Les populaires K-Nearest Neighbors (KNN) est utilisé pour la régression et la classification dans de nombreuses applications telles que les systèmes de recommandation, la classification des images et la prévision des données financières. C'est la base de nombreuses techniques avancées d'apprentissage automatique (par exemple, dans la recherche d'informations). Il ne fait aucun doute que la compréhension de KNN est un élément important de votre formation en informatique.
Regardez l'article en vidéo :
K-Nearest Neighbors (KNN) est un algorithme d'apprentissage automatique robuste, simple et populaire. Il est relativement facile à mettre en œuvre à partir de zéro tout en étant compétitif et performant.
Récapitulatif de l'apprentissage automatique
L'apprentissage automatique consiste à apprendre un soi-disant modèle à partir d'un ensemble de données d'entraînement donné .
Ce modèle peut ensuite être utilisé pour l'inférence, c'est-à-dire pour prédire les valeurs de sortie pour des données d'entrée potentiellement nouvelles et invisibles.
Un modèle est généralement une abstraction de haut niveau telle qu'une fonction mathématique déduite des données d'apprentissage. La plupart des techniques d'apprentissage automatique tentent de trouver des modèles dans les données qui peuvent être capturés et utilisés pour la généralisation et la prédiction sur de nouvelles données d'entrée.
Formation KNN
Cependant, KNN suit un chemin assez différent. L'idée simple est la suivante :l'ensemble de données complet est votre modèle.
Oui, tu l'as bien lu.
Le modèle d'apprentissage automatique KNN n'est rien de plus qu'un ensemble d'observations. Chaque instance de vos données d'entraînement fait partie de votre modèle. La formation devient aussi simple que de jeter les données de formation dans une structure de données de conteneur pour une récupération ultérieure. Il n'y a pas de phase d'inférence compliquée et des heures de traitement GPU distribué pour extraire des modèles à partir des données.
Inférence KNN
Un grand avantage est que vous pouvez utiliser l'algorithme KNN pour la prédiction ou la classification - comme vous le souhaitez. Vous exécutez la stratégie suivante, étant donné votre vecteur d'entrée x .
- Trouvez les K voisins les plus proches de
xselon une métrique de similarité prédéfinie . - Agrégez les K voisins les plus proches en une seule valeur de "prédiction" ou de "classification". Vous pouvez utiliser n'importe quelle fonction d'agrégation telle que moyenne, moyenne, max, min, etc.
C'est ça. Simple, n'est-ce pas ?
Découvrez le graphique suivant :
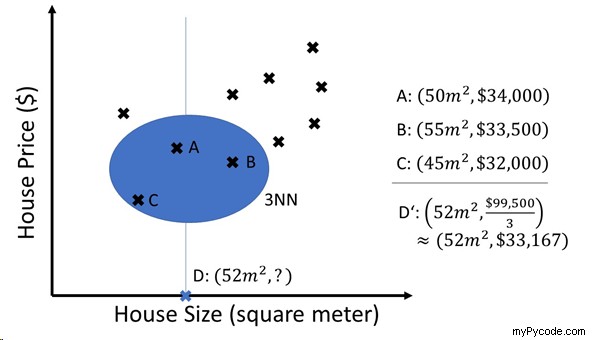
Supposons que votre entreprise vende des maisons à des clients. Il a acquis une large base de données de clients et de prix immobiliers expérimentés.
Un jour, votre client vous demande combien il peut s'attendre à payer pour une maison de 52 mètres carrés. Vous interrogez votre "modèle" KNN et il vous donne immédiatement la réponse 33 167 $. Et en effet, votre client trouve un logement pour 33 489 $ la même semaine. Comment le système KNN en est-il arrivé à cette prédiction étonnamment précise ?
Il a simplement calculé les K =3 plus proches voisins de la requête "D =52 mètres carrés" à partir du modèle en ce qui concerne la distance euclidienne. Les trois voisins les plus proches sont A, B et C avec des prix de 34 000 $, 33 500 $ et 32 000 $, respectivement. Dans la dernière étape, le KNNagrège les trois voisins les plus proches en calculant la moyenne simple. AsK=3 dans cet exemple, nous désignons le modèle par "3NN".
Bien sûr, vous pouvez faire varier les fonctions de similarité, le paramètre K et la méthode d'agrégation pour proposer des modèles de prédiction plus sophistiqués.
Un autre avantage de KNN est qu'il peut être facilement adapté au fur et à mesure que de nouvelles observations sont faites. Ce n'est généralement pas vrai pour n'importe quel modèle d'apprentissage automatique. Une faiblesse à cet égard est évidemment que la complexité de calcul devient de plus en plus difficile, plus vous ajoutez de points. Pour tenir compte de cela, vous pouvez supprimer en permanence les valeurs "périmées" du système.
Comme je l'ai mentionné ci-dessus, vous pouvez également utiliser KNN pour les problèmes de classification. Au lieu de faire la moyenne sur les K voisins les plus proches, vous pouvez simplement utiliser un mécanisme de vote où chaque voisin le plus proche vote pour sa classe. La classe avec le plus de votes gagne.
Mise en œuvre de KNN avec SKLearn
## Dependencies
from sklearn.neighbors import KNeighborsRegressor
import numpy as np
## Data (House Size (square meters) / Hous Price ($))
X = np.array([[35, 30000], [45, 45000], [40, 50000],
[35, 35000], [25, 32500], [40, 40000]])
## One-liner
KNN = KNeighborsRegressor(n_neighbors=3).fit(X[:,0].reshape(-1,1), X[:,1].reshape(-1,1))
## Result & puzzle
res = KNN.predict([[30]])
print(res)
Voyons comment utiliser KNN en Python - en une seule ligne de code.
Devinez :quel est le résultat de cet extrait de code ?
Comprendre le code
Pour vous aider à voir le résultat, traçons les données de logement à partir du code :
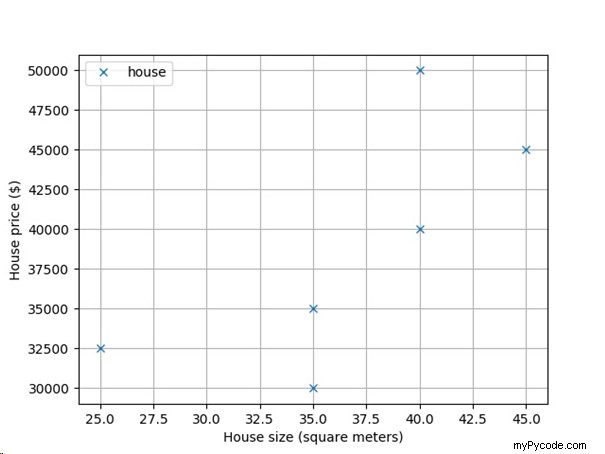
Voyez-vous la tendance générale ? Avec la taille croissante de votre maison, vous pouvez vous attendre à une croissance linéaire de son prix de marché. Doublez les mètres carrés et le prix doublera aussi.
Dans le code, le client demande votre prévision de prix pour une maison de 30 mètres carrés. Que prédit KNN avec K=3 (en bref :3NN) ?
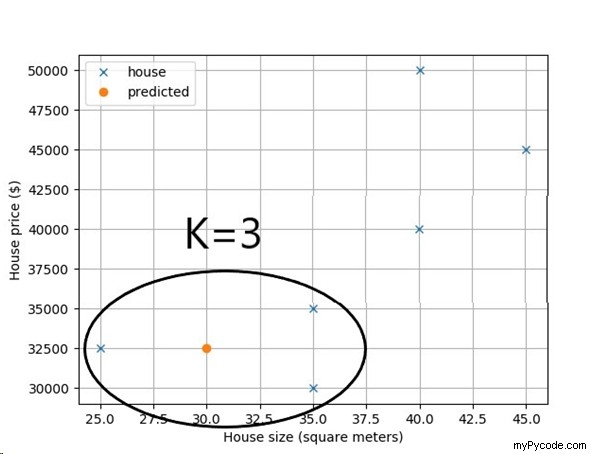
Magnifiquement simple, n'est-ce pas ? L'algorithme KNN trouve les trois maisons les plus proches en ce qui concerne la taille de la maison et fait la moyenne du prix de la maison prévu comme la moyenne des K =3 voisins les plus proches.
Ainsi, le résultat est de 32 500 $.
Peut-être avez-vous été confus par la partie conversion de données dans le one-liner. Permettez-moi d'expliquer rapidement ce qui s'est passé :
## One-liner KNN = KNeighborsRegressor(n_neighbors=3).fit(X[:,0].reshape(-1,1), X[:,1].reshape(-1,1))
Tout d'abord, nous créons un nouveau modèle d'apprentissage automatique appelé "KNeighborsRegressor". Si vous voudriez prendre KNN pour la classification, vous prendriez le modèle "KNeighborsClassifier".
Deuxièmement, nous "entraînons" le modèle en utilisant le fit fonction à deux paramètres. Le premier paramètre définit l'entrée (la taille de la maison) et le second paramètre définit la sortie (le prix de la maison). La forme des deux paramètres doit être telle que chaque observation soit une structure de données de type tableau. Par exemple, vous n'utiliserez pas "30 " comme entrée mais " [30] ”. La raison en est que, en général, l'entrée peut être multidimensionnelle plutôt qu'unidimensionnelle. Par conséquent, nous remodelons l'entrée :
print(X[:,0]) "[35 45 40 35 25 40]"
Si nous utilisions ce tableau NumPy 1D comme entrée du fit() fonction, la fonction ne fonctionnerait pas correctement car elle attend un tableau d'observations (de type tableau) - et non un tableau d'entiers.
Par conséquent, nous convertissons le tableau en conséquence en utilisant le reshape() fonction :
print(X[:,0].reshape(-1,1)) """ [[35] [45] [40] [35] [25] [40]] """
Maintenant, nous avons six observations de type tableau. L'indice négatif -1 dans le reshape() L'appel de fonction est notre expression de "paresse":nous voulons que NumPy détermine automatiquement le nombre de lignes - et spécifie uniquement le nombre de colonnes dont nous avons besoin (c'est-à-dire 1 colonne).
Cet article est basé sur un chapitre de mon livre Python One-Liners :
Livre Python One-Liners :maîtrisez d'abord la ligne unique !
Les programmeurs Python amélioreront leurs compétences en informatique avec ces lignes utiles.

Python One-Liners vous apprendra à lire et à écrire des « lignes simples » :des déclarations concises de fonctionnalités utiles regroupées dans une seule ligne de code. Vous apprendrez à décompresser et à comprendre systématiquement n'importe quelle ligne de code Python, et à écrire du Python éloquent et puissamment compressé comme un expert.
Les cinq chapitres du livre couvrent (1) les trucs et astuces, (2) les expressions régulières, (3) l'apprentissage automatique, (4) les principaux sujets de science des données et (5) les algorithmes utiles.
Des explications détaillées des one-liners introduisent les concepts clés de l'informatique etdéveloppez vos compétences en matière de codage et d'analyse . Vous découvrirez les fonctionnalités Python avancées telles que la compréhension de liste , tranchage , fonctions lambda , expressions régulières , carte et réduire fonctions et affectations de tranches .
Vous apprendrez également à :
- Exploiter les structures de données pour résoudre des problèmes réels , comme utiliser l'indexation booléenne pour trouver des villes avec une pollution supérieure à la moyenne
- Utiliser les bases de NumPy comme tableau , forme , axe , tapez , diffusion , indexation avancée , tranchage , tri , recherche , agrégation , et statistiques
- Calculer des statistiques de base de tableaux de données multidimensionnels et les algorithmes K-Means pour l'apprentissage non supervisé
- Créer davantage d'expressions régulières avancées en utilisant le regroupement et groupes nommés , anticipations négatives , caractères échappés , espaces blancs, jeux de caractères (et jeux de caractères négatifs ) et opérateurs gourmands/non gourmands
- Comprendre un large éventail de sujets informatiques , y compris les anagrammes , palindromes , surensembles , permutations , factorielles , nombres premiers , Fibonacci chiffres, obscurcissement , recherche , et tri algorithmique
À la fin du livre, vous saurez comment écrire Python dans sa forme la plus raffinée , et créez de belles pièces concises d'"art Python" en une seule ligne.
Obtenez vos Python One-Liners sur Amazon !!