Présentation
La régression est une technique d'apprentissage supervisé qui définit la relation entre une variable dépendante et la ou les variables indépendantes. Les modèles de régression décrivent la relation entre les variables dépendantes et indépendantes à l'aide d'une ligne d'ajustement . Dans le cas des modèles de régression linéaire, il s'agit d'une ligne droite tandis que dans le cas des modèles de régression logistique et non linéaire, une courbe ligne est utilisé.
Régression linéaire simple est une technique d'analyse prédictive pour estimer la relation entre les variables quantitatives. Vous pouvez utiliser la régression linéaire simple dans les scénarios suivants :
- Pour déterminer la force de la relation entre deux variables.
- Pour déterminer la valeur d'une variable dépendante correspondant à une certaine valeur d'une/des variable(s) indépendante(s).
Exemple
Une illustration très populaire de l'économétrie qui utilise une régression linéaire simple consiste à trouver la relation entre la consommation et le revenu. Lorsque le revenu augmente, la consommation augmente et vice-versa. La variable indépendante – income et la variable dépendante – consumption sont tous deux quantitatifs, vous pouvez donc effectuer une analyse de régression pour savoir s'il existe une relation linéaire entre eux.
Avant de plonger, comprenons quelques-uns des principaux concepts nécessaires pour faire face à l'analyse de régression.
❂ Variables quantitatives : Les données qui représentent des montants/valeurs numériques sont appelées données quantitatives. Une variable qui contient des données quantitatives est appelée variable quantitative. Il existe deux types de variables quantitatives :(i) discret et (ii) continu.
❂ Variable catégorielle : Ce sont les variables qui représentent la classification ou le regroupement d'un certain type. Les données catégorielles peuvent être de trois types :(i) Binaire, (ii) Nominal, (iii) Ordinal
❂ Variable dépendante : Variable contenant des données qui dépendent d'une autre variable. Vous ne pouvez pas contrôler directement les données d'une variable dépendante.
❂ Variable indépendante : Variable contenant des données dont l'existence ne dépend pas d'autres variables. Vous pouvez contrôler directement les données d'une variable indépendante.
❂ Modèle : Un modèle de données est un moteur de transformation utilisé pour exprimer des variables dépendantes en fonction de variables indépendantes.
Représentation mathématique de la régression linéaire
?? Pouvez-vous rappeler la leçon de lycée sur la géométrie? Vous souvenez-vous, l'équation d'une droite ?

Maintenant, la régression linéaire n'est qu'un exemple de cette équation. Ici,
- y désigne la variable qui doit être prédite. Il s'agit donc de la variable dépendante.
- La valeur dey dépend de la valeur de x . Ainsi, x est l'entrée et la variable indépendante.
- m dénote la pente et donne l'angle de la ligne. C'est donc le paramètre.
- c désigne l'interception. Ainsi, c'est la constante qui détermine quelle sera la valeur de y quand x est 0 .
Examinons maintenant l'équation mathématique qui représente la régression linéaire simple :
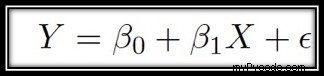
Où,
β0 ➝ Interception de la droite de régression .
β1 ➝ Pente de la droite de régression.
ε ➝ Le terme d'erreur.
Remarque :Le modèle de régression linéaire n'est pas toujours parfait. Il se rapproche de la relation entre les variables dépendantes et indépendantes et l'approximation conduit souvent à des erreurs. Certaines erreurs peuvent être réduites tandis que d'autres sont inhérentes au problème et ne peuvent pas être éliminées. Les erreurs qui ne peuvent pas être éliminées sont appelées erreur irréductible .
Implémentation de la régression linéaire simple en Python
Jetons un coup d'œil à un exemple pour visualiser comment implémenter une régression linéaire simple en Python. L'ensemble de données qui sera utilisé dans notre exemple est mentionné ci-dessous.
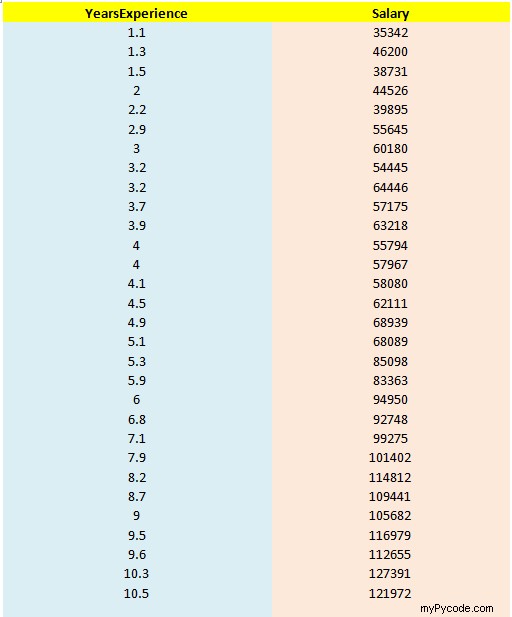 Téléchargement de données
Téléchargement de données ❂ L'énoncé du problème : Le jeu de données utilisé dans notre exemple a été mentionné ci-dessus tel que :
- Le salaire représente la variable dépendante .
- Les années d'expérience représentent la variable indépendante.
Objectifs :
- Trouvez une corrélation entre le salaire et les années d'expérience. Par conséquent, nous observons comment la variable dépendante change lorsque la variable indépendante change.
- Trouvez la ligne la mieux ajustée.
Remarque : La ligne de meilleur ajustement est la ligne passant par un nuage de points de points de données qui exprime le mieux la relation entre ces points. (voir :Ligne de meilleur ajustement)
Plongeons-nous dans les étapes de mise en œuvre de la régression linéaire simple.
? Étape 1 :Prétraitement des données
La première et principale étape est le prétraitement des données. Nous avons déjà discuté et appris sur le prétraitement des données ; si vous souhaitez maîtriser les notions de pré-traitement des données merci de vous référer à l'article sur ce lien. Passons rapidement en revue les étapes nécessaires au prétraitement de nos données :
❇ Importer les bibliothèques nécessaires
import numpy as np import pandas as pd import matplotlib.pyplot as plt
❇ Importer l'ensemble de données
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values ❇ Diviser l'ensemble de données en ensemble d'apprentissage et en ensemble de test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
Remarque : Veuillez vous référer au didacticiel de prétraitement des données pour comprendre le concept derrière chaque extrait mentionné ci-dessus.
? Étape 2 :Entraîner le modèle de régression linéaire simple à l'aide de l'ensemble d'entraînement
Après avoir terminé le prétraitement des données, vous devez former le modèle à l'aide de l'ensemble de formation comme indiqué ci-dessous.
from sklearn.linear_model import LinearRegression regression_obj = LinearRegression() regression_obj.fit(x_train, y_train)
Explication :
- Importer la régression linéaire classe du linear_model bibliothèque du scikit-learn bibliothèque.
- Créer un objet
regression_obj. - Utilisez le
fit()afin d'adapter le modèle de régression linéaire simple à l'ensemble d'apprentissage afin que le modèle soit capable d'apprendre et d'identifier les corrélations entre les variables. Pour ce faire, vous devez passer x_train et y_train (qui représentent les variables indépendantes et dépendantes de l'ensemble d'apprentissage) dans lefit()méthode.
? Étape 3 :Prédire les résultats des tests
Après avoir subi la phase de formation, notre modèle est maintenant prêt à prédire les sorties en fonction de nouvelles observations. Par conséquent, vous devez maintenant alimenter le jeu de données de test avec le modèle et tester si le modèle est capable de prédire les sorties correctes. Examinons le code ci-dessous pour comprendre comment nous pouvons vérifier l'efficacité de notre modèle pour prédire les sorties.
y_predicted = regression_obj.predict(x_test)
Explication :
y_predictedcontient les sorties prédites dex_test(jeu de données de test). La fonction predict() renvoie les données étiquetées (sorties prédites).
? Étape 4 :Tracer et visualiser les résultats de l'ensemble d'entraînement
Il est temps pour vous de visualiser les résultats produits par le modèle en fonction des entrées de l'ensemble d'apprentissage. Cela peut être fait à l'aide du pyplot module. Mais, avant de plonger dans le code, discutons des concepts nécessaires à l'exécution de notre code.
✨ Qu'est-ce qu'un nuage de points ?
En termes simples et clairs, vous pouvez visualiser un nuage de points sous la forme d'un diagramme dans lequel les valeurs de l'ensemble de données sont représentées par des points. La méthode utilisée pour dessiner un nuage de points est connue sous le nom de scatter() . Nous pouvons également définir la couleur des points à l'aide du color attribut dans le scatter fonction. Dans le scatter fonction, nous passerons les valeurs de l'ensemble d'entraînement, c'est-à-dire x_train (années d'expérience) et y_train (l'ensemble des salaires).
Le diagramme suivant représente un nuage de points :
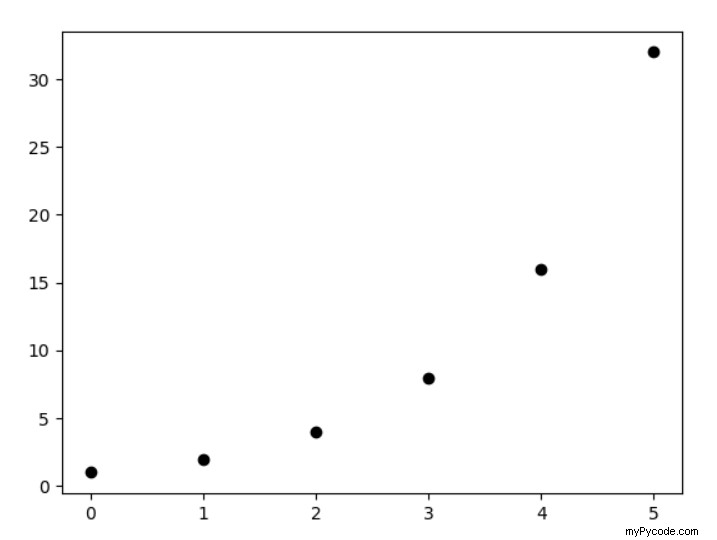
Vous plongez profondément dans les nuages de points dans notre tutoriel de blog ici ? .
✨ Le plot() La fonction nous permet de dessiner des points/marqueurs dans un diagramme et par défaut, elle trace une ligne d'un point à un autre. Nous allons utiliser cette fonction pour tracer notre droite de régression en passant x_train (années d'expérience), salaire prédit de l'ensemble de formation et couleur de la ligne.
✨ xlabel() et ylabel() les fonctions sont utilisées pour définir l'axe des x (années d'expérience) et l'axe des y (salaire) du nuage de points tandis que title() La méthode nous permet de définir le titre du nuage de points. Le show() affiche les chiffres/graphiques et vous aide à visualiser le résultat.
Examinons maintenant le code qui illustre l'explication ci-dessus :
plt.scatter(x_train, y_train, color = 'red')
plt.plot(x_train, regression_obj.predict(x_train), color = 'green')
plt.title('Salary vs Experience for Training set')
plt.xlabel('Experience (in Years)')
plt.ylabel('Salary')
plt.show() Sortie :
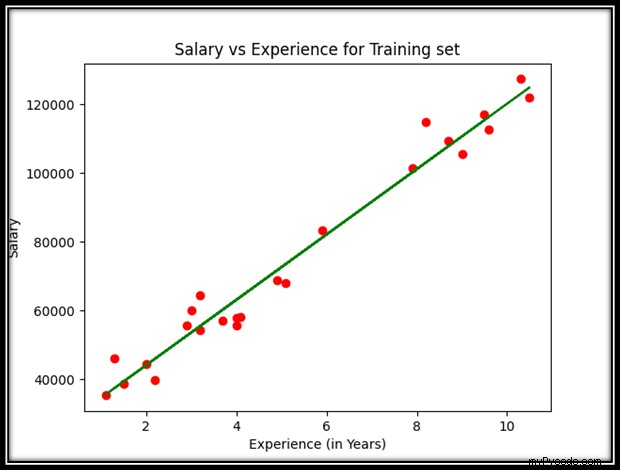
? Étape 5 :Tracer et visualiser les résultats de l'ensemble de tests
Auparavant, nous avons vérifié et visualisé l'efficacité et les performances de notre modèle en fonction de l'ensemble d'apprentissage. Il est maintenant temps de visualiser la sortie de l'ensemble de test. Tout ce qui est expliqué à l'étape 4 s'applique également à cette étape, sauf qu'au lieu d'utiliser x_train et y_train nous utiliserons x_test et y_test dans ce cas.
(Remarque :les couleurs utilisées dans ce cas sont différentes. Mais ceci est facultatif.)
# Visualizing the Test Set Results
plt.scatter(x_test, y_test, color='red')
plt.plot(x_train, regression_obj.predict(x_train), color='blue')
plt.title('Salary vs Experience for Test set')
plt.xlabel('Experience (in Years)')
plt.ylabel('Salary')
plt.show() Sortie :
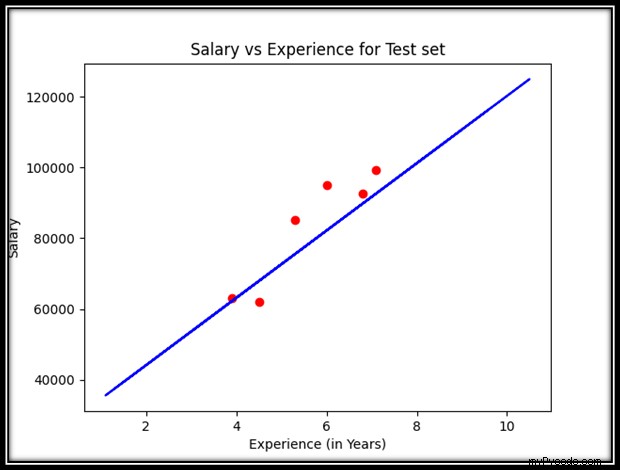
Comme le montre le graphique ci-dessus, les observations sont pour la plupart proches de la ligne de régression. Par conséquent, nous pouvons conclure que notre modèle de régression linéaire simple a de bonnes performances et une bonne précision et qu'il s'agit d'un modèle efficace car il est capable de faire de bonnes prédictions.
? Cela nous amène à la fin de ce didacticiel sur la régression linéaire simple. Veuillez vous abonner et restez à l'écoute pour la prochaine leçon de la série Machine Learning.