La précision des prédictions de votre modèle est nulle, mais vous devez respecter le délai à tout prix ?
Essayez l'approche rapide et sale de "méta-apprentissage" appelée apprentissage d'ensemble . Dans cet article, vous découvrirez une technique d'apprentissage d'ensemble spécifique appelée forêts aléatoires qui combine les prédictions (ou classifications) de plusieurs algorithmes d'apprentissage automatique. Dans de nombreux cas, cela vous donnera de meilleurs résultats de dernière minute.
Python de classification aléatoire des forêts vidéo
Cette vidéo vous donne une introduction concise à l'apprentissage d'ensemble avec des forêts aléatoires à l'aide de sklearn :
Ensemble d'apprentissage
Vous avez peut-être déjà étudié plusieurs algorithmes d'apprentissage automatique et réalisé que différents algorithmes ont des forces différentes.
Par exemple, les classificateurs de réseaux neuronaux peuvent générer d'excellents résultats pour des problèmes complexes. Cependant, ils sont également sujets au « surapprentissage ” les données en raison de leur puissante capacité à mémoriser des modèles de données à grain fin.
L'idée simple de l'apprentissage d'ensemble pour les problèmes de classification s'appuie sur le fait que vous ne savez souvent pas à l'avance quelle technique d'apprentissage automatique fonctionne le mieux.
Comment fonctionne l'apprentissage d'ensemble ? Vous créez un méta-classificateur composé de plusieurs types ou instances d'algorithmes d'apprentissage automatique de base. En d'autres termes, vous entraînez plusieurs des modèles. Pour classer un seul observation, vous demandez à tous modèles pour classer l'entrée indépendamment. Maintenant, vous renvoyez la classe qui a été renvoyée le plus souvent, compte tenu de votre entrée, en tant que "méta-prédiction" . Ceci est la sortie finale de votre algorithme d'apprentissage d'ensemble.
Apprentissage aléatoire de la forêt
Les forêts aléatoires sont un type spécial d'algorithmes d'apprentissage d'ensemble. Ils se concentrent sur l'apprentissage par arbre de décision. Une forêt se compose de plusieurs arbres. De même, une forêt aléatoire se compose de nombreux arbres de décision.
Chaque arbre de décision est construit en injectant du caractère aléatoire dans la procédure de génération d'arbre pendant la phase d'apprentissage (par exemple, quel nœud d'arbre sélectionner en premier). Cela conduit à divers arbres de décision - exactement ce que nous voulons.
Voici comment la prédiction fonctionne pour une forêt aléatoire entraînée :
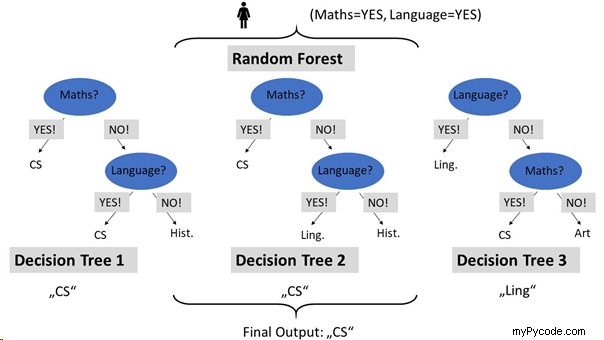
Dans l'exemple, Alice a des maths élevées et langue compétences. L'« ensemble » se compose de trois arbres de décision (construisant une forêt aléatoire). Pour classer Alice, chaque arbre de décision est interrogé sur la classification d'Alice. Deux des arbres de décision classent Alice comme informaticienne . Comme il s'agit de la classe avec le plus de votes, elle est renvoyée comme sortie finale pour la classification.
sklearn.ensemble.RandomForestClassifier
Restons sur cet exemple de classement du domaine d'étude en fonction du niveau de compétence d'un élève dans trois domaines différents (mathématiques, langue, créativité). Vous pensez peut-être que la mise en œuvre d'une méthode d'apprentissage d'ensemble est compliquée en Python. Mais ce n'est pas le cas, grâce à la bibliothèque complète scikit-learn :
## Dependencies
import numpy as np
from sklearn.ensemble import RandomForestClassifier
## Data: student scores in (math, language, creativity) --> study field
X = np.array([[9, 5, 6, "computer science"],
[5, 1, 5, "computer science"],
[8, 8, 8, "computer science"],
[1, 10, 7, "literature"],
[1, 8, 1, "literature"],
[5, 7, 9, "art"],
[1, 1, 6, "art"]])
## One-liner
Forest = RandomForestClassifier(n_estimators=10).fit(X[:,:-1], X[:,-1])
## Result & puzzle
students = Forest.predict([[8, 6, 5],
[3, 7, 9],
[2, 2, 1]])
print(students) Faites une supposition : quel est le résultat de cet extrait de code ?
Après avoir initialisé les données d'apprentissage étiquetées, le code crée une forêt aléatoire en utilisant le constructeur sur la classe RandomForestClassifier avec un paramètre n_estimators qui définit le nombre d'arbres dans la forêt.
Ensuite, on remplit le modèle qui résulte de l'initialisation précédente (une forêt vide) en appelant la fonction fit() . À cette fin, les données d'entraînement d'entrée se composent de toutes les colonnes sauf la dernière du tableau X , tandis que les étiquettes des données d'apprentissage sont définies dans la dernière colonne. Comme dans les exemples précédents, nous utilisons le découpage en tranches pour extraire les colonnes respectives du tableau de données X .
Tutoriel associé : Introduction au découpage en Python
La partie classification est légèrement différente dans cet extrait de code. Je voulais vous montrer comment classer plusieurs observations au lieu d'une seule. Vous pouvez simplement y parvenir ici en créant un tableau multidimensionnel avec une ligne par observation.
Voici la sortie du code :
## Result & puzzle
students = Forest.predict([[8, 6, 5],
[3, 7, 9],
[2, 2, 1]])
print(students)
# ['computer science' 'art' 'art']
Notez que le résultat est toujours non déterministe (ce qui signifie que le résultat peut être différent pour différentes exécutions du code) car l'algorithme de forêt aléatoire repose sur le générateur de nombres aléatoires qui renvoie différents nombres à différents moments. Vous pouvez rendre cet appel déterministe en utilisant l'argument random_state .
Méthodes RandomForestClassifier
Le RandomForestClassifier objet a les méthodes suivantes (source):
apply(X) | Appliquer des arbres dans la forêt à X et renvoie les index des feuilles. |
decision_path(X) | Renvoyer le chemin de décision dans la forêt. |
fit(X, y[, sample_weight]) | Construire une forêt d'arbres à partir de l'ensemble d'apprentissage (X, y) . |
get_params([deep]) | Obtenir les paramètres de cet estimateur. |
predict(X) | Classe de prédiction pour X . |
predict_log_proba(X) | Prédire les probabilités de log de classe pour X . |
predict_proba(X) | Prédire les probabilités de classe pour X . |
score(X, y[, sample_weight]) | Renvoyer la précision moyenne sur les données de test et les étiquettes données. |
set_params(**params) | Définir les paramètres de cet estimateur. |
Pour connaître les différents arguments du RandomForestClassifier() constructeur, n'hésitez pas à consulter la documentation officielle. Cependant, les arguments par défaut sont souvent suffisants pour créer de puissants méta-modèles de classification.