Cet article vous donne tout ce que vous devez savoir sur les ensembles en Python. Pour le rendre un peu plus amusant, j'ai utilisé des exemples de Harry Potter tout au long de l'article.
Qu'est-ce qu'un ensemble Python ?
La structure de données d'ensemble est l'un des types de données de collecte de base en Python et de nombreux autres langages de programmation.
En fait, il existe même des langages populaires pour l'informatique distribuée qui se concentrent presque exclusivement sur les opérations définies (comme MapReduce ou Apache Spark) en tant que primitives du langage de programmation.
❗ Définition : Un ensemble est une collection non ordonnée d'éléments uniques.
Décomposons cela.
(1) Collecte :Un ensemble est une collection d'éléments comme une liste ou un tuple. La collection se compose soit d'éléments primitifs (par exemple, des entiers, des flottants, des chaînes), soit d'éléments complexes (par exemple, des objets, des tuples). Cependant, tous les types de données doivent être hachables.
Qu'est-ce qu'un type de données hachable ?
Voici l'extrait pertinent de la documentation :
"Un objet est hachable s'il a une valeur de hachage qui ne change jamais pendant sa durée de vie (il a besoin d'une méthode __hash__()), et peut être comparé à d'autres objets (il a besoin d'une méthode __eq__() ou __cmp__()) ."
La structure de données définie repose fortement sur la fonction de hachage pour implémenter la spécification.
Jetons un coup d'œil à un exemple (nous restons avec les exemples de Harry Potter parce que c'est au sommet de ma tête — le lire tous les jours avec ma fille) :
hero = "Harry"
guide = "Dumbledore"
enemy = "Lord V."
print(hash(hero))
# 6175908009919104006
print(hash(guide))
# -5197671124693729851
## Puzzle: can we create a set of strings?
characters = {hero, guide, enemy}
print(characters)
# {'Lord V.', 'Dumbledore', 'Harry'}
## Puzzle: can we create a set of lists?
team_1 = [hero, guide]
team_2 = [enemy]
teams = {team_1, team_2}
# TypeError: unhashable type: 'list'
Comme vous pouvez le voir, nous pouvons créer un ensemble de chaînes car les chaînes sont hachables. Mais nous ne pouvons pas créer un ensemble de listes car les listes ne peuvent pas être hachées.
Pourquoi les listes ne peuvent-elles pas être hachées ?
Parce qu'ils sont modifiables :vous pouvez modifier une liste en ajoutant ou en supprimant des éléments. Si vous modifiez le type de données de la liste, la valeur de hachage change (elle est calculée en fonction du contenu de la liste). Cela viole directement la définition ci-dessus ("la valeur de hachage […] ne change jamais pendant sa durée de vie" ).
✔ Clé à emporter : les types de données modifiables ne sont pas hachables. Par conséquent, vous ne pouvez pas les utiliser dans des ensembles.
(2) Non ordonné :Contrairement aux listes, les ensembles ne sont pas ordonnés car il n'y a pas d'ordre fixe des éléments. En d'autres termes, quel que soit l'
Voici un exemple du code ci-dessus :
characters = {hero, guide, enemy}
print(characters)
# {'Lord V.', 'Dumbledore', 'Harry'}
Vous mettez d'abord le héros, mais l'interprète imprime d'abord l'ennemi (l'interpréteur Python est du côté obscur, évidemment).
(3) Unique :Tous les éléments de l'ensemble sont uniques. Chaque paire de valeurs (x,y) dans l'ensemble produit une paire différente de valeurs de hachage (hash(x)!=hash(y)). Par conséquent, chaque paire d'éléments x et y dans l'ensemble est différente.
Cela signifie que nous ne pouvons pas créer une armée de clones de Harry Potter pour combattre Lord V :
clone_army = {hero, hero, hero, hero, hero, enemy}
print(clone_army)
# {'Lord V.', 'Harry'} Quelle que soit la fréquence à laquelle vous mettez la même valeur dans le même ensemble, l'ensemble ne stocke qu'une seule instance de cette valeur. Une extension de la structure de données d'ensemble normale est la structure de données "multiset" où un multiset peut stocker plusieurs instances de la même valeur.
La bibliothèque standard Python est également fournie avec un package multiset.
Comment créer un ensemble ?
Il existe trois alternatives de base pour créer un ensemble :
- utiliser le constructeur
set([1,2,3])et passez un itérable des éléments ; - utiliser la notation entre parenthèses
{1,2,3}avec les éléments à l'intérieur, séparés par une virgule ; ou - créez un ensemble vide et ajoutez les éléments manuellement.
Voici un exemple de ces trois options :
s1 = {"Harry", "Ron", "Hermine"}
print(s1)
# {'Harry', 'Ron', 'Hermine'}
s2 = set(["Harry", "Ron", "Hermine"])
print(s2)
# {'Harry', 'Ron', 'Hermine'}
s3 = set()
s3.add("Harry")
s3.add("Ron")
s3.add("Hermine")
print(s3)
# {'Harry', 'Ron', 'Hermine'}
Cependant, vous ne pouvez pas mélanger ces façons de créer un ensemble ! Par exemple, vous ne pouvez pas passer les éléments individuels dans le constructeur set() .
# Wrong!
s4 = set("Harry", "Ron", "Hermine")
# TypeError: set expected at most 1 arguments, got 3
Une question qui est souvent posée est la suivante :
Un ensemble peut-il avoir plusieurs types de données ?
Oui absolument! Voici ce qui se passe si vous créez un ensemble avec des entiers et des chaînes :
s = {1, 2, 3, "Harry", "Ron"}
print(s)
# {1, 2, 3, 'Ron', 'Harry'}
Comme vous pouvez le voir, l'interpréteur Python ne se plaint pas lorsque vous lancez différents types de données dans le même ensemble. Vous devez être plus diabolique que ça !
Quels sont les exemples réels d'ensembles ?
Les ensembles sont partout dans le codage. Chaque langage de programmation majeur est livré avec une fonctionnalité d'ensemble intégrée. La structure de données d'ensemble est l'une des structures de données les plus importantes. Vous l'utiliserez tout le temps !
Par exemple, vous écrivez un robot d'exploration Web qui explore les pages Web et stocke leur URL dans une variable "visité". Maintenant, il y a deux manières d'implémenter cela :d'abord, utilisez une structure de données de liste et ajoutez l'URL si ce n'est pas
Un autre exemple est le marketing par e-mail. Supposons que vous disposiez d'une énorme base de données d'abonnés par e-mail, stockée sous forme de liste. Vous voulez trouver les adresses e-mail en double. Facile :convertissez la liste en un ensemble et revenez à la liste - et voilà - les doublons ont disparu ! Pourquoi? Parce que les ensembles sont sans doublons. Soit dit en passant, c'est aussi l'un des moyens les plus rapides de supprimer les doublons de la liste.
[Aperçu] Quelles sont les opérations d'ensemble les plus importantes en Python ?
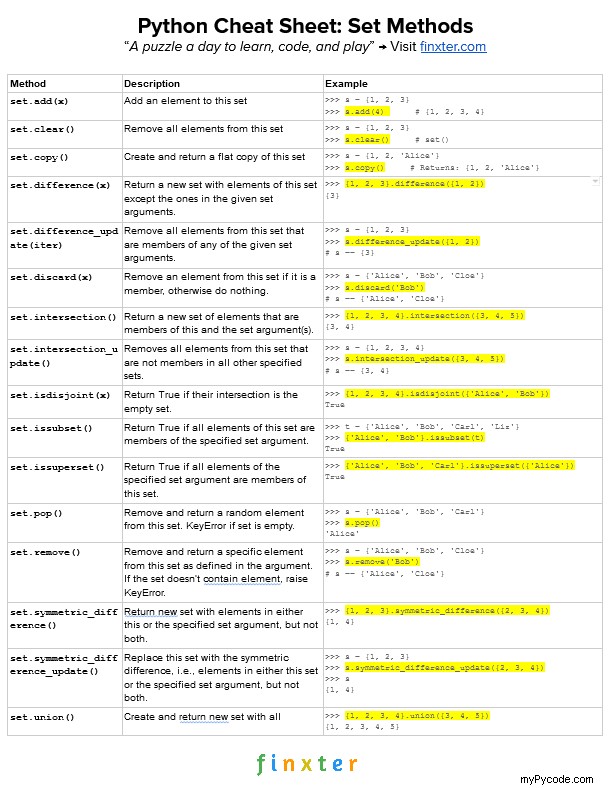
Toutes les méthodes d'ensemble sont appelées sur un ensemble donné. Par exemple, si vous avez créé un ensemble s = {1, 2, 3} , vous appelleriez s.clear() pour supprimer tous les éléments de l'ensemble. Nous utilisons le terme "cet ensemble" pour faire référence à l'ensemble sur lequel la méthode est exécutée.
add() | Ajouter un élément à cet ensemble |
clear() | Supprimer tous les éléments de cet ensemble |
copy() | Créer et renvoyer une copie plate de cet ensemble |
difference() | Crée et retourne un nouvel ensemble contenant tous les éléments de cet ensemble sauf ceux des arguments d'ensemble donnés. L'ensemble résultant a au plus autant d'éléments que cet ensemble. |
difference_update() | Supprime tous les éléments de cet ensemble qui sont membres de l'un des arguments d'ensemble donnés. |
discard() | Supprimer un élément de cet ensemble s'il en est membre, sinon ne rien faire. |
intersection() | Créer et renvoyer un nouvel ensemble qui contient tous les éléments qui sont membres de tous les ensembles - ceci et le ou les arguments de l'ensemble également. |
intersection_update() | Supprime tous les éléments de cet ensemble qui ne sont pas membres de tous les autres ensembles spécifiés. |
isdisjoint() | Renvoyer True si aucun élément de cet ensemble n'est membre d'un autre ensemble spécifié. Les ensembles sont disjoints si et seulement si leur intersection est l'ensemble vide. |
issubset( | Renvoyer True si tous les éléments de cet ensemble sont membres de l'argument d'ensemble spécifié. |
issuperset() | Renvoyer True si tous les éléments de l'argument d'ensemble spécifié sont membres de cet ensemble. |
pop() | Retire et renvoie un élément aléatoire de cet ensemble. Si l'ensemble est vide, il lèvera un KeyError . |
remove() | Retire et retourne un élément spécifique de cet ensemble comme défini dans l'argument. Si l'ensemble ne contient pas l'élément, il lèvera un KeyError . |
symmetric_difference() | Renvoie un nouvel ensemble avec des éléments dans cet ensemble ou dans l'argument d'ensemble spécifié, mais pas les éléments qui sont membres des deux. |
symmetric_difference_update() | Remplacez cet ensemble par la différence symétrique, c'est-à-dire les éléments de cet ensemble ou de l'argument d'ensemble spécifié, mais pas les éléments qui sont membres des deux. |
union() | Créer et retourner un nouvel ensemble avec tous les éléments qui sont dans cet ensemble, ou dans n'importe lequel des arguments d'ensemble spécifiés. |
update() | Mettre à jour cet ensemble avec tous les éléments qui se trouvent dans cet ensemble, ou dans l'un des arguments d'ensemble spécifiés. L'ensemble résultant a au moins autant d'éléments que n'importe quel autre. |
Vous pouvez télécharger les méthodes définies dans un PDF concis ici :
 Télécharger le PDF
Télécharger le PDF Commençons d'abord par quelques exemples. Prenez votre temps pour étudier attentivement ces exemples.
Gryffindors = {"Harry", "Ron", "Hermine", "Neville",
"Seamus", "Ginny", "Fred", "George"}
## Set Conversion
Weasleys = set(["Ron", "Ginny", "Fred"])
# {'Ron', 'Fred', 'Ginny'}
## Add Element
Weasleys.add("George")
# {'Ron', 'Fred', 'Ginny', 'George'}
## Remove Element
Gryffindors.remove("Neville")
# {'Ron', 'Hermine', 'George', 'Harry', 'Ginny', 'Seamus', 'Fred'}
## Membership
'Ginny' in Gryffindors
# True
## Size
len(Weasleys)
# 4
## Intersection
Weasleys & Gryffindors
# {'Fred', 'George', 'Ron', 'Ginny'}
## Union
Weasleys | Gryffindors
# {'Ron', 'Hermine', 'George', 'Harry', 'Ginny', 'Seamus', 'Fred'}
## Difference
Gryffindors - Weasleys
# {'Harry', 'Hermine', 'Seamus'}
## Symmetric Difference
Gryffindors ^ {'Harry', 'Ginny', 'Malfoy'}
# {'Ron', 'Fred', 'George', 'Malfoy', 'Hermine', 'Seamus'}
## Set Disjoint
Gryffindors.isdisjoint({'Malfoy', 'Grabbe', 'Goyle'})
# True
## Subset
Weasleys.issubset(Gryffindors)
# True
## Superset
Gryffindors.issuperset(Weasleys)
## Pop
print(Gryffindors.pop())
# 'Seamus'
print(Gryffindors)
# {'Ron', 'Fred', 'Hermine', 'Harry', 'Seamus', 'George'}
Dans les prochains paragraphes, je vous donne des exemples détaillés des opérations d'ensemble les plus importantes (voir docs).
Comment fonctionne la conversion d'ensembles en Python ?
Les ensembles sont des collections comme des tuples ou des listes. C'est pourquoi vous pouvez facilement convertir des ensembles en listes ou en tuples. Voici comment :
# convert list to set:
s = set([1,2,3])
print(s)
# {1, 2, 3}
# convert tuple to set:
s = set((1,2,3))
print(s)
# {1, 2, 3}
Notez que l'interpréteur Python utilise la notation entre parenthèses pour représenter un ensemble sur votre console.
Comment ajouter un élément à un ensemble en Python ?
Utiliser la fonction set s.add(x) pour ajouter l'élément x à l'ensemble s . Voici un exemple :
# Add Operator
s = set()
s.add("Harry")
s.add("Ron")
s.add("Hermine")
print(s)
# {'Harry', 'Ron', 'Hermine'}
Comment supprimer un élément d'un ensemble en Python ?
Utiliser la fonction set s.remove(x) pour supprimer l'élément x de l'ensemble s . Notez que parce que l'ensemble est sans doublon, il est impossible que l'élément x existe toujours dans l'ensemble après avoir appelé remove() . De cette manière, la sémantique est différente de celle des listes Python où remove() supprime uniquement la première occurrence de l'élément dans la liste.
Voici un exemple :
# Remove Operator
s = set()
s.add("Harry")
s.add("Ron")
s.add("Hermine")
print(s)
# {'Harry', 'Ron', 'Hermine'}
s.remove("Ron")
s.remove("Harry")
print(s)
# {'Hermine'}
Comment vérifier si un élément est dans un ensemble en Python (adhésion) ?
L'opérateur d'appartenance "x dans s" vérifie si défini s contient l'élément x . Il renvoie True si c'est le cas. Voici un exemple :
# Membership Operator
s = {"Harry", "Ron", "Hermine"}
x = "Ginny"
print(x in s)
# False
Comment déterminer le nombre d'éléments dans un ensemble Python ?
Utilisez simplement le len(s) intégré fonction pour obtenir le nombre d'éléments dans l'ensemble s .
Voici un exemple :
# Size Operator
s = {"Harry", "Ron", "Hermine"}
print(len(s))
# 3
Comment intersecter deux ensembles en Python ?
L'opérateur d'intersection d'ensemble crée un nouvel ensemble qui contient tous les éléments qui se trouvent dans les deux ensembles s1 et s2 - mais pas ceux qui ne sont que dans un seul ensemble. Cela signifie que le nouvel ensemble ne sera jamais plus grand que l'un des ensembles s1 ou s2.
Il existe deux opérateurs en Python pour intersecter deux ensembles s1 et s2 :la méthode s1.intersection(s2) ou l'opérateur s1 & s2 .
Peut-être vous souvenez-vous des diagrammes de Venn de l'école ? Voici un exemple de
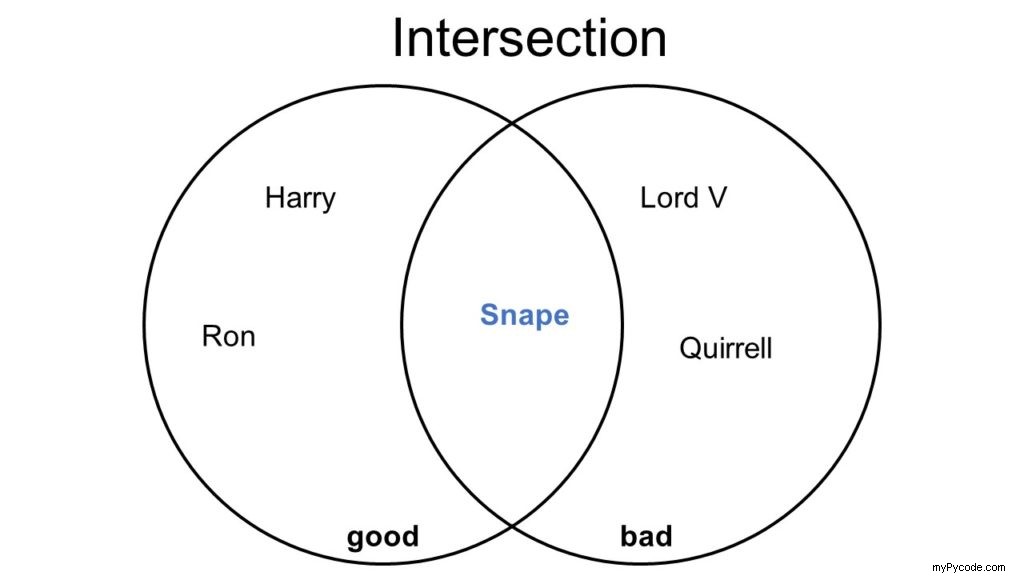
Comme vous pouvez le voir, le nouvel ensemble contient tous les éléments qui sont dans les deux ensembles s1 et s2 .
Voici un exemple dans le code :
# Intersection
good = {"Harry", "Ron", "Snape"}
bad = {"Lord V", "Quirrell", "Snape"}
print(good & bad)
# {'Snape'}
print(good.intersection(bad))
# {'Snape'}
Qu'est-ce que l'union de deux ensembles ?
L'opérateur d'union d'ensemble crée un nouvel ensemble qui contient tous les éléments qui se trouvent dans l'un ou l'autre des ensembles s1 ou s2 . Cela signifie que le nouvel ensemble ne sera jamais plus petit que l'un des ensembles s1 ou s2 .
Il y a deux opérateurs en Python pour calculer l'union de deux ensembles s1 ou s2 :la fonction s1.union(s2) ou l'opérateur s1 | s2 .
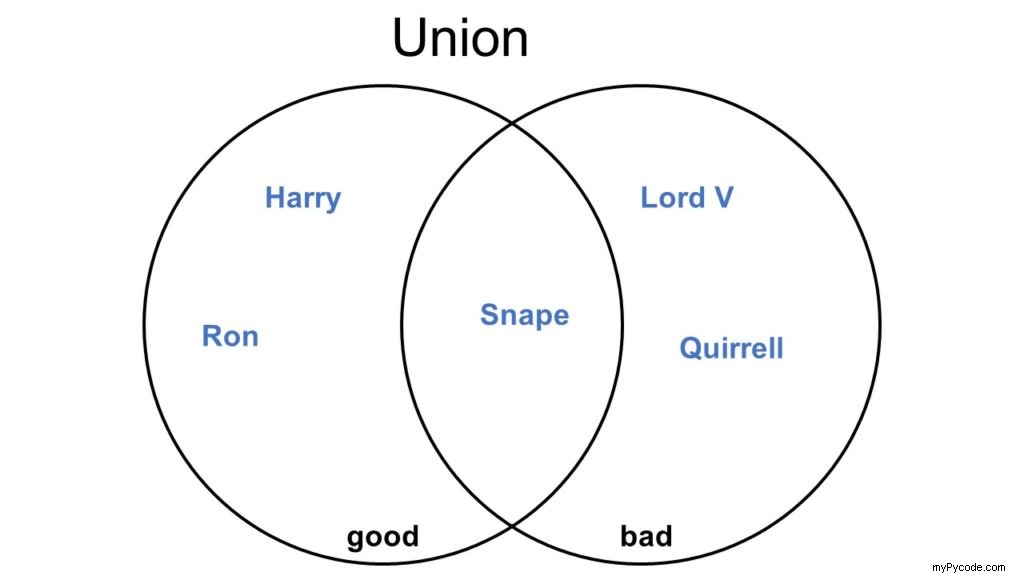
# Union
good = {"Harry", "Ron", "Snape"}
bad = {"Lord V", "Quirrell", "Snape"}
print(good | bad)
# {'Lord V', 'Quirrell', 'Snape', 'Harry', 'Ron'}
print(good.union(bad))
# {'Lord V', 'Quirrell', 'Snape', 'Harry', 'Ron'}
Quelle est la différence entre deux ensembles ?
L'opérateur de différence d'ensemble crée un nouvel ensemble qui contient tous les éléments qui sont dans l'ensemble s1 mais pas en s2 . Cela signifie que le nouvel ensemble ne sera jamais plus grand que l'ensemble s1 .
Il y a deux opérateurs en Python pour calculer la différence de deux ensembles s1 ou s2 :la méthode s1.difference(s2) ou l'opérateur s1 – s2.

# Difference
good = {"Harry", "Ron", "Snape"}
bad = {"Lord V", "Quirrell", "Snape"}
print(good - bad)
# {'Harry', 'Ron'}
print(good.difference(bad))
# {'Harry', 'Ron'}
Quelle est la différence symétrique de deux ensembles ?
L'opérateur de différence d'ensemble symétrique crée un nouvel ensemble qui contient tous les éléments qui se trouvent dans l'un ou l'autre des ensembles s1 ou en s2 mais pas à l'intersection de s1 ou s2 .

# Symmetric Difference
good = {"Harry", "Ron", "Snape"}
bad = {"Lord V", "Quirrell", "Snape"}
print(good ^ bad)
# {'Quirrell', 'Ron', 'Harry', 'Lord V'}
print(good.symmetric_difference(bad))
# {'Quirrell', 'Ron', 'Harry', 'Lord V'}
print(bad.symmetric_difference(good))
# {'Quirrell', 'Ron', 'Lord V', 'Harry'}
Qu'est-ce que l'opérateur Set Disjoint en Python ?
L'opération d'ensemble disjoint vérifie pour deux ensembles donnés s'ils n'ont pas d'éléments en commun.
# Set Disjoint Operation
good = {"Harry", "Ron", "Snape"}
bad = {"Lord V", "Quirrell", "Snape"}
print(good.isdisjoint(bad))
# False
print(bad.isdisjoint(good))
# False
bad.remove("Snape")
print(good.isdisjoint("Snape"))
# True
Comme vous pouvez le voir, le bien et le mal dans Harry Potter ne sont pas disjoints car "Rogue" est à la fois - bon ET mauvais. Cependant, après avoir retiré "Snape" de l'ensemble des mauvais sorciers (SPOILER ALERT), ils redeviennent disjoints.
Comment fonctionne l'opérateur de sous-ensemble en Python ?
L'opération s1.issubset(s2) en Python vérifie si tous les éléments de l'ensemble s1 sont également des éléments de l'ensemble s2 . Bien sûr, définissez s2 peut avoir beaucoup plus d'éléments qui ne sont pas dans le set s1 .
# Set Subset Operation
Gryffindors = {"Seamus", "Fred", "George", "Harry", "Ginny", "Hermine"}
Weasleys = {"Fred", "George", "Ginny"}
print(Weasleys.issubset(Gryffindors))
# True
print(Gryffindors.issubset(Weasleys))
# False
Alors que l'ensemble de tous les Weasley est un sous-ensemble de l'ensemble de tous les Gryffondors, l'inverse ne tient pas - il y a (toujours) des Gryffondors qui ne sont pas des Weasley (par exemple "Harry" et "Hermine").
Comment fonctionne l'opérateur Superset en Python ?
L'opération s1.issuperset(s2) en Python est analogue à l'opération précédente issubset() . Mais contrairement à cela, il vérifie si tous les éléments de l'ensemble s2 sont aussi des éléments de l'ensemble s1 . Bien sûr, définissez s1 peut avoir beaucoup plus d'éléments qui ne sont pas dans l'ensemble s2 .
# Set Superset Operation
Gryffindors = {"Seamus", "Fred", "George", "Harry", "Ginny", "Hermine"}
Weasleys = {"Fred", "George", "Ginny"}
print(Weasleys.issuperset(Gryffindors))
# False
print(Gryffindors.issuperset(Weasleys))
# True
De toute évidence, l'ensemble de tous les Weasley n'est PAS un sur-ensemble de l'ensemble de tous les Gryffondors (par exemple, "Harry" n'est pas un Weasley). Cependant, l'ensemble de tous les Gryffondors est un sur-ensemble de l'ensemble de tous les Weasley.
Comment faire apparaître un élément Set en Python ?
Le s.pop() l'opération supprime un élément arbitraire x de l'ensemble s . Il renvoie cet élément x . Le pop() L'opération est souvent utile car vous ne pouvez pas accéder facilement à un élément arbitraire d'un ensemble - vous ne pouvez pas utiliser d'index sur les ensembles Python car les ensembles ne sont pas ordonnés.
Voici un exemple :
# Set Pop Operation
teachers = {"Trelawney", "Snape", "Hagrid"}
leaves_hogwarts = teachers.pop()
print(teachers)
# e.g. {'Snape', 'Hagrid'}
Vous souvenez-vous de l'époque où le professeur Ombrage contrôlait chaque enseignant de Poudlard ? Elle a rapidement découvert que le professeur Trelawney n'était pas un enseignant approprié, alors elle l'a expulsée de l'ensemble de tous les enseignants. Essentiellement, elle a exécuté le pop() opération (bien que la sélection d'un élément de l'ensemble soit moins aléatoire).
Comment fonctionne la compréhension d'ensemble ?
La compréhension des ensembles est une manière concise de créer des ensembles. Supposons que vous souhaitiez filtrer tous les clients de votre base de données qui gagnent plus de 1 000 000 $. Voici ce que ferait un débutant ne connaissant pas la compréhension des ensembles :
# (name, $-income)
customers = [("John", 240000),
("Alice", 120000),
("Ann", 1100000),
("Zach", 44000)]
# your high-value customers earning >$1M
whales = set()
for customer, income in customers:
if income>1000000:
whales.add(customer)
print(whales)
# {'Ann'}
Cet extrait nécessite quatre lignes uniquement pour créer un ensemble de clients de grande valeur (baleines) !
Si vous faites cela dans votre base de code Python publique, préparez-vous à vous faire arrêter pour "ne pas écrire de code Pythonic". 😉
Au lieu de cela, une bien meilleure façon de faire la même chose est d'utiliser la compréhension d'ensemble :
whales = {x for x,y in customers if y>1000000}
print(whales)
# {'Ann'}
Magnifique, n'est-ce pas ?
La compréhension des ensembles est extrêmement simple lorsque vous connaissez la formule que je vais vous montrer dans un instant. Alors pourquoi les gens ne savent-ils pas comment utiliser la compréhension d'ensemble ? Parce qu'ils n'ont jamais recherché la déclaration la plus importante sur la compréhension des listes (qui est similaire à la compréhension des ensembles) dans la documentation Python. C'est ça :
"Une compréhension de liste se compose de crochets contenant une expression suivie d'une clause for, puis de zéro ou de plusieurs clauses for ou if. Le résultat sera une nouvelle liste résultant de l'évaluation de l'expression dans le contexte des clauses for et if qui la suivent. (source)
En d'autres termes, voici la formule pour la compréhension d'ensembles.
Formule :la compréhension d'un ensemble se compose de deux parties.
'{' + expression + context + '}'
La première partie est
whales = {x.upper() for x,y in customers if y>1000000}
print(whales)
# {'ANN'}
La deuxième partie est
small_fishes = {x + str(y) for x,y in customers if y<1000000 if x!='John'}
# (John is not a small fish...)
print(small_fishes)
# {'Zach44000', 'Alice120000'}
Pour plus de détails sur la compréhension des ensembles, lisez cet article.
Ensembles Python vs Listes – Quand utiliser des ensembles et quand utiliser des listes en Python ?
En tant que maître codeur, vous sélectionnez toujours la meilleure structure de données pour votre problème à résoudre.
Si vous choisissez la bonne structure de données, votre solution sera élégante et fonctionnera sans problème même pour les grandes tailles d'entrée. En même temps, votre code source sera concis et lisible.
C'est l'étalon-or.
Mais si vous choisissez la mauvaise structure de données pour votre problème, vous perdrez beaucoup de temps à écrire le code. Dès que vous croirez avoir résolu le problème, vous vous rendrez compte que votre base de code regorge de bugs. Et il sera très inefficace et incapable de fonctionner sur de grandes tailles d'entrée.
Examinons un exemple pratique :le problème de la suppression des doublons d'une collection.
dupes = [1,4,3,2,3,3,2,1]
# Bad solution: wrong data structure (list)
lst_tmp = [ ]
for element in dupes:
if element not in lst_tmp:
lst_tmp.append(element)
print(lst_tmp)
# [1, 4, 3, 2]
# Good solution: right data structure (set)
print(list(set(dupes)))
# [1, 2, 3, 4]
Vous utilisez ici la structure de données d'ensemble en raison de ses caractéristiques spécifiques :un ensemble est une collection non ordonnée d'éléments uniques. Bingo ! C'est ce dont nous avons besoin.
D'un autre côté, la structure des données de la liste ne correspond pas si bien au problème :elle autorise les doublons et se soucie de l'ordre des éléments (ce que nous ne faisons pas).
Pourquoi la liste est-elle inefficace dans cet exemple ? Parce que la vérification de l'appartenance est très lente pour les listes - vous devez parcourir toute la liste pour voir si un élément est dans la liste ou non.
Alors, comment savoir quand utiliser des listes et quand utiliser des ensembles en Python ?
N'oubliez pas le tableau simplifié suivant.
Au lieu d'utiliser la notation Big-O plus complexe, je vous dis simplement si l'opération est FAST ou SLOW (pour les pros :FAST est une complexité d'exécution constante, SLOW est une complexité d'exécution linéaire). Si vous souhaitez approfondir les complexités d'exécution des différentes opérations d'ensemble, veuillez consulter le deuxième tableau plus complet ci-dessous.
Vous devez connaître ce tableau par cœur si vous avez la moindre ambition en matière de codage. Passez du temps maintenant et maîtrisez-le à fond.
| # Opérateur | Liste | Définir |
| Ajouter un élément | RAPIDE | RAPIDE |
| Supprimer l'élément | LENT | RAPIDE |
| Adhésion ("in") | LENT | RAPIDE |
| Accéder à | RAPIDE | -- |
| Syndicat | — | LENT |
| Intersection | — | LENT |
En clair :utilisez des ensembles si vous avez seulement besoin de tester l'appartenance, utilisez des listes si l'ordre des éléments est important.
La raison pour laquelle les ensembles sont supérieurs en termes de performances est qu'ils ne fournissent pas un "service" aussi puissant - ils ignorent l'ordre concret des éléments.
Comment la structure Set Data est-elle implémentée dans Python ? Et pourquoi l'adhésion définie est-elle plus rapide que l'adhésion à la liste ?
Nous avons déjà établi :
"L'appartenance à une liste est plus lente que l'appartenance à un ensemble car la première vérifie chaque élément tandis que la seconde n'utilise qu'une seule recherche."
Comprenez-vous vraiment pourquoi ?
Si j'aborde ce sujet dans ma messagerie Cours Python (c'est gratuit, viens me rejoindre 😉, la question suivante revient régulièrement :
"Je ne comprends toujours pas pourquoi les vérifications d'appartenance à un ensemble devraient être plus rapides. Pourquoi n'y a-t-il qu'une seule recherche pour un ensemble ?"
Je crois que de nombreux codeurs avancés auraient des difficultés à expliquer POURQUOI l'adhésion à un ensemble est plus rapide. Arrêtez de lire un instant et essayez de vous l'expliquer !
Alors, comment fonctionnent les ensembles en Python ?
Les ensembles sont implémentés en utilisant une table de hachage comme structure de données sous-jacente. Une table de hachage est une structure de données qui associe des clés à des valeurs (comme un dict en Python). Voici un exemple de table de hachage stockant l'âge de personnages "Harry Potter" aléatoires :
Key – > Value
(Name) – > (Age)
----------------
"Harry" – > 13
"Hermine" – > 13
"Dumbledore" – > 398
"Lord V" – > 72
Avant de poursuivre, comment Python utilise-t-il une table de hachage pour implémenter un ensemble ? Simplement en utilisant des "valeurs fictives". Voici comment Python, conceptuellement, implémente l'ensemble {"Harry", "Hermine", "Dumbledore", "Lord V"} :
"Harry" – > None
"Hermine" – > None
"Dumbledore" – > None
"Lord V" – > None
Imaginez que vous deviez implémenter la structure de données définie basée sur la table de hachage (ou le dictionnaire Python). Chaque table de hachage fournit déjà l'opérateur d'appartenance (par exemple, "clé" dans dict.keys() ). Et si vous savez comment calculer l'appartenance, vous pouvez facilement créer les fonctions d'ensemble les plus importantes comme l'union ou l'intersection.
Revenons maintenant à la table de hachage ci-dessus pour savoir pourquoi l'opérateur d'appartenance est rapide pour les tables de hachage.
Rappelez-vous, notre objectif est le suivant. Étant donné une clé, nous voulons obtenir la valeur associée (par exemple, "Harry" devrait nous donner la valeur "13").
Au cœur de toute table de hachage se trouve un tableau. Supposons que nous stockions les données dans un tableau comme celui-ci :
Index – > Value
0 – > ("Harry", 13)
1 – > ("Hermine", 13)
2 – > ("Dumbledore", 398)
3 – > ("Lord V", 72)
C'est en fait le nombre de tables de hachage implémentées (par exemple dans le langage de programmation C). La bonne chose avec les tableaux est que si vous connaissez l'index, vous pouvez rapidement obtenir la paire (clé, valeur) stockée à cet index. Par exemple, vous pouvez obtenir la paire (clé, valeur) ("Lord V", 72) d'un seul coup en appelant le array[3] .
Cependant, tester si une certaine clé existe dans le tableau est pénible :vous devez vérifier CHAQUE élément du tableau jusqu'à ce que vous trouviez la clé ou que vous manquiez d'éléments du tableau. Si le tableau a une taille n, vous devez rechercher n éléments si la clé n'est pas dans le tableau.
La table de hachage utilise une astuce intéressante :elle utilise une fonction qui associe une clé à un index (appelée fonction de hachage). L'index est ensuite utilisé pour obtenir la valeur associée dans le tableau. Si vous le regardez d'en haut, vous affectez des clés à des valeurs.
Relisez le dernier paragraphe jusqu'à ce que vous l'obteniez.
Voici un exemple :
Key – > Hashing – > Index – > Value
"Harry" – > h("Harry") – > 0 – > 13
"Hermine" – > h("Hermine") – > 1 – > 13
"Dumbledore" – > h("Dumbledore") – > 2 – > 398
"Lord V" – > h("Lord V") – > 3 – > 72
De cette façon, vous pouvez implémenter une table de hachage en utilisant rien d'autre qu'un simple tableau (qui est intégré à presque tous les langages de programmation).
Maintenant, voici le problème :quel que soit le nombre de paires (clé, valeur) que vous avez, vous calculez l'index à l'aide de la fonction de hachage sur la clé et utilisez l'index pour accéder à l'élément de tableau (valeur). Le calcul de la valeur de hachage et l'accès au tableau sont rapides et indépendants de la taille de la structure de données.
Je pense que cela répond déjà à la question ("pourquoi l'adhésion définie est-elle plus rapide que l'adhésion à la liste ?"). Je veux juste noter que c'est un peu plus difficile que cela car la table de hachage doit tenir compte des "collisions" qui se produisent si deux clés différentes sont hachées vers le même index. Techniquement, cela est résolu en stockant PLUSIEURS valeurs par index et en diminuant la probabilité de telles collisions en sélectionnant de meilleures fonctions de hachage.

