Apprenez différentes méthodes pour résumer des données en Python.
Les données, c'est le pouvoir. Plus nous avons de données, plus nous créons des produits meilleurs et plus robustes. Cependant, travailler avec de grandes quantités de données présente des défis. Nous avons besoin d'outils et de packages logiciels pour obtenir des informations, par exemple pour créer un résumé des données en Python.
Un nombre important de solutions et de produits basés sur les données utilisent des données tabulaires, c'est-à-dire des données stockées dans un format de tableau avec des lignes et des colonnes étiquetées. Chaque ligne représente une observation (c'est-à-dire un point de données) et les colonnes représentent des caractéristiques ou des attributs concernant cette observation.
À mesure que le nombre de lignes et de colonnes augmente, il devient plus difficile d'inspecter les données manuellement. Étant donné que nous travaillons presque toujours avec de grands ensembles de données, l'utilisation d'un outil logiciel pour résumer les données est une exigence fondamentale.
Les résumés de données sont utiles pour une variété de tâches :
- Apprentissage de la structure sous-jacente d'un ensemble de données
- Comprendre la distribution des fonctionnalités (c'est-à-dire les colonnes).
- Analyse exploratoire des données.
En tant que principal langage de programmation dans l'écosystème de la science des données, Python dispose de bibliothèques pour créer des résumés de données. La bibliothèque la plus populaire et la plus utilisée à cette fin est pandas. LearnPython propose un cours d'introduction à Python pour la science des données qui couvre la bibliothèque pandas en détail.
pandas est une bibliothèque d'analyse et de manipulation de données pour Python. Dans cet article, nous passons en revue plusieurs exemples pour montrer comment utiliser les pandas pour créer et afficher des résumés de données.
Commencer avec les pandas
Commençons par importer des pandas.
import pandas as pd
Considérez un ensemble de données de ventes au format CSV qui contient les ventes et les quantités en stock de certains produits et leurs groupes de produits. Nous créons un pandas DataFrame pour les données de ce fichier et affichons les 5 premières lignes comme ci-dessous :
df = pd.read_csv(“sales.csv”) df.head()
Sortie :
Un résumé des données dans pandas commence par vérifier la taille des données. Le shape renvoie un tuple avec le nombre de lignes et de colonnes d'un DataFrame.
>>> df.shape (300, 4)
Il contient 300 lignes et 4 colonnes. Il s'agit d'un ensemble de données propre prêt à être analysé. Cependant, la plupart des ensembles de données réels nécessitent un nettoyage. Voici un article qui explique les modules de nettoyage de données Python les plus utiles.
Nous continuons à résumer les données en nous concentrant sur chaque colonne séparément. pandas a deux structures de données principales :DataFrame et Series. Un DataFrame est une structure de données bidimensionnelle, alors qu'une série est unidimensionnelle. Chaque colonne d'un DataFrame peut être considérée comme une série.
Les caractéristiques des données catégorielles et numériques étant très différentes, il est préférable de les traiter séparément.
Colonnes catégorielles
Si une colonne contient des données catégorielles comme la colonne du groupe de produits dans notre DataFrame, nous pouvons vérifier le nombre de valeurs distinctes qu'elle contient. Nous le faisons avec le unique() ou nunique() fonctions.
>>> df["product_group"].unique() array(['A', 'C', 'B', 'G', 'D', 'F', 'E'], dtype=object) >>> df["product_group"].nunique() 7
Le nunique() renvoie le nombre de valeurs distinctes, alors que le unique() fonction affiche les valeurs distinctes. Une autre fonction de résumé couramment utilisée sur les colonnes catégorielles est value_counts() . Il affiche les valeurs distinctes dans une colonne ainsi que le nombre de leurs occurrences. Ainsi, nous obtenons un aperçu de la distribution des données.
>>> df["product_group"].value_counts() A 102 B 75 C 63 D 37 G 9 F 8 E 6 Name: product_group, dtype: int64
Le groupe A a le plus de produits, suivi du groupe B avec 75 produits. La sortie du value_counts() fonction est triée par ordre décroissant du nombre d'occurrences.
Colonnes numériques
Lorsque vous travaillez avec des colonnes numériques, nous avons besoin de différentes méthodes pour résumer les données. Par exemple, cela n'a pas de sens de vérifier le nombre de valeurs distinctes pour la colonne de quantité des ventes. Au lieu de cela, nous calculons des mesures statistiques telles que la moyenne, la médiane, le minimum et le maximum.
Calculons d'abord la valeur moyenne de la colonne Quantité des ventes.
>>> df["sales_qty"].mean() 473.557
Nous sélectionnons simplement la colonne qui nous intéresse et appliquons le mean() fonction. Nous pouvons également effectuer cette opération sur plusieurs colonnes.
>>> df[["sales_qty","stock_qty"]].mean() sales_qty 473.557 stock_qty 1160.837 dtype: float64
Lorsque vous sélectionnez plusieurs colonnes à partir d'un DataFrame, assurez-vous de les spécifier sous forme de liste. Sinon, pandas génère une erreur de clé.
Tout aussi facilement que nous pouvons calculer une seule statistique sur plusieurs colonnes en une seule opération, nous pouvons calculer plusieurs statistiques à la fois. Une option consiste à utiliser le apply() fonctionnent comme ci-dessous :
>>> df[["sales_qty","stock_qty"]].apply(["mean","median"])
Sortie :
Les fonctions sont écrites dans une liste puis passées à apply() . La médiane est la valeur au milieu lorsque les valeurs sont triées. La comparaison des valeurs moyennes et médianes nous donne une idée de l'asymétrie de la distribution.
Nous avons beaucoup d'options pour créer un résumé des données dans les pandas. Par exemple, nous pouvons utiliser un dictionnaire pour calculer des statistiques distinctes pour différentes colonnes. Voici un exemple :
df[["sales_qty","stock_qty"]].apply(
{
"sales_qty":["mean","median","max"],
"stock_qty":["mean","median","min"]
}
)
Sortie :
Les clés du dictionnaire indiquent les noms des colonnes et les valeurs montrent les statistiques à calculer pour cette colonne.
On peut faire les mêmes opérations avec le agg() fonction au lieu de apply() . La syntaxe est la même, alors ne soyez pas surpris si vous tombez sur des tutoriels qui utilisent le agg() fonction à la place.
pandas est une bibliothèque très utile et pratique à bien des égards. Par exemple, nous pouvons calculer diverses statistiques sur toutes les colonnes numériques avec une seule fonction :describe() :
>>> df.describe()
Sortie :
Les statistiques de ce DataFrame nous donnent un large aperçu de la distribution des valeurs. Le nombre est le nombre de valeurs (c'est-à-dire de lignes). Les « 25 % », « 50 % » et « 75 % » indiquent respectivement les premier, deuxième et troisième quartiles. Le deuxième quartile (c'est-à-dire 50 %) est également connu sous le nom de médiane. Enfin, "std" est l'écart type de la colonne.
Un résumé des données en Python peut être créé pour une partie spécifique du DataFrame. Il suffit de filtrer la partie pertinente avant d'appliquer les fonctions.
Par exemple, nous décrivons les données uniquement pour le groupe de produits A comme suit :
df[df["product_group"]=="A"].describe()
Nous sélectionnons d'abord les lignes dont la valeur du groupe de produits est A, puis utilisons le describe() fonction. La sortie est dans le même format que dans l'exemple précédent, mais les valeurs sont calculées uniquement pour le groupe de produits A.
Nous pouvons également appliquer des filtres sur des colonnes numériques. Par exemple, la ligne de code suivante calcule la quantité moyenne des ventes de produits avec un stock supérieur à 500.
df[df["stock_qty"]>500]["sales_qty"].mean()
Sortie :
476.951
pandas permet de créer des filtres plus complexes assez efficacement. Voici un article qui explique en détail comment filtrer en fonction des lignes et des colonnes avec des pandas.
Résumer des groupes de données
Nous pouvons créer un résumé des données séparément pour différents groupes dans les données. C'est assez similaire à ce que nous avons fait dans l'exemple précédent. Le seul ajout est le regroupement des données.
Nous regroupons les lignes par les valeurs distinctes dans une colonne avec le groupby() fonction. Le code suivant regroupe les lignes par groupe de produits.
df.groupby("product_group") Une fois les groupes formés, nous pouvons calculer n'importe quelle statistique et décrire ou résumer les données. Calculons la quantité moyenne des ventes pour chaque groupe de produits.
df.groupby("product_group")["sales_qty"].mean() Sortie :
product_group A 492.676471 B 490.253333 C 449.285714 D 462.864865 E 378.666667 F 508.875000 G 363.444444 Name: sales_qty, dtype: float64
Nous pouvons également effectuer plusieurs agrégations en une seule opération. En plus des quantités moyennes des ventes, comptons également le nombre de produits dans chaque groupe. Nous utilisons le agg() qui permet également d'attribuer des noms aux colonnes agrégées.
df.groupby("product_group").agg(
avg_sales_qty = ("sales_qty", "mean"),
number_of_products = ("product_code","count")
)
Sortie :
Distribution des données avec un histogramme Matplotlib
La visualisation des données est une autre technique très efficace pour résumer les données. Matplotlib est une bibliothèque populaire en Python pour explorer et résumer visuellement les données.
Il existe de nombreux types de visualisations de données. Un histogramme est utilisé pour vérifier la distribution des données des colonnes numériques. Il divise toute la plage de valeurs en groupes discrets et compte le nombre de valeurs dans chaque groupe. En conséquence, nous obtenons un aperçu de la distribution des données.
Créons un histogramme de la colonne de quantité des ventes.
import matplotlib.pyplot as plt plt.figure(figsize=(10,6)) plt.hist(df["sales_qty"], bins=10)
Dans la première ligne, nous importons le pyplot interface de Matplotlib. La deuxième ligne crée un objet figure vide avec la taille spécifiée. La troisième ligne trace l'histogramme de la colonne de quantité des ventes sur le figure objet. Le paramètre bins détermine le nombre de bins.
Voici le tracé généré par ce code :
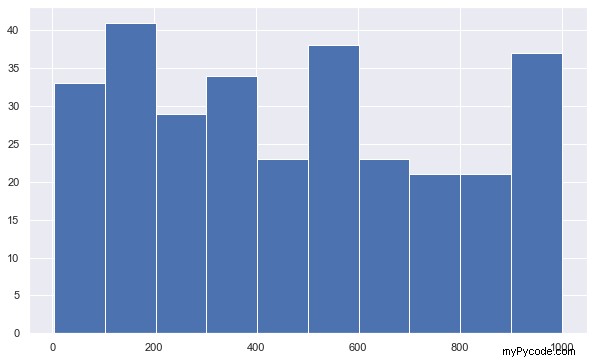
Les valeurs sur l'axe des abscisses montrent les bords du bac. Les valeurs sur l'axe des ordonnées indiquent le nombre de valeurs dans chaque groupe. Par exemple, il y a plus de 40 produits dont la quantité vendue est comprise entre 100 et 200.
Résumé des données en Python
Il est d'une importance cruciale de comprendre les données disponibles avant de créer des produits basés sur les données. Vous pouvez commencer avec un résumé des données en Python. Dans cet article, nous avons passé en revue plusieurs exemples avec les bibliothèques pandas et Matplotlib pour résumer les données.
Python propose une riche sélection de bibliothèques qui accélèrent et simplifient les tâches en science des données. Le parcours Python pour la science des données est un bon début pour votre parcours en science des données.