Nous examinons les bibliothèques Python de base et avancées pour la science des données. Découvrez comment obtenir, traiter, modéliser et visualiser des données dans Python.
L'écosystème Python offre une large gamme d'outils pour les data scientists. Pour les débutants, il peut être difficile de faire la distinction entre les outils fondamentaux de la science des données et les « bien-à-avoir ». Dans cet article, je vais vous guider à travers les bibliothèques Python les plus populaires pour la science des données.
Bibliothèques Python pour l'obtention de données
La science des données commence par les données. Pour effectuer une analyse de données ou une modélisation avec Python, vous devez d'abord importer vos données. Les données peuvent être stockées dans différents formats, mais heureusement, la communauté Python a développé de nombreux packages pour obtenir des données d'entrée. Voyons quelles bibliothèques Python sont les plus populaires pour importer et préparer des données.
csv
CSV (Comma Separated Values) est un format courant pour stocker des données tabulaires ainsi que pour importer et exporter des données. Pour gérer les fichiers CSV , Python a un module csv intégré. Par exemple, si vous avez besoin de lire des données à partir d'un fichier CSV, vous pouvez utiliser le csv.reader() fonction, qui parcourt essentiellement les lignes du fichier CSV. Si vous souhaitez exporter des données au format CSV, le csv.writer() la fonction peut gérer cela.
LearnPython.com propose un cours dédié intitulé Comment lire et écrire des fichiers CSV en Python, où vous pouvez vous exercer à travailler avec le csv module.
json
JSON, ou JavaScript Object Notation, est un format standard de stockage et d'échange de données textuelles. Même s'il s'inspire d'un sous-ensemble du langage de programmation JavaScript, JSON est indépendant du langage :vous n'avez pas besoin de connaître JavaScript pour travailler avec des fichiers JSON.
Pour encoder et décoder les données JSON , Python a un module intégré appelé json. Après avoir importé le json module, vous pourrez lire des documents JSON avec le json.load() méthode ou convertir vos données en fichiers JSON avec le json.dump() méthode.
Dans le cours Comment lire et écrire des fichiers JSON en Python, vous aurez 35 exercices interactifs pour vous exercer à gérer les données JSON en Python.
openpyxl
Si vos données sont principalement stockées dans Excel, vous trouverez la bibliothèque openpyxl très utile. Il est né pour lire et écrire des documents Excel 2010 . La bibliothèque prend en charge les fichiers xlsx, xlsm, xltx et xltm. Contrairement aux packages ci-dessus, openpyxl n'est pas intégré à Python; vous devrez l'installer avant de l'utiliser.
Cette bibliothèque vous permet de lire des feuilles de calcul Excel, d'importer des données spécifiques à partir d'une feuille particulière, d'ajouter des données à la feuille de calcul existante et de créer de nouvelles feuilles de calcul avec des formules, des images et des graphiques.
Consultez le cours interactif Comment lire et écrire des fichiers Excel en Python pour vous exercer à interagir avec des classeurs Excel à l'aide de Python.
Scrapy
Si les données que vous souhaitez utiliser se trouvent sur le Web, Python propose plusieurs packages qui les obtiendront de manière simple et rapide. Scrapy est une bibliothèque open source populaire pour explorer des sites Web et extraire des données structurées .
Avec Scrapy, vous pouvez, par exemple, gratter Twitter pour les tweets d'un compte particulier ou avec des hashtags spécifiés. Le résultat peut inclure de nombreuses informations au-delà du tweet lui-même; vous pouvez obtenir un tableau avec les noms d'utilisateur, les temps de tweet et les textes, le nombre de likes, de retweets et de réponses, etc. Outre le scraping Web, Scrapy peut également être utilisé pour extraire des données à l'aide d'API.
Sa rapidité et sa flexibilité font de Scrapy un excellent outil pour extraire des données structurées qui peuvent être traitées ultérieurement et utilisées dans divers projets de science des données.
Belle soupe
Beautiful Soup est une autre bibliothèque populaire pour obtenir des données sur le Web. Il a été créé pour extraire des informations utiles à partir de fichiers HTML et XML , y compris ceux dont la syntaxe et la structure ne sont pas valides. Le nom inhabituel de cette bibliothèque Python fait référence au fait que ces pages mal balisées sont souvent appelées "soupe de balises".
Lorsque vous exécutez un document HTML via Beautiful Soup, vous obtenez un BeautifulSoup objet qui représente le document sous la forme d'une structure de données imbriquée. Ensuite, vous pouvez facilement naviguer dans cette structure de données pour obtenir ce dont vous avez besoin, par ex. le texte de la page, les URL des liens, les titres spécifiques, etc.
La flexibilité de la bibliothèque Beautiful Soup est remarquable. Consultez-le si vous avez besoin de travailler avec des données Web.
Bibliothèques Python pour le traitement et la modélisation des données
Après avoir obtenu vos données, vous devrez les nettoyer et les préparer pour l'analyse et la modélisation. Passons en revue les bibliothèques Python qui aident les scientifiques des données à préparer des données et à créer et entraîner des modèles de machine learning.
pandas
Pour ceux qui travaillent avec des données tabulaires en Python, pandas est le premier choix pour l'analyse et la manipulation des données. L'une de ses principales caractéristiques est le cadre de données, une structure de données dédiée aux données bidimensionnelles . Les objets de bloc de données ont des lignes et des colonnes, tout comme les tableaux dans Excel.
La bibliothèque pandas dispose d'un vaste ensemble d'outils pour le nettoyage, la manipulation, l'analyse et la visualisation des données. Avec les pandas, vous pouvez :
- Ajouter, supprimer et mettre à jour des colonnes de bloc de données
- Gérer les valeurs manquantes.
- Indexer, renommer, trier et fusionner les blocs de données
- Distribution des données de tracé, etc.
Si vous souhaitez commencer à travailler avec des données tabulaires en Python, consultez notre cours Introduction à Python pour la science des données. Il comprend 141 exercices interactifs qui vous permettent de pratiquer une analyse et une manipulation simples des données avec la bibliothèque pandas.
NumPy
NumPy est une bibliothèque Python fondamentale pour la science des données. Il est conçu pour effectuer des opérations numériques avec des tableaux à n dimensions . Les tableaux stockent des valeurs du même type de données. La vectorisation NumPy des tableaux améliore considérablement les performances et accélère la vitesse des opérations de calcul.
Avec NumPy, vous pouvez effectuer des opérations de base et avancées sur les tableaux (par exemple, ajouter, multiplier, trancher, remodeler, indexer), générer des nombres aléatoires et effectuer des routines d'algèbre linéaire, des transformées de Fourier, etc.
SciPy
SciPy est une bibliothèque fondamentale pour le calcul scientifique . Il est basé sur NumPy et tire parti de nombreux avantages de cette bibliothèque pour travailler avec des tableaux.
Avec SciPy, vous pouvez effectuer des tâches de programmation scientifique telles que le calcul, les équations différentielles ordinaires, l'intégration numérique, l'interpolation, l'optimisation, l'algèbre linéaire et les calculs statistiques.
scikit-apprendre
Une bibliothèque Python fondamentale pour l'apprentissage automatique, scikit-learn se concentre sur la modélisation des données après avoir été nettoyé et préparé (en utilisant des bibliothèques comme NumPy et pandas). C'est un outil très efficace pour l'analyse prédictive des données. De plus, il est adapté aux débutants, ce qui rend l'apprentissage automatique avec Python accessible à tous.
Avec seulement quelques lignes de code, scikit-learn vous permet de créer et d'entraîner des modèles d'apprentissage automatique pour la régression, la classification, le regroupement, la réduction de dimensionnalité, etc. Il prend en charge des algorithmes tels que les machines à vecteurs de support (SVM), les forêts aléatoires, les k-moyennes, l'amplification de gradient et bien d'autres.
PyTorch
PyTorch est un framework d'apprentissage en profondeur open source construit par le laboratoire de recherche sur l'IA de Facebook. Il a été créé pour mettre en œuvre des réseaux de neurones avancés et des idées de recherche de pointe dans l'industrie et le milieu universitaire.
Comme scikit-learn, PyTorch se concentre sur la modélisation des données. Cependant, il est destiné aux utilisateurs avancés qui travaillent principalement avec des réseaux de neurones profonds. PyTorch est un excellent outil à utiliser lorsque vous avez besoin d'un modèle de machine learning prêt pour la production, rapide, efficace, évolutif et pouvant fonctionner avec un environnement distribué.
TensorFlow
TensorFlow est une autre bibliothèque open source pour développer et former des modèles d'apprentissage automatique . Construit par l'équipe Google Brain, TensorFlow est un concurrent majeur de PyTorch dans le développement d'applications d'apprentissage en profondeur.
TensorFlow et PyTorch avaient des différences majeures, mais ils ont maintenant adopté de nombreuses fonctionnalités intéressantes l'un de l'autre. Ce sont tous deux d'excellents frameworks pour créer des modèles d'apprentissage en profondeur. Lorsque vous entendez parler d'architectures de réseaux de neurones révolutionnaires pour la détection d'objets, la reconnaissance faciale, la génération de langage ou les chatbots, elles sont très probablement codées à l'aide des bibliothèques PyTorch ou Tensorflow.
Bibliothèques Python pour la visualisation des données
En plus de l'analyse et de la modélisation des données, Python est également un excellent outil de visualisation des données. Voici quelques-unes des bibliothèques Python les plus populaires qui peuvent vous aider à créer des visualisations de données significatives, informatives, interactives et attrayantes.
matplotlib
Il s'agit d'une bibliothèque standard pour générer des visualisations de données en Python . Il prend en charge la création de graphiques bidimensionnels de base tels que des tracés linéaires, des histogrammes, des nuages de points, des graphiques à barres et des graphiques à secteurs, ainsi que des visualisations animées et interactives plus complexes.
La bibliothèque matplotlib est également flexible en ce qui concerne le formatage et le style des tracés ; vous pouvez choisir comment afficher les étiquettes, les grilles, les légendes, etc. Cependant, un inconvénient majeur de matplotlib est qu'il oblige les data scientists à écrire beaucoup de code pour créer des graphiques complexes et visuellement attrayants.
Pour ceux qui souhaitent apprendre la visualisation de données avec matplotlib, je recommande de commencer par notre didacticiel en deux parties qui couvre les tracés linéaires et les histogrammes et les diagrammes à barres, les nuages de points, les diagrammes à piles et les graphiques à secteurs. Si vous travaillez avec des données de séries chronologiques, consultez ce guide pour les visualiser avec Python.
Enfin, matplotlib est également abordé dans notre cours d'introduction à Python pour la science des données, où vous pouvez vous entraîner à créer des tracés linéaires, des histogrammes et d'autres types de tracés.
né de la mer
Bien qu'elle ait été construite sur matplotlib, la bibliothèque seaborn a une interface de haut niveau qui permet aux utilisateurs de dessiner des graphiques statistiques attrayants et informatifs en seulement quelques lignes de code - ou une seule ligne de code ! Sa syntaxe concise et ses fonctionnalités avancées en font mon outil de visualisation préféré.
Grâce à une vaste collection de visualisations et un ensemble de thèmes intégrés , vous pouvez créer des tracés professionnels même si vous débutez dans le codage des visualisations de données. Tirez parti des fonctionnalités étendues de seaborn pour créer des cartes thermiques, des tracés de violon, des tracés conjoints, des grilles multi-tracés, etc.
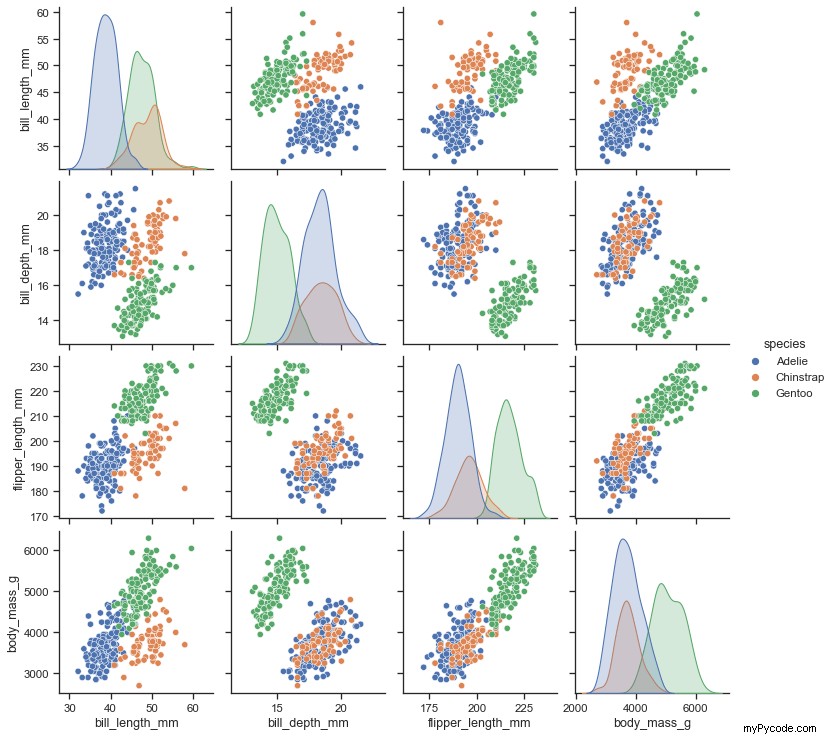
Exemple d'une matrice de nuage de points ( source )
Bokeh
Bokeh est un excellent outil pour créer des visualisations interactives dans les navigateurs . Comme Seaborn, il vous permet de construire des intrigues complexes à l'aide de commandes simples. Cependant, son objectif principal est l'interactivité.
Avec Bokeh, vous pouvez lier des tracés, afficher des données pertinentes tout en survolant des points de données spécifiques, intégrer différents widgets, etc. Ses capacités interactives étendues font de Bokeh un outil parfait pour créer des tableaux de bord, des graphiques de réseau et d'autres visualisations complexes.
Intrigue
Plotly est une autre bibliothèque de visualisation basée sur un navigateur . Il propose de nombreux graphiques utiles prêts à l'emploi, notamment :
- Tracés de base (par exemple, nuages de points, tracés linéaires, graphiques à barres, graphiques à secteurs, graphiques à bulles)
- Tracés statistiques (par exemple, barres d'erreur, boîtes à moustaches, histogrammes).
- Tracés scientifiques (par exemple, tracés de contour, cartes thermiques).
- Graphiques financiers (par exemple, séries chronologiques et graphiques en chandeliers).
- Cartes (par exemple, ajout de lignes, de zones remplies, de bulles et de cartes de densité à des cartes géographiques).
- Tracés 3D (par exemple, nuages de points, tracés de surface).
Envisagez d'utiliser Plotly si vous souhaitez créer des graphiques interactifs et de qualité publication.
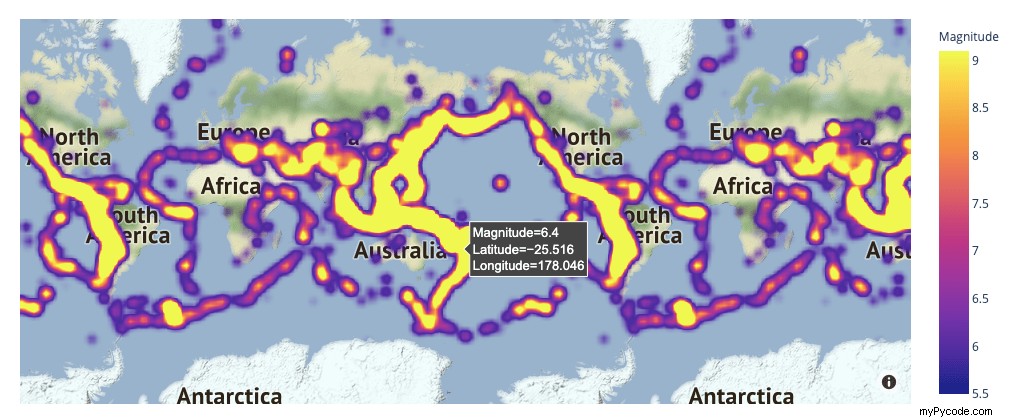
Exemple d'une carte thermique de densité mapbox avec Plotly ( source )
En savoir plus sur les bibliothèques de science des données de Python
Maintenant que vous avez été initié aux bibliothèques Python disponibles pour la science des données, ne leur soyez pas étranger ! Pour maîtriser vos compétences en science des données, vous aurez besoin de beaucoup de pratique. Je recommande de commencer par des cours interactifs, où une explication des concepts de base est combinée avec des défis de codage .
Notre cours d'introduction à Python pour la science des données est parfait pour les débutants qui souhaitent apprendre à effectuer une analyse de données simple à l'aide de Python. Il vous apprend à travailler avec des données tabulaires et à créer des graphiques de base avec quelques lignes de code.
Pour les passionnés de données qui souhaitent approfondir leurs connaissances, LearnPython.com a développé la mini-piste Python for Data Science. Il se compose de cinq cours qui couvrent l'importation et l'exportation de données dans différents formats, l'utilisation de chaînes en Python et les bases de l'analyse et de la visualisation des données. Cette piste est une excellente option pour une introduction en douceur au monde de la science des données.
Merci d'avoir lu et bon apprentissage !