Python est l'un des langages de programmation les plus fréquemment utilisés pour l'analyse des données financières, avec de nombreuses bibliothèques utiles et des fonctionnalités intégrées. Dans cet article, vous verrez comment les bibliothèques d'apprentissage automatique de Python peuvent être utilisées pour la prédiction de l'attrition des clients.
Désabonnement client est un terme financier qui fait référence à la perte d'un client ou d'un client, c'est-à-dire lorsqu'un client cesse d'interagir avec une entreprise ou une entreprise. De même, le taux de désabonnement est le taux auquel les clients ou les clients quittent une entreprise au cours d'une période de temps spécifique. Un taux de désabonnement supérieur à un certain seuil peut avoir des effets à la fois tangibles et intangibles sur le succès commercial d'une entreprise. Idéalement, les entreprises souhaitent fidéliser autant de clients que possible.
Avec l'avènement de la science des données avancées et des techniques d'apprentissage automatique, il est désormais possible pour les entreprises d'identifier les clients potentiels qui pourraient cesser de faire affaire avec elles dans un avenir proche. Dans cet article, vous verrez comment une banque peut prédire l'attrition des clients en fonction de différents attributs client tels que l'âge, le sexe, la géographie, etc. Les détails des fonctionnalités utilisées pour la prédiction de l'attrition des clients sont fournis dans une section ultérieure.
Présentation :Utilisation de Python pour la prévision de l'attrition des clients
Python est livré avec une variété de bibliothèques de science des données et d'apprentissage automatique qui peuvent être utilisées pour faire des prédictions basées sur différentes caractéristiques ou attributs d'un ensemble de données. La bibliothèque scikit-learn de Python est l'un de ces outils. Dans cet article, nous utiliserons cette bibliothèque pour la prédiction de l'attrition des clients.
L'ensemble de données :Modélisation du taux de désabonnement des clients bancaires
L'ensemble de données que vous utiliserez pour développer un modèle de prédiction de l'attrition des clients peut être téléchargé à partir de ce lien kaggle. Assurez-vous d'enregistrer le CSV sur votre disque dur.
En y regardant de plus près, nous constatons que l'ensemble de données contient 14 colonnes (également appelées caractéristiques ou variables ). Les 13 premières colonnes sont la variable indépendante, tandis que la dernière colonne est la variable dépendante qui contient une valeur binaire de 1 ou 0. Ici, 1 fait référence au cas où le client a quitté la banque après 6 mois, et 0 est le cas où le client n'a pas quitté la banque après 6 mois. C'est ce qu'on appelle un problème de classification binaire , où vous n'avez que deux valeurs possibles pour la variable dépendante. Dans ce cas, un client quitte la banque après 6 mois ou non.
Il est important de mentionner que les données pour les variables indépendantes ont été collectées 6 mois avant les données pour la variable dépendante, puisque la tâche est de développer un modèle d'apprentissage automatique qui peut prédire si un client quittera la banque après 6 mois, selon le valeurs de fonctionnalité actuelles.
Vous pouvez utiliser des algorithmes de classification d'apprentissage automatique pour résoudre ce problème.
Remarque : Tout le code de cet article est exécuté à l'aide de l'IDE Spyder pour Python.
Voici un aperçu des étapes que nous allons suivre dans cet article :
- Importer les bibliothèques
- Charger l'ensemble de données
- Sélectionner les fonctionnalités pertinentes
- Convertir des colonnes catégorielles en colonnes numériques
- Prétraiter les données
- Entraîner un algorithme de machine learning
- Évaluer l'algorithme de machine learning
- Évaluer les fonctionnalités de l'ensemble de données
Très bien, commençons !
Étape 1 :Importer les bibliothèques
La première étape, comme toujours, consiste à importer les bibliothèques requises. Exécutez le code suivant pour ce faire :
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Étape 2 :Charger l'ensemble de données
La deuxième étape consiste à charger le jeu de données à partir du fichier CSV local dans votre programme Python. Utilisons le read_csv méthode des pandas bibliothèque. Exécutez le code suivant :
customer_data = pd.read_csv(r'E:/Datasets/Churn_Modelling.csv')
Si vous ouvrez le customer_data dataframe dans le volet Variable Explorer de Spyder, vous devriez voir les colonnes comme indiqué ci-dessous :
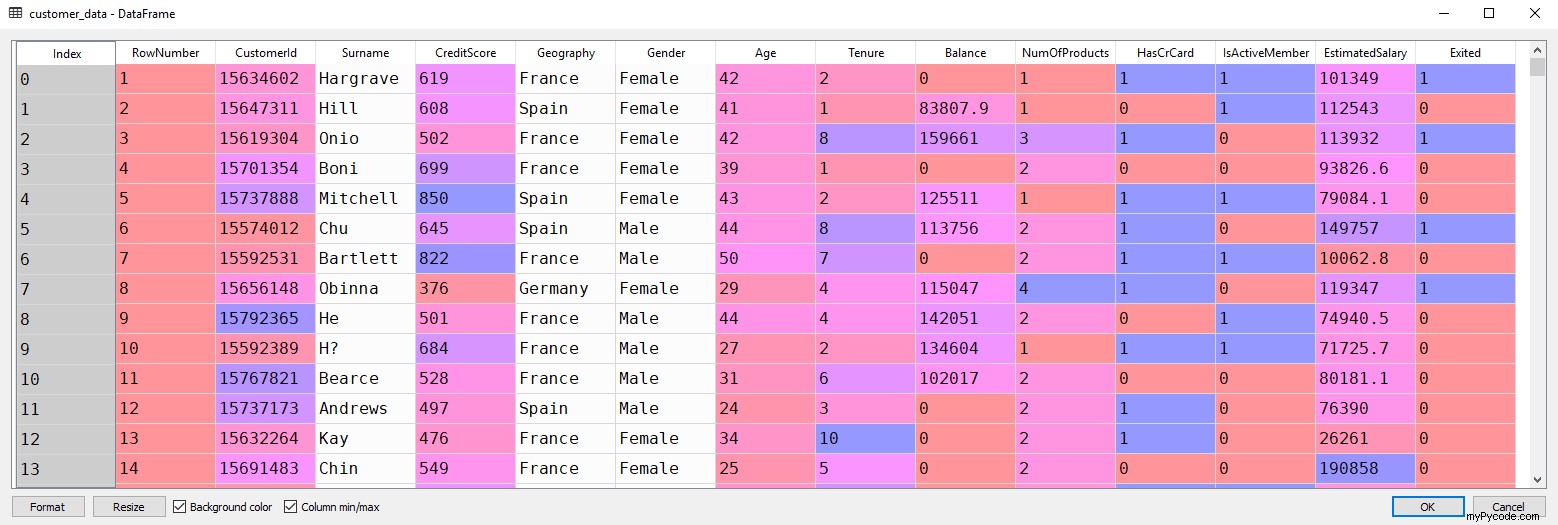
Étape 3 :Sélection des fonctionnalités
Pour rappel, il y a 14 colonnes au total dans notre jeu de données (voir la capture d'écran ci-dessus). Vous pouvez le vérifier en exécutant le code suivant :
columns = customer_data.columns.values.tolist() print(columns)
Dans la sortie, vous devriez voir la liste suivante :
['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited']
Toutes les colonnes n'affectent pas le taux de désabonnement des clients. Discutons de chaque colonne une par une :
RowNumber— correspond au numéro d'enregistrement (ligne) et n'a aucun effet sur la sortie. Cette colonne sera supprimée.CustomerId— contient des valeurs aléatoires et n'a aucun effet sur le client quittant la banque. Cette colonne sera supprimée.Surname—le nom de famille d'un client n'a aucune incidence sur sa décision de quitter la banque. Cette colonne sera supprimée.CreditScore— peut avoir un effet sur le taux de désabonnement des clients, car un client avec un pointage de crédit plus élevé est moins susceptible de quitter la banque.Geography— l'emplacement d'un client peut influer sur sa décision de quitter la banque. Nous conserverons cette colonne.Gender— il est intéressant d'explorer si le sexe joue un rôle dans le départ d'un client de la banque. Nous inclurons également cette colonne.Age— cela est certainement pertinent, puisque les clients plus âgés sont moins susceptibles de quitter leur banque que les plus jeunes.Tenure— fait référence au nombre d'années pendant lesquelles le client est client de la banque. Normalement, les clients plus âgés sont plus fidèles et moins susceptibles de quitter une banque.Balance— également un très bon indicateur du taux de désabonnement des clients, car les personnes dont le solde est plus élevé sont moins susceptibles de quitter la banque que celles dont le solde est moins élevé.NumOfProducts—fait référence au nombre de produits qu'un client a achetés par l'intermédiaire de la banque.HasCrCard— indique si un client possède ou non une carte de crédit. Cette colonne est également pertinente, car les personnes disposant d'une carte de crédit sont moins susceptibles de quitter la banque.IsActiveMember— les clients actifs sont moins susceptibles de quitter la banque, donc nous allons garder cela.EstimatedSalary— comme pour l'équilibre, les personnes ayant des salaires inférieurs sont plus susceptibles de quitter la banque que celles ayant des salaires plus élevés.Exited— que le client ait quitté la banque ou non. C'est ce que nous devons prévoir.
Après une observation attentive des fonctionnalités, nous supprimerons le RowNumber , CustomerId , et Surname colonnes de notre ensemble de fonctionnalités. Toutes les colonnes restantes contribuent au taux de désabonnement des clients d'une manière ou d'une autre.
Pour supprimer ces trois colonnes, exécutez le code suivant :
dataset = customer_data.drop(['RowNumber', 'CustomerId', 'Surname'], axis=1)
Notez ici que nous avons stocké nos données filtrées dans un nouveau bloc de données nommé dataset . Le customer_data le bloc de données contient toujours toutes les colonnes. Nous le réutiliserons plus tard.
Étape 4 :Conversion des colonnes catégorielles en colonnes numériques
Les algorithmes d'apprentissage automatique fonctionnent mieux avec des données numériques . Cependant, dans notre jeu de données, nous avons deux colonnes catégorielles :Geography et Gender . Ces deux colonnes contiennent des données au format textuel ; nous devons les convertir en colonnes numériques.
Isolons d'abord ces deux colonnes de notre jeu de données. Exécutez le code suivant pour ce faire :
dataset = dataset.drop(['Geography', 'Gender'], axis=1)
Une façon de convertir des colonnes catégorielles en colonnes numériques consiste à remplacer chaque catégorie par un nombre. Par exemple, dans le Gender colonne, le féminin peut être remplacé par 0 et le masculin par 1, ou vice versa. Cela fonctionne pour les colonnes avec seulement deux catégories.
Pour une colonne telle que Géographie avec trois catégories ou plus, vous pouvez utiliser les valeurs 0, 1 et 2 pour les trois pays que sont la France, l'Allemagne et l'Espagne. Cependant, si vous faites cela, les algorithmes d'apprentissage automatique supposeront qu'il existe une relation ordinale entre les trois pays. En d'autres termes, l'algorithme supposera que 2 est supérieur à 1 et 0, ce qui n'est en fait pas le cas en termes de pays sous-jacents que les chiffres représentent.
Une meilleure façon de convertir ces colonnes catégorielles en colonnes numériques consiste à utiliser le codage à chaud . Dans ce processus, nous prenons nos catégories (France, Allemagne, Espagne) et les représentons par des colonnes. Dans chaque colonne, nous utilisons un 1 pour indiquer que la catégorie existe pour la ligne actuelle, et un 0 sinon.
Dans ce cas, avec les trois catégories France, Allemagne et Espagne, nous pouvons représenter nos données catégorielles avec seulement deux colonnes (Allemagne et Espagne, par exemple). Pourquoi? Eh bien, si pour une ligne donnée, nous avons que la géographie est la France, alors les colonnes Allemagne et Espagne auront toutes deux un 0, ce qui implique que le pays doit être le pays restant non représenté par aucune colonne. Notez donc que nous n'avons pas réellement besoin d'une colonne distincte pour la France.
Convertissons les colonnes Géographie et Genre en colonnes numériques. Exécutez le script suivant :
Geography = pd.get_dummies(customer_data.Geography).iloc[:,1:] Gender = pd.get_dummies(customer_data.Gender).iloc[:,1:]
Le get_dummies méthode des pandas la bibliothèque convertit les colonnes catégorielles en colonnes numériques. Ensuite, .iloc[:,1:] ignore la première colonne et renvoie le reste des colonnes (Allemagne et Espagne). Comme indiqué ci-dessus, cela est dû au fait que nous pouvons toujours représenter "n" catégories avec "n - 1" colonnes.
Maintenant, si vous ouvrez le Geography et customer_data trames de données dans le volet Explorateur de variables, vous devriez voir quelque chose comme ceci :
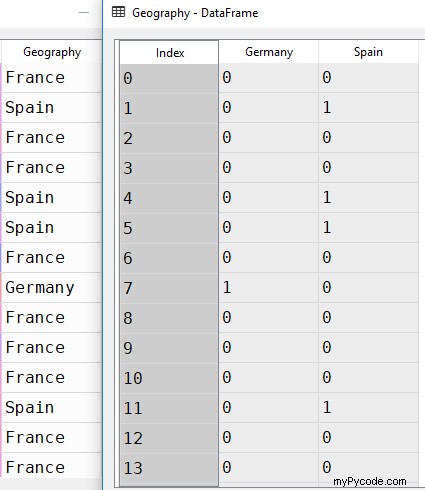
Conformément à notre explication précédente, le Geography le bloc de données contient deux colonnes au lieu de trois. Lorsque la géographie est la France, Germany et Spain contenir 0. Lorsque la géographie est l'Espagne, vous pouvez voir un 1 dans le Spain colonne et un 0 dans le Germany colonne. De même, dans le cas de Germany , vous pouvez voir un 1 dans le Germany colonne et un 0 dans le Spain colonne.
Ensuite, nous devons ajouter le Geography et Gender des trames de données vers l'ensemble de données pour créer l'ensemble de données final. Vous pouvez utiliser le concat fonction de pandas pour concaténer horizontalement deux blocs de données comme indiqué ci-dessous :
dataset = pd.concat([dataset,Geography,Gender], axis=1)
Étape 5 :Prétraitement des données
Nos données sont maintenant prêtes et nous pouvons former notre modèle d'apprentissage automatique. Mais d'abord, nous devons isoler la variable que nous prédisons à partir de l'ensemble de données.
X = dataset.drop(['Exited'], axis=1) y = dataset['Exited']
Ici, X est notre ensemble de fonctionnalités ; il contient toutes les colonnes sauf celle que nous devons prédire (Exited ). Le jeu d'étiquettes, y, contient uniquement le Exited colonne.
Afin que nous puissions ensuite évaluer les performances de notre modèle d'apprentissage automatique, divisons également les données en un ensemble d'entraînement et de test. L'ensemble de formation contient les données qui seront utilisées pour former notre modèle d'apprentissage automatique. L'ensemble de test sera utilisé pour évaluer la qualité de notre modèle. Nous utiliserons 20 % des données pour l'ensemble de test et les 80 % restants pour l'ensemble d'apprentissage (spécifié avec le test_size arguments):
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Étape 6 :Formation à l'algorithme d'apprentissage automatique
Nous allons maintenant utiliser un algorithme d'apprentissage automatique qui identifiera des modèles ou des tendances dans les données d'entraînement. Cette étape est connue sous le nom de formation d'algorithme . Nous alimenterons les fonctionnalités et corrigerons la sortie de l'algorithme ; sur la base de ces données, l'algorithme apprendra à trouver des associations entre les caractéristiques et les sorties. Après avoir formé l'algorithme, vous pourrez l'utiliser pour faire des prédictions sur de nouvelles données.
Il existe plusieurs algorithmes d'apprentissage automatique qui peuvent être utilisés pour faire de telles prédictions. Cependant, nous utiliserons l'algorithme de forêt aléatoire, car il est simple et l'un des algorithmes les plus puissants pour les problèmes de classification .
Pour former cet algorithme, nous appelons le fit méthode et transmettre l'ensemble de fonctionnalités (X) et l'ensemble d'étiquettes correspondant (y). Vous pouvez ensuite utiliser la méthode de prédiction pour faire des prédictions sur l'ensemble de test. Regardez le script suivant :
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=200, random_state=0) classifier.fit(X_train, y_train) predictions = classifier.predict(X_test)
Étape 7 :Évaluation de l'algorithme d'apprentissage automatique
Maintenant que l'algorithme a été formé, il est temps de voir comment il fonctionne. Pour évaluer les performances d'un algorithme de classification, les métriques les plus couramment utilisées sont la mesure F1, la précision, le rappel et l'exactitude. Dans la bibliothèque scikit-learn de Python, vous pouvez utiliser des fonctions intégrées pour trouver toutes ces valeurs. Exécutez le script suivant :
from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test,predictions )) print(accuracy_score(y_test, predictions ))
La sortie ressemble à ceci :
precision recall f1-score support
0 0.89 0.95 0.92 1595
1 0.73 0.51 0.60 405
avg / total 0.85 0.86 0.85 2000
0.8635
Les résultats indiquent une précision de 86,35 % , ce qui signifie que notre algorithme prédit avec succès l'attrition des clients 86,35 % du temps. C'est assez impressionnant pour un premier essai !
Étape 8 :Évaluation des fonctionnalités
Enfin, voyons quelles caractéristiques jouent le rôle le plus important dans l'identification de l'attrition des clients. Heureusement, RandomForestClassifier contient un attribut nommé feature_importance qui contient des informations sur les caractéristiques les plus importantes pour une classification donnée.
Le code suivant crée un graphique à barres des 10 principaux éléments permettant de prédire l'attrition des clients :
feat_importances = pd.Series(classifier.feature_importances_, index=X.columns) feat_importances.nlargest(10).plot(kind='barh')
Et la sortie ressemble à ceci :
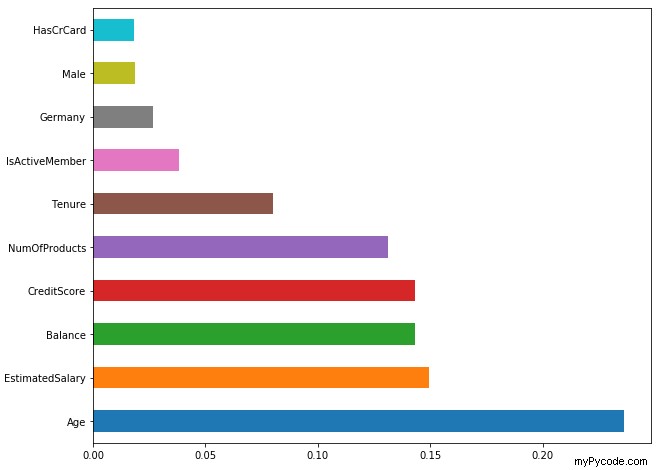
Sur la base de ces données, nous pouvons voir que l'âge a le plus grand impact sur le taux de désabonnement des clients, suivi par le salaire estimé d'un client et le solde du compte.
Conclusion
La prédiction de l'attrition des clients est cruciale pour la stabilité financière à long terme d'une entreprise. Dans cet article, vous avez réussi à créer un modèle d'apprentissage automatique capable de prédire l'attrition des clients avec une précision de 86,35 %. Vous pouvez voir à quel point il est facile et simple de créer un modèle d'apprentissage automatique pour les tâches de classification.
Vous souhaitez explorer d'autres applications de Python pour l'analyse de données financières ? Inscrivez-vous à notre cours Python Basics pour acquérir plus d'expérience pratique.

