Réponse courte :La manière la plus Pythonic de calculer la différence entre deux listes l1 et l2 est la déclaration de compréhension de liste [x for x in l1 if x not in set(l2)] . Cela fonctionne même si vous avez des entrées de liste en double, cela maintient l'ordre de liste d'origine et c'est efficace en raison de la complexité d'exécution constante de l'opération d'appartenance définie.
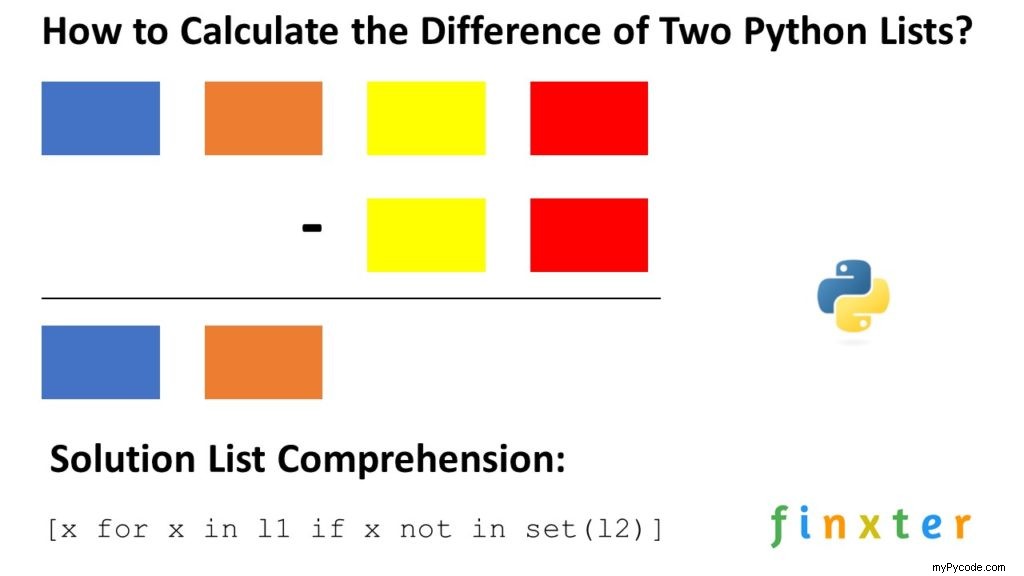
Quelle est la meilleure façon de calculer la différence entre deux listes en Python ?
a = [5, 4, 3, 2, 1] b = [4, 5, 6, 7] # a - b == [3, 2, 1] # b - a == [6, 7]
En Python, vous avez toujours plusieurs façons de résoudre le même problème (ou un problème similaire). Ayons un aperçu dans le shell de code interactif suivant :
Exercice :Exécutez le code et réfléchissez à votre méthode préférée !
Plongeons-nous dans chacune des méthodes pour trouver celle qui convient le mieux à votre scénario particulier.
Méthode 1 :Définir la différence
L'approche naïve pour résoudre ce problème consiste à convertir les deux listes en ensembles et à utiliser l'opération ensemble moins (ou ensemble différence).
# Method 1: Set Difference
print(set(a) - set(b))
# {1, 2, 3}
print(set(b) - set(a))
# {6, 7} Cette approche est élégante car elle est lisible, efficace et concise.
Cependant, cette méthode possède certaines propriétés uniques dont vous devez être conscient :
- Le résultat est un ensemble et non une liste. Vous pouvez le reconvertir en liste en utilisant le
list(...)constructeur. - Toutes les entrées de liste en double sont supprimées dans le processus car les ensembles ne peuvent pas avoir d'éléments en double.
- L'ordre de la liste d'origine est perdu car les ensembles ne conservent pas l'ordre des éléments.
Si les trois propriétés vous conviennent, c'est de loin l'approche la plus efficace telle qu'évaluée plus loin dans cet article !
Cependant, comment pouvez-vous conserver l'ordre des éléments de la liste d'origine tout en autorisant les doublons ? Plongeons-nous dans la compréhension de la liste alternative !
Méthode 2 :Compréhension de la liste
La compréhension de liste est une manière compacte de créer des listes. La formule simple est [expression + context] .
- Expression :Que faire de chaque élément de la liste ?
- Contexte :Quels éléments sélectionner ? Le contexte consiste en un nombre arbitraire de
foretifdéclarations.
Vous pouvez utiliser la compréhension de liste pour passer en revue tous les éléments de la première liste, mais les ignorer s'ils se trouvent dans la seconde liste :
# Method 2: List Comprehension print([x for x in a if x not in set(b)]) # [3, 2, 1]
Nous avons utilisé une optimisation petite mais efficace pour convertir la deuxième liste b à un ensemble d'abord. La raison en est que la vérification de l'appartenance x in b est beaucoup plus rapide pour les ensembles que pour les listes. Cependant, sémantiquement, les deux variantes sont identiques.
Voici les propriétés distinctives de cette approche :
- Le résultat de la déclaration de compréhension de liste est une liste.
- L'ordre de la liste d'origine est conservé.
- Les éléments en double sont conservés.
Si vous comptez sur ces garanties plus puissantes, utilisez l'approche de compréhension de liste car c'est la plus Pythonique.
Méthode 3 :boucle for simple
Étonnamment, certains tutoriels en ligne recommandent d'utiliser une boucle for imbriquée (par exemple, ces gars-là) :
# Method 3: Nested For Loop
d = []
for x in a:
if x not in b:
d.append(x)
print(d)
# [3, 2, 1]
À mon avis, cette approche ne serait utilisée que par des débutants absolus ou des codeurs qui viennent d'autres langages de programmation tels que C++ ou Java et ne connaissent pas les fonctionnalités Python essentielles comme la list comprehension . Vous pouvez optimiser cette méthode en convertissant la liste b à un ensemble d'abord pour accélérer la vérification if x not in b par une marge non négligeable.
Évaluation des performances
Vous voulez connaître le plus performant ? Dans ce qui suit, j'ai testé trois approches différentes :
import timeit
init = 'l1 = list(range(100)); l2 = list(range(50))'
# 1. Set Conversion
print(timeit.timeit('list(set(l1) - set(l2))', init, number = 10000))
# 2. List Comprehension
print(timeit.timeit('[x for x in l1 if x not in l2]', init, number = 10000))
# 3. List Comprehension + set
print(timeit.timeit('s = set(l2);[x for x in l1 if x not in s]', init, number = 10000))
'''
0.1620231000000001
0.5186101000000001
0.057180300000000184
''' Vous pouvez exécuter le code dans notre shell Python interactif :
Exercice :Exécutez le code. Lequel est le plus rapide et pourquoi ?
Bien que la première approche semble être la plus rapide, vous savez maintenant qu'elle présente également certains inconvénients. (Perd les informations en double, perd les informations de commande.) Parmi les deux approches de compréhension de liste, la seconde tue la première en termes de complexité d'exécution et de performances !

