Résumé : Le UnicodeEncodeError se produit généralement lors de l'encodage d'une chaîne Unicode dans un certain codage. Seul un nombre limité de caractères Unicode sont mappés aux chaînes. Ainsi, tout caractère non représenté / mappé entraînera l'échec de l'encodage et déclenchera UnicodeEncodeError. Pour éviter cette erreur, utilisez le encode(utf-8 ) et décoder(utf-8 ) fonctionne en conséquence dans votre code.
Vous utilisez peut-être la gestion d'un code d'application qui doit traiter des données multilingues ou du contenu Web contenant de nombreux emojis et symboles spéciaux. Dans de telles situations, vous rencontrerez peut-être de nombreux problèmes liés aux données Unicode. Mais python a des options bien définies pour gérer les caractères Unicode et nous en discuterons dans cet article.
Qu'est-ce que Unicode ? ?
Unicode est une norme qui facilite le codage des caractères à l'aide d'un codage à bits variables. Je suis sûr que vous devez avoir entendu parler d'ASCII si vous êtes dans le monde de la programmation informatique. ASCII représente 128 caractères alors que Unicode en définit 2
21
personnages. Ainsi, Unicode peut être considéré comme un sur-ensemble d'ASCII. Si vous souhaitez avoir un aperçu approfondi d'Unicode, veuillez suivre ce lien.
Cliquez sur Unicode:- U+1F40D pour découvrir ce qu'il représente ! (Essayez-le !!!?)
Qu'est-ce qu'une UnicodeEncodeError ?
La meilleure façon de saisir un concept est de le visualiser avec un exemple. Alors regardons un exemple du UnicodeEncodeError .
u = 'é'
print("Integer value for é: ", ord(u))
print("Converting the encoded value of é to Integer Equivalent: ", chr(233))
print("UNICODE Representation of é: ", u.encode('utf-8'))
print("ASCII Representation of é: ", u.encode('ascii')) Sortie
Integer value for é: 233
Converting the encoded value of é to Integer Equivalent: é
UNICODE Representation of é: b'\xc3\xa9'
Traceback (most recent call last):
File "main.py", line 5, in <module>
print("ASCII Representation of é: ",u.encode('ascii'))
UnicodeEncodeError: 'ascii' codec can't encode character '\xe9' in position 0: ordinal not in range(128) Dans le code ci-dessus, lorsque nous avons essayé d'encoder le caractère é à sa valeur Unicode, nous avons obtenu une sortie mais en essayant de la convertir en équivalent ASCII, nous avons rencontré une erreur. L'erreur s'est produite car ASCII n'autorise que le codage 7 bits et ne peut pas représenter les caractères en dehors de la plage de [0..128].
Vous avez maintenant une idée de ce que le UnicodeEncodeError ressemble à. Avant de discuter de la manière dont nous pouvons éviter de telles erreurs, je pense qu'il est absolument nécessaire de discuter des concepts suivants :
Encodage et décodage
Le processus de conversion de données lisibles par l'homme dans un format spécifié, pour la transmission sécurisée de données, est appelé codage. Le décodage est l'opposé de l'encodage qui consiste à convertir les informations codées en texte normal (forme lisible par l'homme).
En Python,
encode()est une méthode intégrée utilisée pour l'encodage. Si aucun encodage n'est spécifié, UTF-8 est utilisé par défaut.decode()est une méthode intégrée utilisée pour le décodage.
Exemple :
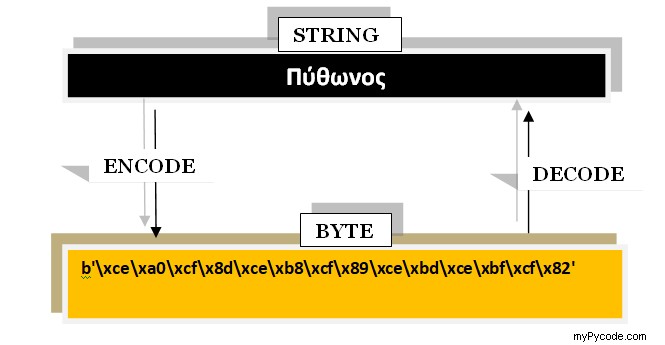
u = 'Πύθωνος'
print("UNICODE Representation of é: ", u.encode('utf-8')) Sortie :
UNICODE Representation of é: b'\xce\xa0\xcf\x8d\xce\xb8\xcf\x89\xce\xbd\xce\xbf\xcf\x82'
Le schéma suivant devrait faciliter un peu les choses :
Point de code
Unicode mappe le point de code à leurs caractères respectifs. Alors, qu'entendons-nous par un point de code ?
- Les points de code sont des valeurs numériques ou des nombres entiers utilisés pour représenter un caractère.
- Le point de code Unicode pour é est
U+00E9qui est l'entier 233. Lorsque vous encodez un caractère et que vous l'imprimez, vous obtiendrez généralement sa représentation hexadécimale en sortie au lieu de son équivalent binaire (comme on le voit dans les exemples ci-dessus). - La séquence d'octets d'un point de code est différente selon les schémas de codage. Par exemple :la séquence d'octets pour é dans
UTF-8est\xc3\xa9enUTF-16est \xff\xfe\xe9\x00.
Veuillez consulter le programme suivant pour mieux comprendre ce concept :
u = 'é'
print("INTEGER value for é: ", ord(u))
print("ENCODED Representation of é in UTF-8: ", u.encode('utf-8'))
print("ENCODED Representation of é in UTF-16: ", u.encode('utf-16')) Sortie
INTEGER value for é: 233 ENCODED Representation of é in UTF-8: b'\xc3\xa9' ENCODED Representation of é in UTF-16: b'\xff\xfe\xe9\x00'
Maintenant que nous avons un aperçu d'Unicode et UnicodeEncodeError , discutons de la manière dont nous pouvons gérer l'erreur et l'éviter dans notre programme.
➥ Problème : Étant donné une chaîne/texte à écrire dans un fichier texte ; comment éviter l'UnicodeEncodeError et écrire le texte donné dans le fichier texte.
Exemple :
f = open('demo.txt', 'w')
f.write('να έχεις μια όμορφη μέρα')
f.close() Sortie :
Traceback (most recent call last):
File "uniError.py", line 2, in <module>
f.write('να έχεις μια όμορφη μέρα')
File "C:\Users\Shubham-PC\AppData\Local\Programs\Python\Python38-32\lib\encodings\cp1252.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-1: character maps to <undefined> ✨ Solution 1 :Encoder la chaîne avant d'écrire dans le fichier et la décoder pendant la lecture
Vous ne pouvez pas écrire Unicode directement dans un fichier. Cela soulèvera un UnicodeEncodeError . Pour éviter cela, vous devez encoder la chaîne Unicode en utilisant le encode() fonction, puis écrivez-la dans le fichier comme indiqué dans le programme ci-dessous :
text = u'να έχεις μια όμορφη μέρα'
# write in binary mode to avoid TypeError
f = open('demo.txt', 'wb')
f.write(text.encode('utf8'))
f.close()
f = open('demo.txt', 'rb')
print(f.read().decode('utf8')) Sortie :
να έχεις μια όμορφη μέρα
✨ Solution 2 :Ouvrir le fichier en utf-8
Si vous utilisez Python 3 ou supérieur, il vous suffit d'ouvrir le fichier en utf-8 , car la gestion des chaînes Unicode est déjà normalisée dans Python 3.
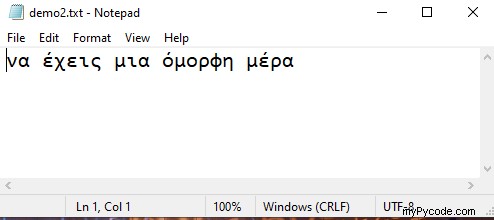
text = 'να έχεις μια όμορφη μέρα'
f = open('demo2.txt', 'w', encoding="utf-8")
f.write(text)
f.close() Sortie :
✨ Solution 3 :Utiliser le module de codecs
Une autre approche pour traiter le UnicodeEncodeError utilise le module de codecs.
Examinons le code suivant pour comprendre comment nous pouvons utiliser le module codecs :
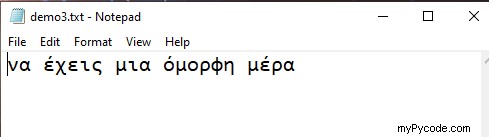
import codecs
f = codecs.open("demo3.txt", "w", encoding='utf-8')
f.write("να έχεις μια όμορφη μέρα")
f.close() Sortie :
✨ Solution 4 :Utiliser le module unicodecsv de Python
Si vous traitez des données Unicode et utilisez un csv fichier de gestion de vos données, puis le unicodecsv module peut être très utile. C'est une version étendue du csv de Python 2 module et aide l'utilisateur à gérer les données Unicode sans aucun problème.
Depuis le unicodecsv module ne fait pas partie de la bibliothèque standard de Python, vous devez l'installer avant de l'utiliser. Utilisez la commande suivante pour installer ce module :
$ pip install unicodecsv
Regardons l'exemple suivant pour mieux appréhender le unicodecsv modules :
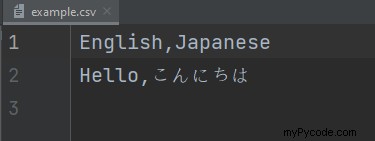
import unicodecsv as csv
with open('example.csv', 'wb') as f:
writer = csv.writer(f, encoding='utf-8')
writer.writerow(('English', 'Japanese'))
writer.writerow((u'Hello', u'こんにちは')) Sortie :
Conclusion
Dans cet article, nous avons discuté de certains des concepts importants concernant le caractère Unicode, puis nous nous sommes renseignés sur UnicodeEncodeError et avons enfin discuté des méthodes que nous pouvons utiliser pour l'éviter. J'espère qu'à la fin de cet article, vous pourrez gérer facilement les caractères Unicode dans votre code python.
Veuillez vous abonner et rester à l'écoute pour d'autres articles intéressants !