.52 0.76 0.88 0.74 0.49 0.65 0.59 0.87 0.89 0.81 0.9 0.8 0.76 0.68 0.87 0.68 0.64 0.91 0.61 0.69 0.62 0.93 0.43] PREDICTED DATA [0.64663166 0.6811929 0.77187485 0.59903866 0.70518774 0.5707331 0.6844891 0.6232987 0.8559068 0.9225058 0.50917023 0.9055291 0.6913604 0.40199894 0.8595592 0.6155516 0.5891675 0.793468 0.5415057 0.7054745 0.8786436 0.8063141 0.55548865 0.3587063 0.77944946 0.5391258 0.43374807 0.62050253 0.90883577 0.6109837 0.64160395 0.7341113 0.73316455 0.5032365 0.7664028 0.76009744 0.59858805 0.86267006 0.60282356 0.94984144 0.7196544 0.63529354 0.7032968 0.8164513 0.8044792 0.6359613 0.54865533 0.6914524 0.589018 0.55952907 0.6446153 0.77345765 0.6449453 0.8998446 0.68746895 0.74362046 0.71107167 0.73258513 0.7594558 0.8374823 0.7504637 0.4027493 0.61975926 0.46762955 0.8579673 0.814696 0.7111042 0.8707262 0.7539967 0.7515583 0.5506843 0.8436626 0.8139006 0.5593421 0.933276 0.61958474 0.6084135 0.63294107 0.9234169 0.44476634]
Můžete vidět, že hodnoty se do určité míry shodují. Ale ujistěte se, že počítáme i střední chybu.
Krok 6:Výpočetní průměrná chyba
from sklearn.metrics import accuracy_score
train_error = np.abs(y_test - prediction)
mean_error = np.mean(train_error)
print("Mean Error: ",mean_error)
Průměrná chyba je 0,0577927375137806 což je dost dobré na to, abychom řekli, že naše výsledky jsou docela přesné.
Závěr
Blahopřejeme! Právě jste se dozvěděli o vytváření vlastního prediktoru přijetí na univerzitu. Doufám, že jste si to užili! 😇
Líbil se vám výukový program? V každém případě bych vám doporučil podívat se na níže uvedené návody:
- Předpověď ceny kryptoměny s Pythonem
- Předpověď tržeb Box Office v Pythonu – snadná implementace
- Předpověď ceny akcií pomocí Pythonu
- Klasifikace vína pomocí Pythonu – snadno vysvětlitelná
Děkujeme, že jste si udělali čas! Doufám, že jste se naučili něco nového!! 😄