Salut les Finxters ! Aujourd'hui, nous allons parler de l'un des algorithmes de clustering les plus populaires :K-Means .
Vous êtes-vous déjà demandé comment organiser des données apparemment non structurées , donner un sens à des objets non ordonnés, de manière simple ?
Par exemple, vous devrez peut-être :
- effectuer une segmentation de la clientèle
- stocker les fichiers en fonction de leur contenu textuel
- compressez les images avec votre propre code
Nous apprendrons comment l'implémenter en Python et obtenir une sortie visuelle !
Un peu de théorie
Si vous n'êtes pas très au fait de la théorie et/ou si vous avez besoin de vous mettre au travail rapidement, vous pouvez simplement ignorer cette partie et passer à la suivante.
Tout d'abord, l'algorithme de Machine Learning que nous sommes sur le point d'apprendre est un non supervisé algorithme. Qu'est-ce que cela signifie ?
Cela signifie que nous n'avons au préalable aucune étiquette à utiliser pour le data-clustering, nous pourrions même ne pas savoir à quoi nous attendre ! Donc d'une certaine manière on va demander à l'algo de faire des groupes là où on n'en verrait pas forcément.
En plus d'être sans surveillance , nous disons qu'il s'agit d'un clustering algorithme parce que son but est de créer des sous-groupes de points de données qui sont proches d'une certaine manière, en termes de distance numérique. Cette idée a été mise en œuvre pour la première fois par les laboratoires Bell à la fin des années 1950.
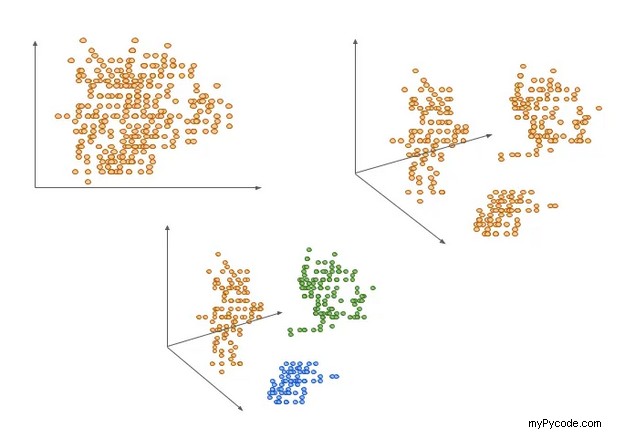
Peut-être que la meilleure façon de visualiser les clusters pour un œil humain est en 3D comme ci-dessus, ou en 2D ; cependant, vous avez rarement si peu d'entités dans le jeu de données. Et cela fonctionne mieux sur des données déjà regroupées géométriquement.
Ce qui signifie qu'il est souvent judicieux de commencer par réduire les dimensions, par exemple au moyen d'une analyse en composantes principales algorithme.
Notez que cet algo doit être assisté dans la mesure où il demande à l'utilisateur de saisir le nombre de clusters à créer. Chacun d'eux aura un point central appelé "centre de gravité".
Voici la procédure qui sera exécutée sous le capot une fois que nous aurons exécuté notre code :
- Choisir le nombre de clusters K à rechercher (entrée humaine)
- Initialiser les centroïdes K de manière aléatoire
- Calculer la distance quadratique moyenne de chaque point de données avec chaque centroïde
- Attribuez chaque point de données au centroïde le plus proche (un cluster)
- Calculez la moyenne de chaque cluster, qui devient vos nouveaux centroïdes
Les 3 étapes précédentes constituent ce qu'on appelle une époque .
Le programme que nous allons créer continuera à exécuter des époques jusqu'à ce que les centroïdes cessent de changer, c'est-à-dire que la convergence soit obtenue.
Une image vaut mille mots, alors voici à quoi elle ressemble :
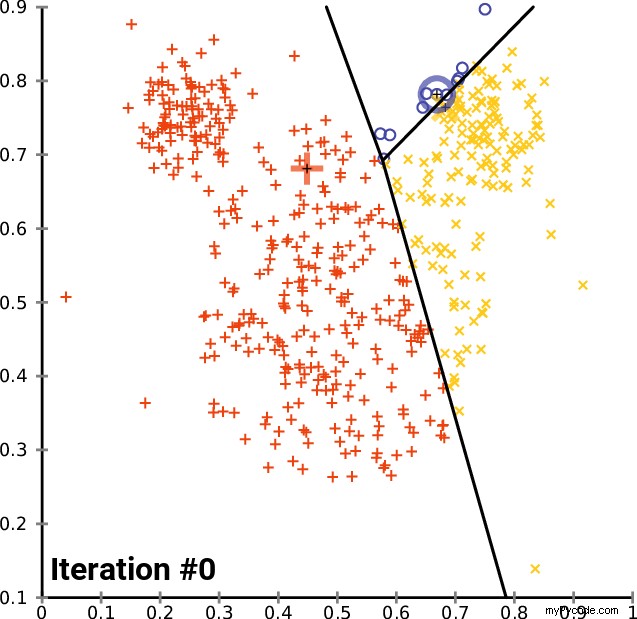
K-means a-t-il une fonction de perte ?
Oui, c'est ce qu'on appelle l'inertie et c'est la somme des carrés des distances entre les points de données et leurs centroïdes respectifs.
En pratique
- K-means est généralement exécuté plusieurs fois avec différentes initialisations aléatoires
- Peut utiliser un mini-lot aléatoire à chaque époque au lieu d'un ensemble de données complet, pour une convergence plus rapide
- L'algorithme est assez rapide
Installation du module
Le module que nous utiliserons pour effectuer cette tâche est Scikit-Learn, un module très pratique en matière d'apprentissage automatique en Python.
Si vous ne l'avez pas déjà, procédez avec la commande d'installation habituelle :
pip install scikit-learn
Ensuite, vérifiez qu'il est correctement installé :
pip show scikit-learn
Voici la page de documentation de sklearn dédiée à Kmeans :https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans , n'hésitez pas à la consulter pour plus de détails sur les arguments que vous pouvez passer et une utilisation plus poussée.
Une fois cela fait, nous importerons la classe Kmeans dans ce module :

La première ligne est l'importation.
Faire opérer la magie
La deuxième ligne instancie la classe Kmeans en créant un réel Kmeans objet, le voici mis dans un ‘km’ variable et l'utilisateur a demandé la création de 3 clusters.
La troisième ligne lance le calcul du clustering.
Une fois votre modèle K-Means ajusté, vous pouvez utiliser quatre attributs qui parlent d'eux-mêmes :
km.cluster_centers_:fournit les coordonnées de chaque centroïdekm.labels_fournit le numéro de cluster de chaque point de données (l'indexation commence à 0 comme les listes)km.inertia_:donne la somme des distances au carré des échantillons à leur centroïde le plus prochekm.n_iter_:fournit le nombre d'époques exécutées
Si vous voulez l'essayer mais que vous n'avez pas de jeu de données prêt, vous pouvez générer vos propres points grâce à sklearn make_blob fonctionnalité !
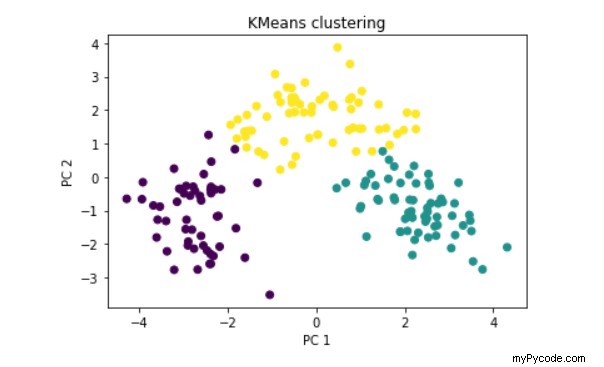
Voici un exemple de sortie en 2D, avec une réduction de dimensionnalité PCA comme vous pouvez le voir sur les axes x et y :
Je vous ai montré les attributs, qu'en est-il des méthodes disponibles ?
Le plus utile est probablement le .predict(new_datapoint) méthode, qui renvoie un entier correspondant au cluster (nombre) estimé par le modèle.
Comment choisir le meilleur nombre de clusters
Attendez, tout cela est très bien si je sais à quoi m'attendre en termes de nombre de clusters, car je peux alors saisir ce nombre, mais que se passe-t-il si je n'ai aucune idée du nombre de clusters à attendre ?
Ensuite, utilisez la méthode du coude. Il s'agit de représenter graphiquement l'évolution de l'inertie en fonction du nombre de clusters, et de relever le nombre de clusters au-delà duquel la diminution de l'inertie devient marginale :
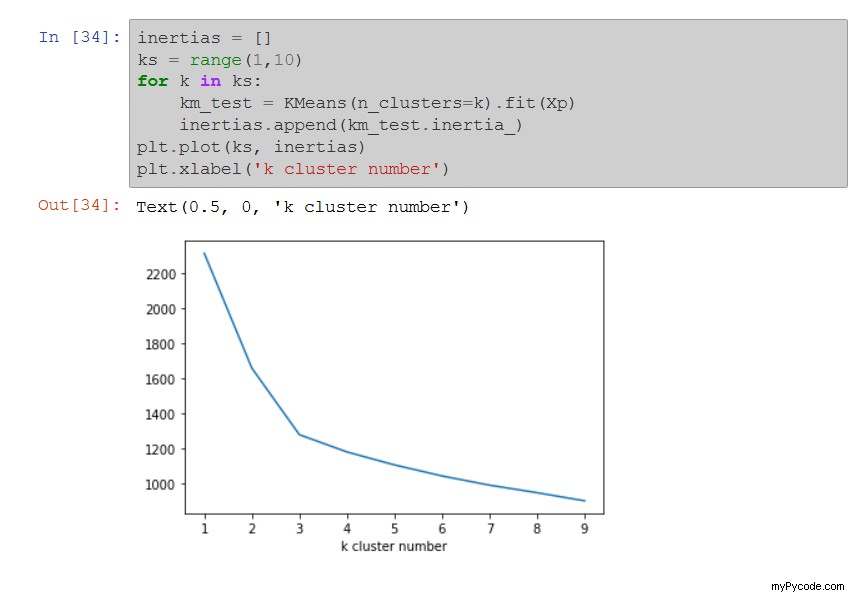
Dans l'exemple ci-dessus, le nombre idéal de clusters semble être 3. Le graphique est en forme de coude, d'où son nom.
K-Means avec NLP :afficher un nuage de mots
En supposant que vous ayez utilisé un algorithme K-Means dans une tâche de traitement du langage naturel, après le prétraitement et la vectorisation des mots, vous aurez peut-être besoin d'un moyen visuel de présenter votre sortie.
En effet, parfois le nombre de clusters sera élevé et l'affichage des libellés dans une grille n'aura pas autant d'impact.
Ensuite entre en jeu le module wordcloud, vous permettant de générer facilement de jolis nuages de mots colorés pour une compréhension instantanée.
Juste pip install wordcloud et utilisez
plt.imshow( Wordcloud().generate(your_text) )
Voir la documentation pour les paramètres.

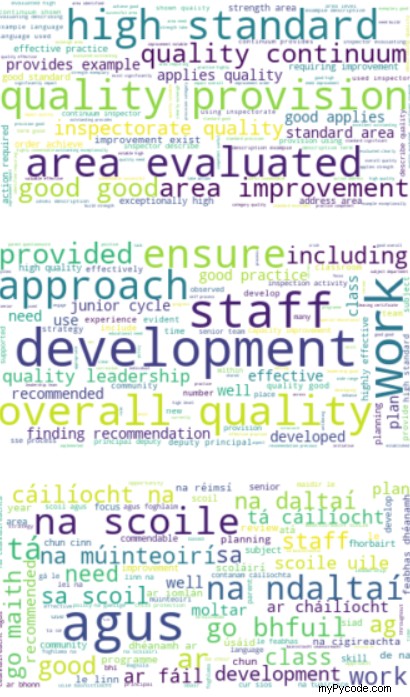
Dans mon exemple ci-dessus, je traitais des rapports PDF irlandais et, dans chaque rapport, une partie du contenu était écrite en gaélique.
Devinez ce que l'algo a trouvé ? Regardez le cluster du bas !
Cela illustre la caractéristique « sans surveillance » :je ne lui ai pas dit qu'il y avait une autre langue, et pourtant il l'a trouvée et l'a isolée de lui-même !