Du har muligvis gennemgået forskellige eksempler på tekstfilhåndtering, hvor du skal have skrevet tekst ind i filen eller udtrukket den fra filen som helhed (ved at bruge 'read()'-funktionen) eller linje for linje (ved at bruge 'readline() ' eller 'readlines()'-funktion). Og her behøver vi heller ikke importere noget eksternt bibliotek, det er indbygget i forskellige versioner af Python.
Men i tilfælde af at arbejde med PDF-filer er lidt anderledes. Vi skal muligvis arbejde med PDF-filer for at udføre forskellige Natural Language Processing-opgaver eller til andre formål. Som standard kommer Python ikke med nogen af de indbyggede biblioteker, der kan hjælpe os med at læse og skrive PDF-filer. Derfor skal vi bruge et eksternt bibliotek kendt som 'PyPDF' (den seneste version er PyPDF4, men vi vil bruge PyPDF2).
PyPDF er et fuldstændigt uafhængigt bibliotek. Det betyder, at det kører på hver Python-platform uden nogen afhængighed af nogen anden ekstern biblioteksunderstøttelse. PyPDF er i stand til at udtrække dokumentoplysninger, opdele dokumenter, flette dokumenter, beskære sider i PDF, kryptere og dekryptere osv.
Læsning af PDF-fil linje for linje
Før vi kommer ind i koden, er en vigtig ting, der skal nævnes, at her har vi at gøre med tekstbaserede PDF'er (de PDF'er, der er genereret ved hjælp af tekstbehandling), fordi Image -baseret PDF skal håndteres med et andet bibliotek kendt som 'pyTesseract'. Det betyder ikke, at det ikke kan håndteres med PyPDF, men der er en ulempe ved at bruge dette, at vi skal ændre dets kodning og konvertere det til tekstbaseret PDF, hvilket ville resultere i tab af data. Derfor er det ikke tilrådeligt at gøre det. I stedet vil vi dække dette emne om billedbaserede PDF'er i en anden artikel.
Så lad os komme i gang, vores første opgave er at installere PyPDF-biblioteket.
Installation:
$ pip3 install PyPDF2
Nu er det tur til den faktiske kode, men en vigtig ting at forstå er, at der ikke er nogen direkte metode i PyPDF-biblioteket til at læse PDF-fil linje for linje, den læser den altid som en helhed (ved hjælp af 'extractText()' funktion), men en god ting at vide, at den altid returnerer 'String' som output.
Så her skal vi finde en vis lighed i adskillelsen af hver eneste linje i hele PDF-dokumentet. Her havde jeg brugt en eksempel PDF-fil (mypdf), i denne er hver linje adskilt af en masse tomme mellemrum, så jeg har fundet min måde at opdele linjerne på (ved hjælp af 'split()' funktion) med to tomme mellemrum som parameter. Der kan være PDF-filer, hvor linjer vil blive adskilt af '\n', så du kan bruge dette som en parameter for funktionen 'split()'.
Kildekode:
Nu nedenfor er vores Python-program til at læse PDF-filen linje for linje:
# Importing required modules
import PyPDF2
# Creating a pdf file object
pdfFileObj = open('mypdf.pdf','rb')
# Creating a pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# Getting number of pages in pdf file
pages = pdfReader.numPages
# Loop for reading all the Pages
for i in range(pages):
# Creating a page object
pageObj = pdfReader.getPage(i)
# Printing Page Number
print("Page No: ",i)
# Extracting text from page
# And splitting it into chunks of lines
text = pageObj.extractText().split(" ")
# Finally the lines are stored into list
# For iterating over list a loop is used
for i in range(len(text)):
# Printing the line
# Lines are seprated using "\n"
print(text[i],end="\n\n")
# For Seprating the Pages
print()
# closing the pdf file object
pdfFileObj.close()
Output:
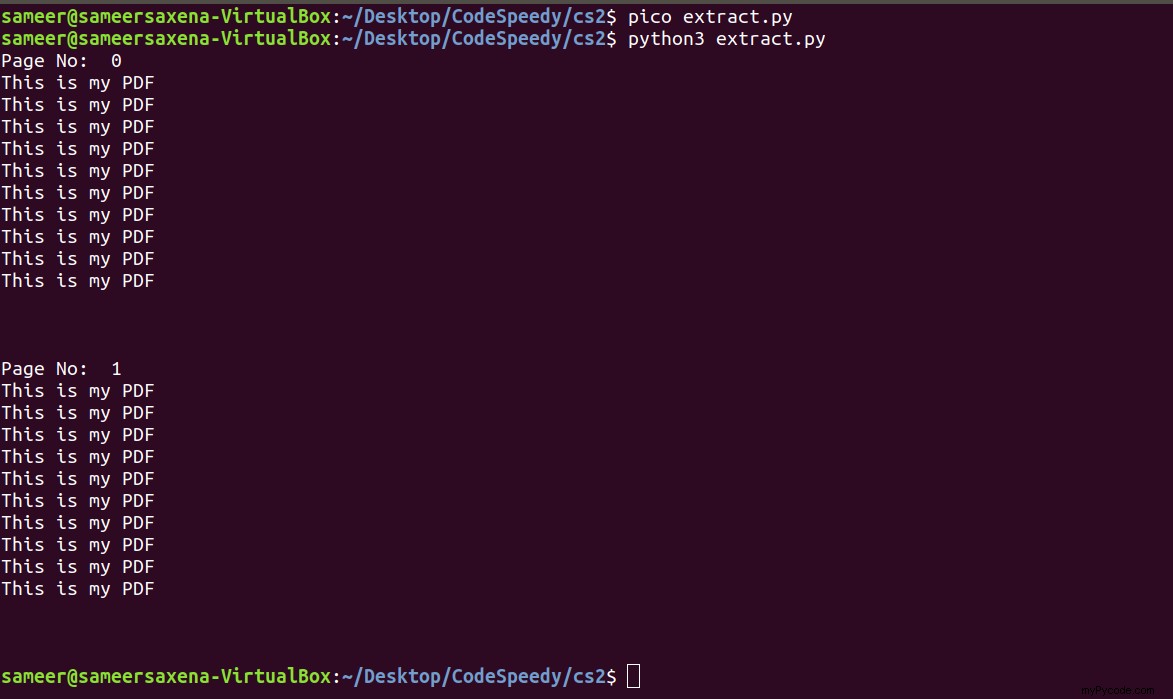
Som du kan se, vises hvert sideindhold i konsollen.
Jeg håber, at denne artikel vil være frugtbar for dig, 'Fortsæt med at lære, fortsæt med at kode' .

