Ce tutoriel est tiré de mon livre The Art of Clean Code (NoStarch 2022):
L'art du code propre

La plupart des développeurs de logiciels perdent des milliers d'heures à travailler avec du code trop complexe. Les huit principes fondamentaux de The Art of Clean Coding vous apprendront à écrire un code clair et maintenable sans compromettre les fonctionnalités. Le principe directeur du livre est la simplicité :réduisez et simplifiez, puis réinvestissez de l'énergie dans les parties importantes pour vous faire gagner d'innombrables heures et faciliter la tâche souvent onéreuse de maintenance du code.
- Concentrez-vous sur l'essentiel avec le principe 80/20 — concentrez-vous sur les 20 % de votre code qui comptent le plus
- Évitez de coder de manière isolée :créez un produit minimum viable pour obtenir des commentaires rapides
- Écrivez le code proprement et simplement pour éliminer l'encombrement
- Éviter une optimisation prématurée qui risque de trop compliquer le code
- Équilibrez vos objectifs, vos capacités et vos commentaires pour atteindre l'état productif de Flow
- Appliquez le bien faire une chose philosophie pour améliorer considérablement la fonctionnalité
- Concevez des interfaces utilisateur efficaces avec Moins c'est plus principe
- Regroupez vos nouvelles compétences en un seul principe unificateur :Concentrez-vous
L'art du codage propre basé sur Python convient aux programmeurs de tous niveaux, avec des idées présentées de manière indépendante du langage.
Écrire un code clair et simple
Histoire :J'ai appris à me concentrer sur l'écriture de code propre à la dure.
L'un de mes projets de recherche pendant ma période de doctorat en systèmes distribués était de coder à partir de zéro un système de traitement de graphes distribués.
Le système vous permettait d'exécuter des algorithmes de graphes tels que le calcul du chemin le plus court sur une grande carte dans un environnement distribué pour accélérer le calcul entre plusieurs machines.
Si vous avez déjà écrit une application distribuée dans laquelle deux processus résidant sur des ordinateurs différents interagissent via des messages, vous savez que la complexité peut rapidement devenir écrasante.
Mon code comportait des milliers de lignes de code et des bogues apparaissaient fréquemment. Je n'ai fait aucun progrès pendant des semaines, c'était très frustrant.
En théorie, les concepts que j'ai développés sonnaient bien et étaient convaincants. Mais la pratique m'a eu!
Finalement, après environ un mois à travailler à plein temps sur la base de code sans voir de progrès encourageants, j'ai décidé de simplifier radicalement la base de code.
- J'ai commencé à utiliser des bibliothèques au lieu de coder moi-même des fonctions.
- J'ai supprimé de gros blocs de code d'optimisations prématurées (voir plus loin).
- J'ai supprimé les blocs de code que j'avais commentés pour une éventuelle utilisation ultérieure.
- J'ai refactorisé les noms de variables et de fonctions. J'ai structuré le code en unités logiques et classes.
Et, après environ une semaine, non seulement mon code était plus lisible et compréhensible par d'autres chercheurs, mais il était aussi plus efficace et moins bogué. J'ai réussi à progresser à nouveau et ma frustration s'est rapidement transformée en enthousiasme :un code propre avait sauvé mon projet de recherche !
Complexité :Dans les chapitres précédents, vous avez appris à quel point la complexité est néfaste pour tout projet de code dans le monde réel.
La complexité tue votre productivité, votre motivation et votre temps. Parce que la plupart d'entre nous n'ont pas appris à parler en code source dès le plus jeune âge, cela peut rapidement submerger nos capacités cognitives.
Plus vous avez de code, plus cela devient écrasant. Mais même les extraits de code courts et les algorithmes peuvent être compliqués.
L'extrait de code en une ligne suivant de notre livre Python One-Liners est un excellent exemple de code source court et concis mais toujours complexe !
# Quicksort algorithm to sort a list of integers
unsorted = [33, 2, 3, 45, 6, 54, 33]
q = lambda l: q([x for x in l[1:] if x <= l[0]]) + [l[0]] +
q([x for x in l if x > l[0]]) if l else []
print(q(unsorted))
# [2, 3, 6, 33, 33, 45, 54]
Vous pouvez trouver une explication de cet extrait de code dans notre livre Python One-Liners ou en ligne sur https://blog.finxter.com/python-one-line-quicksort/.
La complexité provient de nombreuses directions lorsque vous travaillez avec du code source. Cela ralentit notre compréhension du code.
Et cela augmente le nombre de bogues dans notre code. Une compréhension lente et plus de bogues augmentent les coûts du projet et le nombre d'heures de travail nécessaires pour le terminer.
Robert C. Martin, auteur du livre Clean Code , affirme que plus il est difficile de lire et de comprendre le code, plus les coûts d'écriture du code sont également élevés :
"En effet, le rapport entre le temps passé à lire et à écrire est bien supérieur à 10 pour 1. Nous lisons constamment de l'ancien code dans le cadre de l'effort d'écriture de nouveau code. … [Par conséquent,] rendre la lecture facile facilite l'écriture. » — Robert C. Martin
Cette relation est visualisée dans la Figure 5-1 .
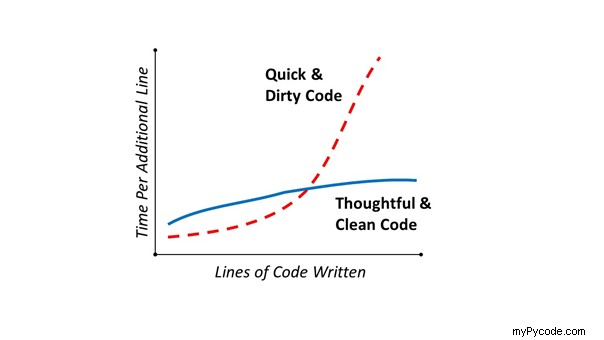
L'axe des x correspond au nombre de lignes écrites dans un projet de code donné. L'axe des ordonnées correspond au temps d'écriture d'une ligne de code supplémentaire.
En général, plus vous avez déjà écrit de code dans un projet, plus il faut de temps pour écrire une ligne de code supplémentaire.
Pourquoi donc? Disons que vous avez écrit n lignes de code et que vous ajoutez le n+1
er
ligne de code. L'ajout de cette ligne peut avoir un effet sur potentiellement toutes les lignes précédemment écrites.
- Cela peut entraîner une petite pénalité de performances qui a un impact sur l'ensemble du projet.
- Il peut utiliser une variable définie à un autre endroit.
- Cela peut introduire un bogue (avec probabilité c ) et pour trouver ce bogue, vous devez rechercher l'ensemble du projet (donc, vos coûts prévus par ligne de code sont c * T(n) pour une fonction régulièrement croissante T avec une entrée croissante n ).
- Cela peut vous obliger à écrire des lignes de code supplémentaires pour assurer la rétrocompatibilité.
Il y a bien d'autres raisons, mais vous avez compris :plus la complexité supplémentaire ralentit votre progression, plus vous avez écrit de code.
Mais la figure 5-1 montre également la différence entre l'écriture de code sale et propre. Si écrire du code sale n'apportait aucun avantage, personne ne le ferait !
Il y a un avantage très réel à écrire du code sale :cela prend moins de temps à court terme et pour les petits projets de code. Si vous entasser toutes les fonctionnalités dans un script de code de 100 lignes, vous n'avez pas besoin d'investir beaucoup de temps pour réfléchir et structurer votre projet.
Mais à mesure que vous ajoutez de plus en plus de code, le fichier de code monolithique passe de 100 à 1000 lignes et à un certain point, il sera beaucoup moins efficace par rapport à une approche plus réfléchie où vous structurez le code logiquement en différents modules, classes, ou fichiers.
👍 Règle d'or :essayez de toujours écrire un code réfléchi et propre, car les coûts supplémentaires liés à la réflexion, à la refactorisation et à la restructuration seront largement remboursés pour tout projet non trivial. De plus, écrire du code propre est juste la bonne chose à faire. La philosophie de l'élaboration soignée de votre art de la programmation vous mènera plus loin dans la vie.
Vous ne connaissez pas toujours les conséquences de second ordre de votre code. Pensez au vaisseau spatial en mission vers Vénus en 1962 où un petit bug - une omission d'un trait d'union dans le code source - a poussé les ingénieurs de la NASA à émettre une commande d'autodestruction qui a entraîné la perte de la fusée d'une valeur de plus de 18 millions de dollars à l'heure.
Pour atténuer tous ces problèmes, il existe une solution simple :écrire un code plus simple.
Un code simple est moins sujet aux erreurs, moins encombré, plus facile à saisir et plus facile à entretenir.
C'est plus amusant à lire et à écrire.
Dans de nombreux cas, il est plus efficace et prend moins de place.
Cela facilite également la mise à l'échelle de votre projet car les gens ne seront pas effrayés par la complexité du projet.
Si de nouveaux codeurs jettent un coup d'œil dans votre projet de code pour voir s'ils veulent contribuer, ils feraient mieux de croire qu'ils peuvent le comprendre. Avec un code simple, tout dans votre projet deviendra plus simple.
Vous progresserez plus rapidement, bénéficierez de plus d'assistance, passerez moins de temps à déboguer, serez plus motivé et vous vous amuserez davantage.
Alors, apprenons à écrire du code propre et simple, d'accord ?
Le code propre est élégant et agréable à lire. Il est focalisé dans le sens où chaque fonction, classe, module se focalise sur une idée.
Une fonction transfer_funds(A,B) dans votre application bancaire fait exactement cela :transférer des fonds du compte A au compte B . Il ne vérifie pas le crédit de l'expéditeur A —pour cela, il y a une autre fonction check_credit(A) . Simple mais facile à comprendre et ciblé.
Comment obtenir un code simple et propre ? En consacrant du temps et des efforts à éditer et réviser le code. C'est ce qu'on appelle le refactoring et il doit s'agir d'un élément planifié et crucial de votre processus de développement logiciel.
Plongeons-nous dans quelques principes pour écrire du code propre. Revoyez-les de temps en temps, ils deviendront significatifs tôt ou tard si vous êtes impliqué dans des projets concrets.
Principes pour écrire du code propre

Ensuite, vous apprendrez un certain nombre de principes qui vous aideront à écrire du code plus propre.
Principe 1 :vous n'en aurez pas besoin
Le principe suggère que vous ne devriez jamais implémenter de code si vous vous attendez seulement à avoir besoin de sa fonctionnalité fournie un jour dans le futur, car vous n'en aurez pas besoin ! Au lieu de cela, écrivez du code uniquement si vous êtes sûr à 100 % que vous en avez besoin. Codez pour les besoins d'aujourd'hui et non ceux de demain.
Il est utile de penser à partir des premiers principes :le code le plus simple et le plus propre est le fichier vide. Il n'y a pas de bug et c'est facile à comprendre. Maintenant, partez de là - que devez-vous ajouter à cela ? Au chapitre 4, vous avez appris le produit minimum viable. Si vous minimisez le nombre de fonctionnalités que vous recherchez, vous récolterez un code plus propre et plus simple que vous ne pourriez jamais atteindre grâce à des méthodes de refactoring ou à tous les autres principes combinés. Comme vous le savez maintenant, omettre des fonctionnalités n'est pas seulement utile si elles sont inutiles. Les laisser de côté est même logique s'ils offrent relativement peu de valeur par rapport à d'autres fonctionnalités que vous pourriez implémenter à la place. Les coûts d'opportunité sont rarement mesurés mais le plus souvent ils sont très importants. Ce n'est pas parce qu'une fonctionnalité offre certains avantages que sa mise en œuvre est justifiée. Vous devez vraiment avoir besoin de la fonctionnalité avant même d'envisager de l'implémenter. Récoltez d'abord les fruits à portée de main avant d'atteindre plus haut !
Principe 2 :le principe de la moindre surprise
Ce principe est l'une des règles d'or d'une conception efficace des applications et de l'expérience utilisateur. Si vous ouvrez le moteur de recherche Google, le curseur sera déjà concentré dans le champ de saisie de la recherche afin que vous puissiez commencer à taper votre mot-clé de recherche immédiatement sans avoir à cliquer dans le champ de saisie. Pas surprenant du tout, mais un excellent exemple du principe de moindre surprise. Un code propre tire également parti de ce principe de conception. Supposons que vous écriviez un convertisseur de devises qui convertit l'entrée de l'utilisateur d'USD en RMB. Vous stockez l'entrée utilisateur dans une variable. Quel nom de variable est le mieux adapté, user_input ou var_x ? Le principe de moindre surprise répond à cette question pour vous !
Principe 3 :Ne vous répétez pas
Ne vous répétez pas (DRY) est un principe largement reconnu qui implique que si vous écrivez du code qui se répète partiellement - ou qui est même copié-collé à partir de votre propre code - est un signe de mauvais style de codage. Un exemple négatif est le code Python suivant qui imprime cinq fois la même chaîne dans le shell :
print('hello world')
print('hello world')
print('hello world')
print('hello world')
print('hello world') Le code se répète donc le principe suggère qu'il y aura une meilleure façon de l'écrire. Et il y en a !
for i in range(5):
print('hello world')
Le code est beaucoup plus court mais sémantiquement équivalent. Il n'y a pas de redondance dans le code.
Le principe vous montre également quand créer une fonction et quand il n'est pas nécessaire de le faire. Supposons que vous deviez convertir des miles en kilomètres à plusieurs reprises dans votre code (voir Liste 5-1 ).
miles = 100 kilometers = miles * 1.60934 # ... # BAD EXAMPLE distance = 20 * 1.60934 # ... print(kilometers) print(distance) ''' OUTPUT: 160.934 32.1868 '''
Liste 5-1 : Convertissez les miles en kilomètres deux fois.
Le principe Ne vous répétez pas suggère qu'il serait préférable d'écrire une fonction miles_to_km(miles) une fois—plutôt que d'effectuer plusieurs fois la même conversion explicitement dans le code (voir Liste 5-2 ).
def miles_to_km(miles):
return miles * 1.60934
miles = 100
kilometers = miles_to_km(miles)
# ...
distance = miles_to_km(20)
# ...
print(kilometers)
print(distance)
'''
OUTPUT:
160.934
32.1868
'''
Liste 5-2 : Utilisation d'une fonction pour convertir des miles en kilomètres.
De cette façon, le code est plus facile à maintenir, vous pouvez facilement augmenter la précision de la conversion par la suite sans rechercher dans le code toutes les instances où vous avez utilisé la méthodologie de conversion imprécise.
De plus, il est plus facile à comprendre pour les lecteurs humains de votre code. Il n'y a aucun doute sur le but de la fonction miles_to_km(20) tandis que vous devrez peut-être réfléchir davantage au but du calcul 20 * 1.60934.
Le principe Ne vous répétez pas est souvent abrégé en DRY et ses violations en WET :We Enjoy Typing , Écrivez tout deux fois , et perdre le temps de tout le monde .
Principe 4 :Coder pour les personnes et non les machines
Le but principal du code source est de définir ce que les machines doivent faire et comment le faire. Pourtant, si c'était le seul critère, vous utiliseriez un langage machine de bas niveau tel que l'assembleur pour atteindre cet objectif car c'est le langage le plus expressif et le plus puissant.
Le but des langages de programmation de haut niveau tels que Python est d'aider les gens à écrire un meilleur code et à le faire plus rapidement. Notre prochain principe pour un code propre est de vous rappeler constamment que vous écrivez du code pour d'autres personnes et non pour des machines. Si votre code a un impact dans le monde réel, il sera lu plusieurs fois par vous ou par un programmeur qui prend votre place si vous arrêtez de travailler sur la base de code.
Supposez toujours que votre code source sera lu par d'autres personnes. Que pouvez-vous faire pour faciliter leur travail ? Ou, pour le dire plus clairement :que pouvez-vous faire pour atténuer les émotions négatives qu'ils ressentiront contre le programmeur original du code sur lequel ils travaillent ?
Code pour les personnes et non pour les machines ! 🧔
Qu'est-ce que cela signifie en pratique ? Il y a de nombreuses implications. Tout d'abord, utilisez des noms de variables significatifs. Listing 5-3 montre un exemple négatif sans noms de variables significatifs.
# BAD
xxx = 10000
yyy = 0.1
zzz = 10
for iii in range(zzz):
print(xxx * (1 + yyy)**iii)
Liste 5-3 : Exemple d'écriture de code pour les machines.
Devinez :que calcule le code ?
Examinons le code sémantiquement équivalent dans le Listing 5-4 qui utilise des noms de variables significatifs.
# GOOD
investments = 10000
yearly_return = 0.1
years = 10
for year in range(years):
print(investments * (1 + yearly_return)**year)
Liste 5-4 : Utilisation d'une fonction pour convertir des miles en kilomètres.
Les noms des variables indiquent que vous calculez la valeur d'un investissement initial de 1 000 composé sur 10 ans en supposant un rendement annuel de 10 %.
Le principe d'écrire du code a bien d'autres applications. Cela s'applique également aux indentations, aux espaces blancs, aux commentaires et aux longueurs de ligne. Un code propre optimise radicalement la lisibilité humaine. Comme l'affirme Martin Fowler, expert international en génie logiciel et auteur du célèbre livre Refactoring :
"N'importe quel imbécile peut écrire du code qu'un ordinateur peut comprendre. Les bons programmeurs écrivent du code que les humains peuvent comprendre."
Principe 5 :Tenez-vous sur les épaules de géants
Il ne sert à rien de réinventer la roue. La programmation est une industrie vieille de dix ans, et les meilleurs codeurs du monde nous ont laissé un grand héritage :une base de données collective de millions d'algorithmes et de fonctions de code affinés et bien testés.
Accéder à la sagesse collective de millions de programmeurs est aussi simple que d'utiliser une déclaration d'importation en une seule ligne. Vous seriez fou de ne pas utiliser ce super pouvoir dans vos propres projets.
En plus d'être facile à utiliser, l'utilisation du code de la bibliothèque est susceptible d'améliorer l'efficacité de votre code car les fonctions qui ont été utilisées par des milliers de codeurs ont tendance à être beaucoup plus optimisées que vos propres fonctions de code.
De plus, les appels de bibliothèque sont plus faciles à comprendre et prennent moins de place dans votre projet de code.
Par exemple, si vous avez besoin d'un algorithme de clustering pour visualiser des clusters de clients, vous pouvez soit l'implémenter vous-même, soit vous tenir sur les épaules de géants et importer un algorithme de clustering à partir d'une bibliothèque externe et y transmettre vos données.
Ce dernier est beaucoup plus rapide - vous prendrez beaucoup moins de temps pour implémenter la même fonctionnalité avec moins de bogues, moins d'espace et un code plus performant. Les bibliothèques sont l'une des principales raisons pour lesquelles les codeurs maîtres peuvent être 10 000 fois plus productifs que les codeurs moyens.
Voici les deux lignes qui importent le module KMeans de la bibliothèque Python scikit-learn plutôt que de réinventer la roue :
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
Si vous souhaitez implémenter l'algorithme KMeans, cela vous prendra quelques heures et 50 lignes de code, et cela encombrera votre base de code de sorte que tout le code futur deviendra plus difficile à implémenter.
Principe 6 :Utilisez les bons noms
Vos décisions sur la façon de nommer vos fonctions, arguments de fonction, objets, méthodes et variables révèlent si vous êtes un codeur débutant, intermédiaire ou expert. Comment?
Dans n'importe quel langage de programmation, il existe de nombreuses conventions de dénomination qui sont utilisées par tous les codeurs expérimentés.
Si vous les enfreignez, cela indique immédiatement au lecteur de votre base de code que vous n'avez pas beaucoup d'expérience avec des projets de code pratiques. Plus il y a de tels « dits » dans votre code, moins un lecteur de votre code le prendra au sérieux.
De nombreuses règles explicites et implicites régissent la dénomination correcte de vos éléments de code. Ces règles peuvent même différer d'un langage de programmation à l'autre.
Par exemple, vous utiliserez camelCaseNaming pour les variables dans le langage de programmation Java pendant que vous utiliserez underscore_naming en Python.
Si vous commencez à utiliser camel case en Python, tout le monde verra immédiatement que vous êtes un débutant en Python. Bien que vous n'aimiez peut-être pas cela, ce n'est pas vraiment un gros problème d'être perçu comme un débutant - tout le monde l'a été à un moment donné. Bien pire, les autres codeurs seront négativement surpris lors de la lecture de leur code.
Au lieu de penser à ce que fait le code, ils commencent à réfléchir à la façon dont votre code est écrit. Vous connaissez le principe de la moindre surprise :il ne sert à rien de surprendre les autres codeurs en choisissant des noms de variables non conventionnels.
Plongeons-nous donc dans une liste de règles empiriques de dénomination que vous pouvez prendre en compte lors de l'écriture du code source. Cela accélérera votre capacité à apprendre à écrire des noms de code propres.
Cependant, la meilleure façon d'apprendre est d'étudier le code des personnes qui sont meilleures que vous. Lisez de nombreux didacticiels de programmation, rejoignez la communauté StackOverview et découvrez le code Github des projets open source.
- Choisissez des noms descriptifs. Supposons que vous créez une fonction pour convertir des devises de l'USD à l'EUR en Python. Appelez-le
usd_to_eur(amount)plutôt quef(x). - Choisissez des noms sans ambiguïté. Vous pensez peut-être que
dollar_to_euro(amount)serait également un bon nom pour la fonction discutée précédemment. Alors que c'est mieux quef(x), c'est pire queusd_to_eur(amount)parce qu'il introduit un degré inutile d'ambiguïté. Voulez-vous dire dollar américain, canadien ou australien ? Si vous êtes aux États-Unis, la réponse peut être évidente pour vous. Mais un codeur australien peut ne pas savoir que le code est écrit aux États-Unis et peut supposer une sortie différente. Minimisez ces confusions ! - Utilisez des noms prononçables. La plupart des codeurs lisent inconsciemment le code en le prononçant mentalement. S'ils ne peuvent pas le faire inconsciemment parce qu'un nom de variable est imprononçable, le problème du déchiffrement du nom de la variable retient leur précieuse attention. Ils doivent réfléchir activement aux moyens possibles de résoudre la dénomination inattendue. Par exemple, le nom de la variable
cstmr_lstpeut être descriptif et sans ambiguïté, mais il n'est pas prononçable. Choix du nom de la variablecustomer_listvaut bien l'espace supplémentaire dans votre code ! - Utilisez des constantes nommées, pas des nombres magiques . Dans votre code, vous pouvez utiliser le nombre magique 0,9 plusieurs fois comme facteur pour convertir une somme en USD en une somme en EUR. Cependant, le lecteur de votre code - y compris votre futur moi qui relit votre propre code - doit réfléchir à l'objectif de ce numéro. Ce n'est pas explicite. Une bien meilleure façon de gérer ce "nombre magique" 0.9 est de le stocker dans une variable
CONVERSION_RATE = 0.9et utilisez-le comme facteur dans vos calculs de conversion. Par exemple, vous pouvez alors calculer votre revenu en EUR commeincome_euro = CONVERSION_RATE * income_usd. De cette façon, il n'y a pas de chiffre magique dans votre code et il devient plus lisible.
Ce ne sont là que quelques-unes des conventions de dénomination. Encore une fois, pour récupérer les conventions, il est préférable de les rechercher une fois sur Google (par exemple, "Python Naming Conventions") et d'étudier les projets de code Github d'experts dans votre domaine.
Principe 7 :principe de responsabilité unique
Le principe de responsabilité unique signifie que chaque fonction a une tâche principale. Une fonction doit être petite et ne faire qu'une seule chose. Il vaut mieux avoir plusieurs petites fonctions qu'une grande fonction faisant tout en même temps. La raison est simple :l'encapsulation des fonctionnalités réduit la complexité globale de votre code.
En règle générale :chaque classe et chaque fonction ne devrait avoir qu'une seule raison de changer.
S'il y a plusieurs raisons de changer, plusieurs programmeurs aimeraient changer la même classe en même temps. Vous avez mélangé trop de responsabilités dans votre classe et maintenant cela devient désordonné et encombré.
Considérons un petit exemple utilisant du code Python qui peut s'exécuter sur un lecteur d'ebook pour modéliser et gérer l'expérience de lecture d'un utilisateur (voir Liste 5-5 ).
class Book:
def __init__(self):
self.title = "Python One-Liners"
self.publisher = "NoStarch"
self.author = "Mayer"
self.current_page = 0
def get_title(self):
return self.title
def get_author(self):
return self.author
def get_publisher(self):
return self.publisher
def next_page(self):
self.current_page += 1
return self.current_page
def print_page(self):
print(f"... Page Content {self.current_page} ...")
python_one_liners = Book()
print(python_one_liners.get_publisher())
# NoStarch
python_one_liners.print_page()
# ... Page Content 0 ...
python_one_liners.next_page()
python_one_liners.print_page()
# ... Page Content 1 ...
Liste 5-5 : Modélisation de la classe de livre avec violation du principe de responsabilité unique - la classe de livre est responsable à la fois de la modélisation des données et de la représentation des données. Il a deux responsabilités.
Le code dans la Liste 5-5 définit une classe Book avec quatre attributs :titre, auteur, éditeur et numéro de page en cours.
Vous définissez des méthodes getter pour les attributs, ainsi que quelques fonctionnalités minimales pour passer à la page suivante.
La fonction next_page() peut être appelé chaque fois que l'utilisateur appuie sur un bouton de l'appareil de lecture. Une autre fonction print_page() est responsable de l'impression de la page en cours sur le dispositif de lecture.
Ceci n'est donné qu'à titre indicatif et ce sera plus compliqué dans le monde réel. Bien que le code semble clair et simple, il enfreint le principe de responsabilité unique :la classe Book est responsable de la modélisation des données telles que le contenu du livre, mais elle est également responsable de l'impression du livre sur l'appareil. Vous avez plusieurs raisons de changer.
Vous souhaiterez peut-être modifier la modélisation des données du livre, par exemple en utilisant une base de données au lieu d'une méthode d'entrée/sortie basée sur des fichiers. Mais vous pouvez également souhaiter modifier la représentation des données modélisées, par exemple, en utilisant un autre schéma de formatage de livre sur d'autres types d'écrans.
La modélisation et l'impression sont deux fonctions différentes encapsulées dans une seule classe. Changeons cela dans Listing 5-6 !
class Book:
def __init__(self):
self.title = "Python One-Liners"
self.publisher = "NoStarch"
self.author = "Mayer"
self.current_page = 0
def get_title(self):
return self.title
def get_author(self):
return self.author
def get_publisher(self):
return self.publisher
def get_page(self):
return self.current_page
def next_page(self):
self.current_page += 1
class Printer:
def print_page(self, book):
print(f"... Page Content {book.get_page()} ...")
python_one_liners = Book()
printer = Printer()
printer.print_page(python_one_liners)
# ... Page Content 0 ...
python_one_liners.next_page()
printer.print_page(python_one_liners)
# ... Page Content 1 ...
Liste 5-6 : Adhérant au principe de responsabilité unique, la classe livre est responsable de la modélisation des données et la classe impression est responsable de la représentation des données.
Le code dans la Liste 5-6 accomplit la même tâche mais satisfait au principe de responsabilité unique. Vous créez à la fois un livre et une classe d'imprimante.
La classe book représente les méta-informations du livre et le numéro de page actuel.
La classe d'imprimante imprime le livre sur le périphérique. Vous passez le livre dont vous voulez imprimer la page en cours dans la méthode Printer.print_page() .
De cette façon, la modélisation des données et la représentation des données sont découplées et le code devient plus facile à maintenir.
L'art du code propre
La plupart des développeurs de logiciels perdent des milliers d'heures à travailler avec du code trop complexe. Les huit principes fondamentaux de The Art of Clean Coding vous apprendront à écrire un code clair et maintenable sans compromettre les fonctionnalités. Le principe directeur du livre est la simplicité :réduisez et simplifiez, puis réinvestissez de l'énergie dans les parties importantes pour vous faire gagner d'innombrables heures et faciliter la tâche souvent onéreuse de maintenance du code.
- Concentrez-vous sur l'essentiel avec le principe 80/20 — concentrez-vous sur les 20 % de votre code qui comptent le plus
- Évitez de coder de manière isolée :créez un produit minimum viable pour obtenir des commentaires rapides
- Écrivez le code proprement et simplement pour éliminer l'encombrement
- Éviter une optimisation prématurée qui risque de trop compliquer le code
- Équilibrez vos objectifs, vos capacités et vos commentaires pour atteindre l'état productif de Flow
- Appliquez le bien faire une chose philosophie pour améliorer considérablement la fonctionnalité
- Concevez des interfaces utilisateur efficaces avec Moins c'est plus principe
- Regroupez vos nouvelles compétences en un seul principe unificateur :Concentrez-vous
L'art du codage propre basé sur Python convient aux programmeurs de tous niveaux, avec des idées présentées de manière indépendante du langage.
Voulez-vous développer les compétences d'un professionnel Python complet —tout en étant payé dans le processus ? Devenez freelance Python et commandez votre livre Leaving the Rat Race with Python sur Amazon (Kindle/Print ) !

Références
- https://code.tutsplus.com/tutorials/solid-part-1-the-single-responsibility-principle--net-36074
- https://en.wikipedia.org/wiki/Single-responsibility_principle
- https://medium.com/hackernoon/the-secret-behind-the-single-responsibility-principle-e2f3692bae25
- https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8263157&casa_token=Ydc5j4wwdWAAAAAA:iywl9VJ_TRe_Q3x2F7-XOgKHvrnz7TuJhBQ8iDtsSVDv1WXTGN-bCSscP0WjSs7X7LVXJFGNfgM&tag=1
- https://raygun.com/blog/costly-software-errors-history/