Présentation
Prétraitement des données est une technique utilisée pour transformer des données brutes en un format compréhensible. Les données brutes contiennent souvent de nombreuses erreurs (manquant de valeurs d'attribut ou de certains attributs ou ne contenant que des données agrégées) et manque de cohérence (contenant des divergences dans le code) et exhaustivité . C'est là que le prétraitement des données entre en jeu et fournit une méthode éprouvée pour résoudre ces problèmes.
Le prétraitement des données est cette étape de l'apprentissage automatique au cours de laquelle les données sont transformées ou encodées afin que la machine puisse facilement les lire et les analyser. En termes simples, les caractéristiques des données peuvent être facilement interprétées par l'algorithme après avoir subi un prétraitement des données.
Étapes impliquées dans le prétraitement des données dans l'apprentissage automatique
En matière d'apprentissage automatique, le prétraitement des données comprend les six étapes suivantes :
- Importation des bibliothèques nécessaires.
- Importation de l'ensemble de données.
- Vérifier et gérer les valeurs manquantes.
- Encodage des données catégorielles.
- Diviser l'ensemble de données en ensemble d'entraînement et ensemble de test.
- Mise à l'échelle des fonctionnalités.
Plongeons-nous profondément dans chaque étape une par une.
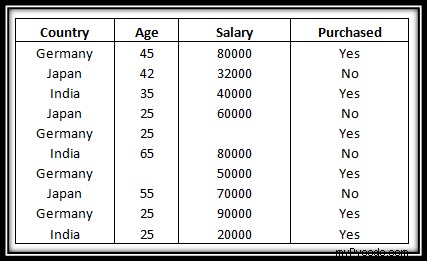
? Remarque : L'ensemble de données que nous utiliserons tout au long de ce didacticiel est répertorié ci-dessous.
❖ Importation des bibliothèques nécessaires
Python a une liste de bibliothèques et de modules incroyables qui nous aident dans le processus de prétraitement des données. Par conséquent, afin de mettre en œuvre le prétraitement des données, la première étape consiste à importer les bibliothèques nécessaires/requises.
Les bibliothèques que nous utiliserons dans ce tutoriel sont :
✨ NumPy
NumPy est une bibliothèque Python qui permet d'effectuer des calculs numériques. Pensez à l'algèbre linéaire à l'école (ou à l'université) - NumPy est la bibliothèque Python pour cela. Il s'agit de matrices et de vecteurs – et faire des opérations dessus. Au cœur de NumPy se trouve un type de données de base, appelé tableau NumPy.
Pour en savoir plus sur la bibliothèque Numpy, veuillez consulter notre tutoriel ici.
✨ Pandas
La bibliothèque Pandas est le bloc de construction de haut niveau fondamental pour effectuer une analyse de données pratique et réelle en Python. La bibliothèque Pandas nous permettra non seulement d'importer les ensembles de données, mais également de créer la matrice des caractéristiques et le vecteur variable dépendant.
Vous pouvez vous référer à notre playlist ici qui contient de nombreux tutoriels sur les bibliothèques Pandas.
✨ Matplotlib
La bibliothèque Matplotlib nous permet de tracer des graphiques impressionnants, ce qui est une exigence majeure en Machine Learning. Nous avons une liste complète de tutoriels sur la bibliothèque Matplotlib.
Veuillez consulter ce lien si vous voulez plonger profondément dans la bibliothèque Matplotlib.
Voyons donc comment nous pouvons importer ces bibliothèques dans le code ci-dessous :
import numpy as np import pandas as pd import matplotlib.pyplot as plt
❖ Importation de l'ensemble de données
Une fois que nous avons importé avec succès toutes les bibliothèques requises, nous devons ensuite importer le jeu de données requis . Pour cela, nous utiliserons la librairie pandas.
Remarque :
- Frames de données sont des objets de données bidimensionnels. Vous pouvez les considérer comme des tableaux avec des lignes et des colonnes contenant des données.
- La matrice des fonctionnalités est utilisé pour décrire la liste des colonnes contenant le indépendant variables à traiter et inclut toutes les lignes de l'ensemble de données donné.
- Le vecteur variable cible permet de définir la liste des dépendants variables dans l'ensemble de données existant.
- iloc est un indexeur pour le cadre de données Pandas qui est utilisé pour sélectionner des lignes et des colonnes en fonction de leur emplacement/position/index.
Voyons maintenant comment nous pouvons importer l'ensemble de données en utilisant les concepts que nous avons appris ci-dessus.
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:,:-1].values
y = dataset.iloc[:,-1].values
print(x)
print(y) Sortie :
[['Germany' 45.0 80000.0] ['Japan' 42.0 32000.0] ['India' 35.0 40000.0] ['Japan' 25.0 60000.0] ['Germany' 25.0 nan] ['India' 65.0 80000.0] ['Germany' nan 50000.0] ['Japan' 55.0 70000.0] ['Germany' 25.0 90000.0] ['India' 25.0 20000.0]] ['Yes' 'No' 'Yes' 'No' 'Yes' 'No' 'No' 'No' 'Yes' 'Yes']
❖ Vérification des valeurs manquantes
Lorsque nous traitons des ensembles de données, nous rencontrons souvent des valeurs manquantes qui peuvent conduire à des déductions incorrectes. Il est donc très important de gérer les valeurs manquantes.
Il existe plusieurs façons de gérer les données manquantes.
Méthode 1 : Supprimer la ligne particulière contenant une valeur nulle
Cette méthode doit être utilisée uniquement lorsque l'ensemble de données contient de nombreuses valeurs, ce qui garantit que la suppression d'une seule ligne n'affectera pas le résultat. Cependant, cela ne convient pas lorsque l'ensemble de données n'est pas énorme ou si le nombre de valeurs nulles/manquantes est important.
Méthode 2 :Remplacement de la valeur manquante par la moyenne, le mode ou la médiane
Cette stratégie est particulièrement adaptée aux entités contenant des données numériques. Nous pouvons simplement calculer la moyenne, la médiane ou le mode de la caractéristique, puis remplacer les valeurs manquantes par la valeur calculée. Dans notre cas, nous calculerons la moyenne pour remplacer les valeurs manquantes. Le remplacement des données manquantes par l'une des trois approximations ci-dessus est également connu sous le nom de fuite des données pendant l'entraînement.
➥ Pour traiter les valeurs manquantes, nous avons besoin de l'aide du SimpleImputer classe des scikit-learn bibliothèque.
✨ Remarque
- Le
fit()méthode prend les données d'apprentissage comme arguments, qui peuvent être un tableau dans le cas d'un apprentissage non supervisé ou deux tableaux dans le cas d'un apprentissage supervisé. -
transform
Maintenant que nous connaissons bien les bibliothèques, modules et fonctions nécessaires pour gérer les données manquantes dans notre ensemble de données, examinons le code ci-dessous pour comprendre comment nous pouvons traiter les données manquantes dans notre exemple de données. ensemble.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(x[:, 1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
print(x) Sortie :
[['Germany' 45.0 80000.0] ['Japan' 42.0 32000.0] ['India' 35.0 40000.0] ['Japan' 25.0 60000.0] ['Germany' 25.0 58000.0] ['India' 65.0 80000.0] ['Germany' 38.0 50000.0] ['Japan' 55.0 70000.0] ['Germany' 25.0 90000.0] ['India' 25.0 20000.0]]
❖ Encodage des données catégorielles
Toutes les variables d'entrée et de sortie doivent être numériques dans les modèles d'apprentissage automatique, car elles sont basées sur des équations mathématiques. Par conséquent, si les données contiennent des données catégorielles, elles doivent être encodées en nombres.
➥ Les données catégorielles représentent les valeurs de l'ensemble de données qui ne sont pas numériques.
Les trois approches les plus courantes pour convertir des variables catégorielles en valeurs numériques sont :
- Encodage ordinal
- Codage à chaud
- Codage de variable factice
Dans cet article, nous utiliserons le encodage One-Hot à encoder et le LabelEncoder classe pour encoder les données catégorielles.
✨ Encodage à chaud
Un encodage à chaud prend une colonne contenant des données catégorielles, puis divise la colonne en plusieurs colonnes. Selon quelle colonne a quelle valeur, ils sont remplacés par des 1 et des 0.
Dans notre exemple, nous obtiendrons trois nouvelles colonnes, une pour chaque pays :l'Inde, l'Allemagne et le Japon. Pour les lignes dont la première valeur de colonne est Allemagne, la colonne "Allemagne" sera divisée en trois colonnes de sorte que la première colonne aura "1" et les deux autres colonnes auront des "0". De même, pour les lignes dont la valeur de la première colonne est l'Inde, la deuxième colonne aura "1" et les deux autres colonnes auront des "0". Et pour les lignes dont la valeur de la première colonne est Japon, la troisième colonne aura "1" et les deux autres colonnes auront des "0".
➥ Pour implémenter One-Hot Encoding nous avons besoin de l'aide du OneHotEncoder classe du scikit-learn preprocessing des bibliothèques module et le ColumnTransformer classe du compose
✨ Encodage des étiquettes
Dans l'encodage des étiquettes, nous convertissons les valeurs non numériques en un nombre. Par exemple, dans notre cas, la dernière colonne se compose de Oui et Non valeurs. Nous pouvons donc utiliser le codage des étiquettes pour nous assurer que chaque Non est converti en 0, tandis que chaque Oui est converti en 1.
Appliquons les concepts ci-dessus et encodons notre ensemble de données pour traiter les données catégorielles. Veuillez suivre le code ci-dessous :
# import the necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
# import data set
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(x[:, 1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
x = np.array(ct.fit_transform(x))
le = LabelEncoder()
y = le.fit_transform(y)
print("Matrix of features:")
print(x)
print("Dependent Variable Vector: ")
print(y) Sortie :
Matrix of features: [[1.0 0.0 0.0 45.0 80000.0] [0.0 0.0 1.0 42.0 32000.0] [0.0 1.0 0.0 35.0 40000.0] [0.0 0.0 1.0 25.0 60000.0] [1.0 0.0 0.0 25.0 58000.0] [0.0 1.0 0.0 65.0 80000.0] [1.0 0.0 0.0 38.0 50000.0] [0.0 0.0 1.0 55.0 70000.0] [1.0 0.0 0.0 25.0 90000.0] [0.0 1.0 0.0 25.0 20000.0]] Dependent Variable Vector: [1 0 1 0 1 0 1 0 1 1]
❖ Diviser l'ensemble de données en ensemble d'apprentissage et en ensemble de test
Après avoir traité les données manquantes et les données catégorielles, l'étape suivante consiste à diviser l'ensemble de données en :
- Ensemble d'entraînement : Un sous-ensemble de l'ensemble de données utilisé pour entraîner le modèle de machine learning.
- Ensemble de test : Un sous-ensemble de l'ensemble de données utilisé pour tester le modèle d'apprentissage automatique.
Vous pouvez découper l'ensemble de données comme indiqué dans le diagramme ci-dessous :

Il est très important de diviser correctement l'ensemble de données en ensemble d'apprentissage et en ensemble de test. Généralement, c'est une bonne idée de diviser l'ensemble de données dans un rapport de 80:20 de sorte que 80 % des données se trouvent dans l'ensemble d'apprentissage et 30 % des données dans l'ensemble de test. Cependant, le fractionnement peut varier en fonction de la taille et de la forme de l'ensemble de données.
Attention : Ne vous entraînez jamais sur des données de test. Par exemple, si nous avons un modèle qui est utilisé pour prédire si un e-mail est un spam et qu'il utilise le sujet, le corps de l'e-mail et l'adresse de l'expéditeur comme fonctionnalités et que nous divisons l'ensemble de données en ensemble d'apprentissage et en ensemble de test dans un rapport de répartition de 80-20 puis après l'entraînement, le modèle atteint une précision de 99 % sur les deux, c'est-à-dire l'ensemble d'entraînement ainsi que l'ensemble de test. Normalement, nous nous attendrions à une précision inférieure pour l'ensemble de test. Ainsi, une fois que nous examinons à nouveau les données, nous découvrons que de nombreux exemples dans l'ensemble de test sont de simples doublons d'exemples dans l'ensemble d'apprentissage parce que nous avons négligé les entrées en double pour le même courrier indésirable. Par conséquent, nous ne pouvons pas mesurer avec précision la manière dont notre modèle réagit aux nouvelles données.
Maintenant que nous connaissons les deux ensembles dont nous avons besoin, examinons le code suivant qui montre comment nous pouvons le faire :
# import the necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
# import data set
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(x[:, 1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
x = np.array(ct.fit_transform(x))
le = LabelEncoder()
y = le.fit_transform(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
print("X Training Set")
print(x_train)
print("X Test Set")
print(x_test)
print("Y Training Set")
print(y_train)
print("Y Test Set")
print(y_test) Sortie :
X Training Set [[1.0 0.0 0.0 38.0 50000.0] [1.0 0.0 0.0 25.0 58000.0] [1.0 0.0 0.0 45.0 80000.0] [0.0 0.0 1.0 25.0 60000.0] [0.0 0.0 1.0 42.0 32000.0] [0.0 0.0 1.0 55.0 70000.0] [1.0 0.0 0.0 25.0 90000.0] [0.0 1.0 0.0 65.0 80000.0]] X Test Set [[0.0 1.0 0.0 35.0 40000.0] [0.0 1.0 0.0 25.0 20000.0]] Y Training Set [1 1 1 0 0 0 1 0] Y Test Set [1 1]
Explication :
train_test_split()La fonction nous permet de diviser l'ensemble de données en quatre sous-ensembles, deux pour la matrice de caractéristiquesxc'est-à-direx_trainetx_testet deux pour la variable dépendanteyc'est-à-direy_trainety_test.x_train:matrice de fonctionnalités pour les données d'entraînement.x_test:matrice de fonctionnalités pour tester les données.y_train:Variables dépendantes pour les données d'entraînement.y_test:Variable indépendante pour tester les données.
- Il contient également quatre paramètres, tels que :
- les deux premiers arguments sont pour les tableaux de données.
test_sizesert à spécifier la taille de l'ensemble de test.random_stateest utilisé pour fixer la valeur d'une graine pour un générateur aléatoire afin d'obtenir toujours le même résultat.
❖ Mise à l'échelle des fonctionnalités
La mise à l'échelle des fonctionnalités marque la dernière étape du prétraitement des données. Alors, qu'est-ce que la mise à l'échelle des fonctionnalités ? C'est la technique pour standardiser ou normaliser les variables indépendantes ou les caractéristiques de l'ensemble de données dans une plage spécifique. Ainsi, la mise à l'échelle des fonctionnalités nous permet de mettre à l'échelle les variables dans une plage spécifique afin qu'une variable particulière ne domine pas une autre variable.
La mise à l'échelle des fonctionnalités peut être effectuée de deux manières :
➊ Normalisation
La formule de standardisation est donnée ci-dessous :

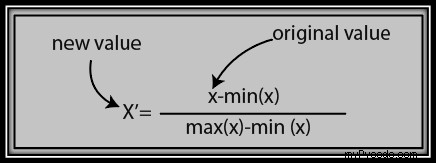
➋ Normalisation
La formule de normalisation est donnée ci-dessous :
L'une des questions les plus fréquemment posées par les scientifiques des données est :"Devrons-nous utiliser la standardisation ou la normalisation pour la mise à l'échelle des fonctionnalités ?"
Réponse : Le choix d'utiliser la normalisation ou la standardisation dépend entièrement du problème et de l'algorithme utilisé. Il n'y a pas de règles strictes pour décider quand normaliser ou normaliser les données.
- La normalisation est bonne pour la distribution des données lorsqu'elle ne suit pas une distribution gaussienne. Par exemple, les algorithmes qui ne supposent aucune distribution des données comme K-Nearest Neighbors et Neural Networks.
- Alors que la normalisation est utile dans les scénarios où la distribution des données suit une distribution gaussienne. Cependant, ce n'est pas une règle obligatoire.
- Contrairement à la normalisation, la normalisation n'a pas de plage de délimitation. Ainsi, même si les données comportent des valeurs aberrantes, la normalisation ne les affectera pas.
Dans notre exemple, nous allons utiliser la technique de standardisation. Examinons le code suivant pour comprendre comment implémenter la mise à l'échelle des fonctionnalités sur notre ensemble de données.
# import the necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
# import data set
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(x[:, 1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
x = np.array(ct.fit_transform(x))
le = LabelEncoder()
y = le.fit_transform(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
sc = StandardScaler()
x_train[:, 3:] = sc.fit_transform(x_train[:, 3:])
x_test[:, 3:] = sc.transform(x_test[:, 3:])
print("Feature Scaling X_train: ")
print(x_train)
print("Feature Scaling X_test")
print(x_test) Sortie :
Feature Scaling X_train: [[1.0 0.0 0.0 -0.1433148727800037 -0.8505719656856141] [1.0 0.0 0.0 -1.074861545850028 -0.39693358398661993] [1.0 0.0 0.0 0.3582871819500093 0.8505719656856141] [0.0 0.0 1.0 -1.074861545850028 -0.2835239885618714] [0.0 0.0 1.0 0.1433148727800037 -1.8712583245083512] [0.0 0.0 1.0 1.074861545850028 0.2835239885618714] [1.0 0.0 0.0 -1.074861545850028 1.4176199428093568] [0.0 1.0 0.0 1.7914359097500465 0.8505719656856141]] Feature Scaling X_test [[0.0 1.0 0.0 -0.3582871819500093 -1.4176199428093568] [0.0 1.0 0.0 -1.074861545850028 -2.5517158970568423]]
Explication :
- Au départ, nous devons importer le
StandardScalerclasse duscikit-learnbibliothèque en utilisant la ligne de code suivante :from sklearn.preprocessing import StandardScaler
- Ensuite, nous créons l'objet de la classe StandardScaler.
sc = StandardScaler()
- Après cela, nous ajustons et transformons l'ensemble de données d'entraînement à l'aide du code suivant :
x_train[:, 3:] = sc.fit_transform(x_train[:, 3:])
- Enfin, nous transformons l'ensemble de données de test à l'aide du code suivant :
x_test[:, 3:] = sc.transform(x_train[:, 3:])
Conclusion
Toutes nos félicitations! Vous avez maintenant tous les outils dans votre arsenal pour effectuer le prétraitement des données. Veuillez vous abonner et cliquez sur le lien ci-dessous pour passer à la section suivante de notre tutoriel Machine Learning !