Le nettoyage des données est un élément essentiel de l'analyse des données. Si vous avez besoin de ranger une trame de données avec Python, cela vous aidera à faire le travail.
Python est le langage de programmation incontournable pour la science des données. L'une des raisons pour lesquelles il est si populaire est la riche sélection de bibliothèques . Les fonctions et méthodes fournies par ces bibliothèques accélèrent les tâches typiques de la science des données.
Les données réelles sont généralement désordonnées et ne sont pas présentées dans un format approprié pour l'analyse des données. Vous passerez probablement beaucoup de temps à nettoyer et à prétraiter les données avant qu'elles ne soient prêtes pour l'analyse. Ainsi, il est extrêmement important de se familiariser avec les bibliothèques de nettoyage de données de Python. Notre cours d'introduction à Python pour la science des données fournit un excellent aperçu des bases de Python et présente les bibliothèques Python fondamentales pour le nettoyage des données et le rangement des cadres de données .
Dans cet article, nous passerons en revue certaines des bibliothèques de nettoyage de données de Python. Certains d'entre eux sont très couramment utilisés, comme les pandas et NumPy. En fait, Pandas pourrait être la bibliothèque Python la plus populaire pour la science des données. Certaines des bibliothèques que nous aborderons ne sont pas aussi populaires, mais elles sont utiles pour des tâches particulières.
pandas
pandas est la bibliothèque d'analyse et de manipulation de données la plus utilisée pour Python. Il fournit de nombreuses fonctions et méthodes pour le nettoyage des données. Sa syntaxe conviviale facilite la compréhension et la mise en œuvre de solutions.
Les dataframes sont structure de données de base des pandas; ils stockent les données sous forme de tableau avec des lignes et des colonnes étiquetées. pandas est assez flexible en termes de manipulation des dataframes, ce qui est essentiel pour un processus de nettoyage des données efficace.
Vous pouvez facilement ajouter ou supprimer des colonnes ou des lignes. Combinaison de dataframes le long de lignes ou de colonnes à l'aide du concat la fonction est simple. Dans certains cas, vous devrez également collecter des données à partir de plusieurs dataframes. La fonction de fusion est utilisée pour fusionner des dataframes basés sur une ou plusieurs colonnes partagées.
Les données brutes ne sont pas toujours au format optimal. Dans ce cas, vous devrez créer des colonnes dérivées. Vous pouvez appliquer des agrégations de base sur les colonnes existantes pour en créer de nouvelles. pandas peut effectuer de telles opérations de manière vectorisée, ce qui le rend très rapide. En plus des agrégations de base, pandas accepte les fonctions définies par l'utilisateur ou les expressions lambda pour prétraiter les colonnes existantes.
La gestion des valeurs manquantes est une partie essentielle du nettoyage des données. C'est une tâche en deux étapes :vous détectez d'abord les valeurs manquantes, puis vous les remplacez par les valeurs appropriées. NA et NaN sont les représentations standard des valeurs manquantes utilisées par les pandas. Le isna() la fonction renvoie true si une valeur dans une cellule est manquante. Vous pouvez combiner les isna() et sum() pour trouver le nombre de valeurs manquantes dans les colonnes, les lignes ou l'ensemble du dataframe.
La deuxième étape consiste à remplir les valeurs manquantes. Vous devez gérer les valeurs manquantes avec soin pour assurer la cohérence des données. Le fillna() fournit de nombreuses options différentes pour remplir les valeurs manquantes.
pandas est capable de gérer non seulement des données numériques, mais également des données textuelles et des dates . Ses opérations spécifiques au type de données sont regroupées sous des accesseurs, ce qui facilite leur apprentissage. Le str accessor a plusieurs fonctions qui manipulent les chaînes. De même, le dt accessor fournit plusieurs fonctions qui manipulent d ates et t fois.
Considérez l'exemple de trame de données suivant qui contient les colonnes de nom et d'âge.
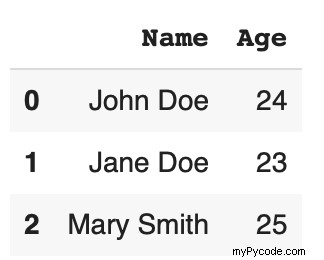
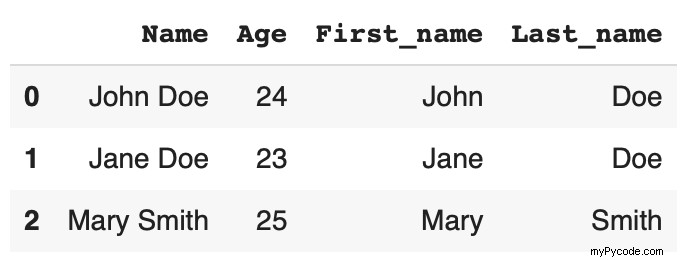
Si vous souhaitez afficher les noms et prénoms séparément, le split fonction sous le str accessor accomplit cette tâche en une seule ligne de code.
df[['First_name', 'Last_name']] = df['Name'].str.split(' ', expand=True)
Voici à quoi ressemble la trame de données :
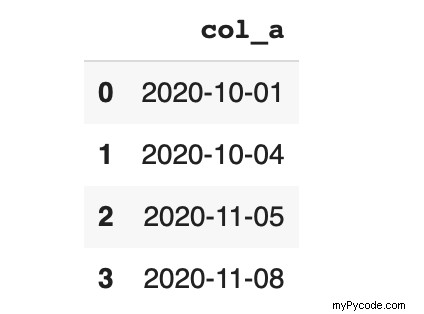
Faisons aussi un exemple avec le dt accesseur. Dans certains cas, une certaine partie d'une date doit être extraite. Par exemple, vous pouvez avoir besoin que les informations sur le mois ou le jour de la semaine soient séparées.
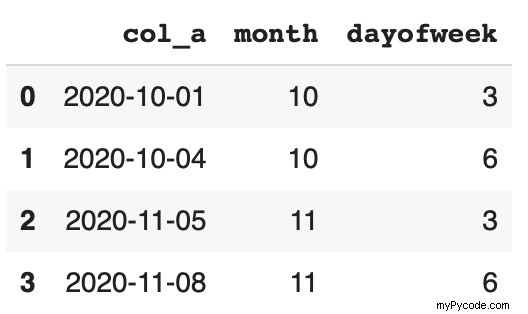
Nous pouvons facilement extraire le mois et le jour de la semaine et les affecter à de nouvelles colonnes.
df['month'] = df.col_a.dt.month df['dayofweek'] = df.col_a.dt.dayofweek
Vous pouvez en savoir plus sur les pandas sur son site officiel. Ses pages de documentation sont un bon point de départ, car elles contiennent de nombreux exemples.
NumPy
NumPy est une bibliothèque de calcul scientifique pour Python et une bibliothèque fondamentale pour l'écosystème de la science des données. Certaines bibliothèques populaires sont construites sur NumPy, notamment pandas et Matplotlib.
Ces dernières années, il est devenu extrêmement facile de collecter et de stocker des données. Nous sommes susceptibles de travailler avec des quantités substantielles de données. Ainsi, une bibliothèque informatique efficace est essentielle pour le nettoyage et la manipulation des données.
NumPy nous offre des fonctions et des méthodes de calcul efficaces. Sa syntaxe est facile à saisir. La puissance de NumPy devient plus perceptible lorsque vous travaillez avec des tableaux multidimensionnels .
Vous pouvez en savoir plus sur NumPy sur son site officiel.
Matplotlib
Matplotlib est surtout connu comme une bibliothèque de visualisation de données, mais il est également utile pour le nettoyage des données. Vous pouvez créer des diagrammes de distribution, qui nous aident à mieux comprendre les données. Afin de construire une stratégie précise et robuste pour gérer les valeurs manquantes, il est très important d'avoir une compréhension globale de la structure sous-jacente des données.
La figure suivante est un histogramme, qui divise la plage de valeurs des variables continues en groupes discrets et montre combien de valeurs se trouvent dans chaque groupe . Il peut fournir des informations utiles pour le nettoyage des données.
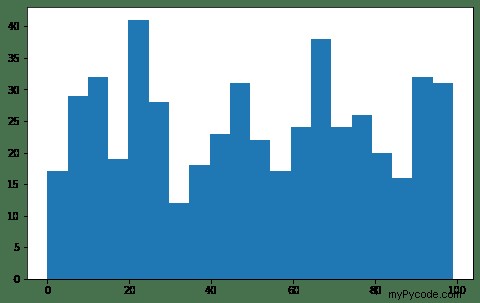
En savoir plus sur Matplotlib sur son site officiel.
non manquant
J'ai mentionné l'importance de gérer les valeurs manquantes; le missingno bibliothèque est un outil très pratique pour cette tâche. Il fournit des visualisations informatives sur les valeurs manquantes dans une trame de données .
Par exemple, vous pouvez créer une matrice de valeurs manquantes qui affiche un aperçu des positions des valeurs manquantes dans la trame de données. Ensuite, vous pourrez repérer les zones avec beaucoup de valeurs manquantes.
La figure suivante montre une matrice de valeurs manquantes . Les lignes horizontales blanches indiquent les valeurs manquantes. Vous pouvez facilement remarquer leur distribution, ce qui est un élément important pour votre stratégie afin de gérer les valeurs manquantes.

Ici, nous pouvons voir que nous avons beaucoup de données manquantes dans la première colonne et encore plus dans la troisième colonne.
La bibliothèque missingno fournit également une carte thermique et un graphique à barres pour afficher les valeurs manquantes.
La bibliothèque peut être installée avec pip en utilisant la commande suivante :
pip install missingno
En savoir plus sur missingno sur la page GitHub du projet.
nettoyeur de données
datacleaner est un package tiers qui fonctionne avec les dataframes Pandas. Ce qu'il fait peut également être réalisé avec Pandas, mais datacleaner propose une méthode succincte qui combine quelques opérations typiques. En ce sens, cela permet d'économiser du temps et des efforts.
datacleaner peut effectuer les opérations suivantes :
- Supprimer les lignes avec des valeurs manquantes.
- Remplacez les valeurs manquantes par une valeur appropriée.
- Encoder les variables catégorielles.
En savoir plus sur datacleaner sur la page GitHub du projet.
Modifier
Modin peut être considéré comme un pandas amplificateur de performances . Il distribue des données et des calculs pour accélérer le code pandas. Selon la documentation de Modin, cela peut augmenter la vitesse des pandas jusqu'à 4 fois.
Ce que j'aime le plus chez Modin, c'est son intégration fluide avec les pandas. Cela n'ajoute aucune complexité inutile à la syntaxe des pandas. Vous importez Modin, remplaçant l'importation régulière de pandas, puis vous êtes prêt à partir :
import modin.pandas as pd
En savoir plus sur Modin sur son site officiel.
Jolis Pandas
PrettyPandas étend la classe pandas DataFrame afin que vous puissiez personnaliser l'affichage des dataframes . Comme son nom l'indique, PrettyPandas améliore l'apparence des dataframes.
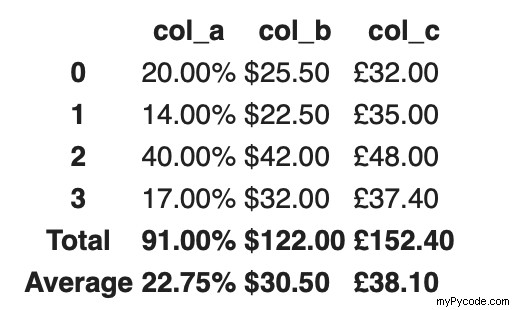
PrettyPandas vous permet de créer des tableaux qui peuvent être mis directement dans des rapports. Vous pouvez facilement ajouter des signes de pourcentage et de devise dans les cellules. Une autre fonctionnalité utile est que les valeurs totales et moyennes des colonnes peuvent être affichées avec le tableau.
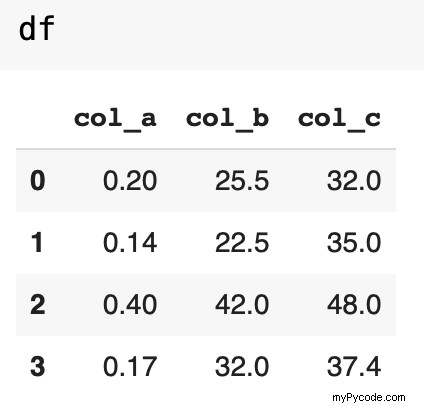
Considérez la trame de données pandas suivante :
Après avoir installé PrettyPandas avec pip , nous pouvons l'importer et l'utiliser pour personnaliser ce dataframe. Le bloc de code suivant ajoute des signes de pourcentage à la première colonne et aux signes monétaires aux deuxième et troisième colonnes. Avec .total() et .average() , nous ajoutons rapidement des lignes récapitulatives à notre table.
from prettypandas import PrettyPandas
(
df
.pipe(PrettyPandas)
.as_percent(subset = 'col_a')
.as_currency('USD', subset = 'col_b')
.as_currency('GBP', subset = 'col_c')
.total()
.average()
)
Voici à quoi ressemble la trame de données :
En savoir plus sur PrettyPandas sur son site officiel.
Les bibliothèques Python facilitent le nettoyage des données
Le nettoyage des données est une tâche fondamentale de la science des données. Même si vous concevez et mettez en œuvre un modèle à la pointe de la technologie, sa qualité dépend des données que vous fournissez. Ainsi, avant de vous concentrer sur un modèle, vous devez vous assurer que les données d'entrée sont propres et dans un format approprié.
Dans l'écosystème Python, de nombreuses bibliothèques peuvent être utilisées pour le nettoyage et la préparation des données. Ces bibliothèques fournissent de nombreuses fonctions et méthodes qui vous aideront à mettre en œuvre un processus de nettoyage des données robuste et efficace. Ce n'est qu'une des raisons pour lesquelles vous devriez apprendre Python en 2021.
Python ne concerne bien sûr pas seulement le nettoyage des données. Il existe des bibliothèques Python qui correspondent également à d'autres tâches dans le domaine de la science des données. Voici un article qui explique les 13 principales bibliothèques Python que vous devriez connaître.

