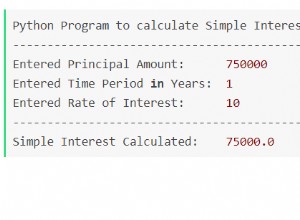
Résumé :téléchargez un fichier sur le Web en procédant comme suit dans Python.
- Importer la bibliothèque
requests - Définir la chaîne d'URL
- Obtenir les données du fichier à partir de l'URL
- Stocker les données du fichier dans un objet fichier sur votre ordinateur
Voici comment procéder pour télécharger le favicon Facebook (source) :
Au début de notre lutte avec le web scraping, vous pourriez avoir des difficultés à télécharger des fichiers en utilisant Python. Cependant, cet article vous fournira plusieurs méthodes que vous pouvez utiliser pour télécharger, par exemple, la couverture d'un livre à partir de la page.
A titre d'exemple, nous utiliserons des pages qui n'interdisent pas le scraping :http://books.toscrape.com/catalogue/category/books_1/index.html
Comment vérifier ce que je suis autorisé à supprimer ?
Pour vérifier exactement ce que vous n'êtes pas autorisé à supprimer, vous devez ajouter "robots.txt" à la fin dans l'url de la page. Cela devrait ressembler à ceci :https://www.google.com/robots.txt. Si la page ne précise pas ce qui peut être supprimé, vous devez vérifier sa feuille de conditions.
Bon, fin de l'introduction, commençons !
Comment installer des modules en Python ?
Avant de pouvoir utiliser une méthode, vous devez d'abord installer le module (si vous ne l'avez pas) en utilisant :
pip install module_name
Par exemple :
pip install requests
Comment obtenir un lien vers le fichier ?
Pour obtenir un lien vers le fichier, naviguez avec le curseur et faites un clic droit sur tout ce que vous recherchez et appuyez sur "Inspecter l'élément":
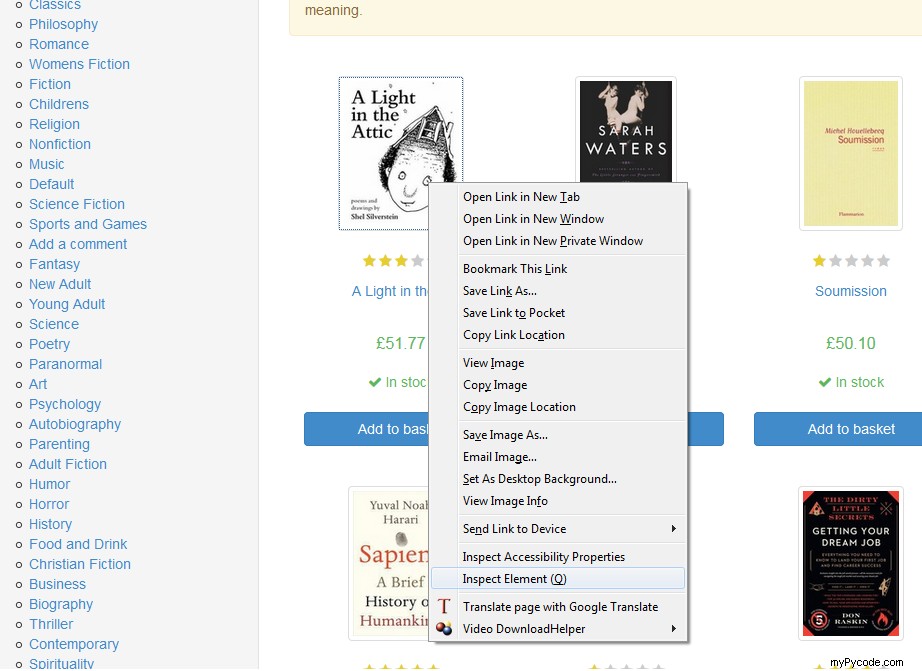
Ensuite, le code source de la page apparaîtra et indiquera immédiatement l'élément qui nous intéresse :
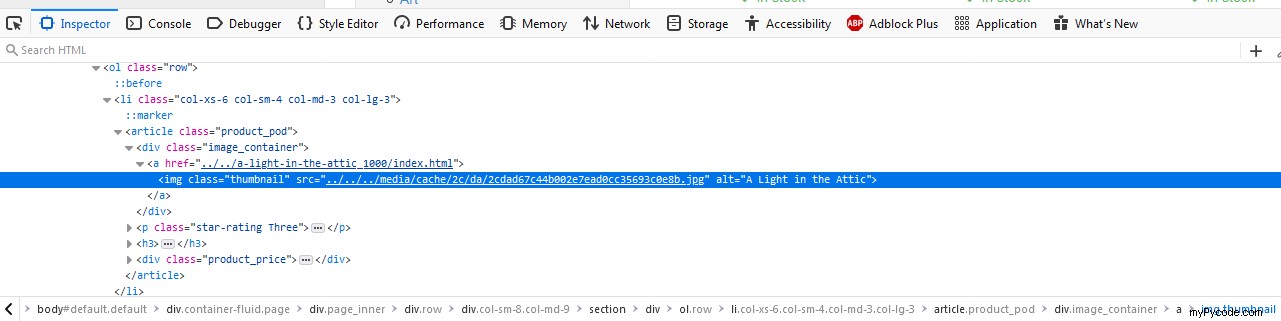
Ensuite, nous devons copier le lien vers ce fichier :
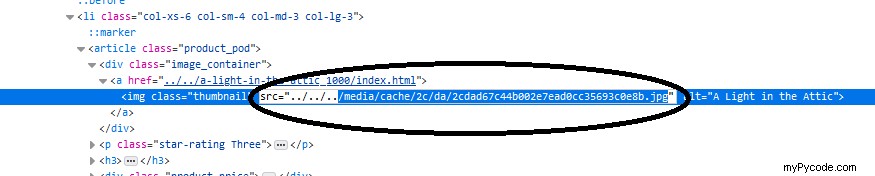
En fonction de l'apparence du lien (qu'il soit plein ou non [sinon, nous devons le préparer pour l'utiliser]), nous le collons dans la barre de recherche, pour vérifier si c'est ce que nous voulons :

Et si c'est le cas, nous utilisons l'une des méthodes fournies.
Méthode 1 - module de requêtes
Nous devons d'abord importer le module de requêtes, puis créer des variables.
import requests url_to_the_file = 'http://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg' r = requests.get(url_to_the_file)
Une fois que nous avons créé les variables, nous devons ouvrir le fichier en mode d'écriture binaire et enregistrer notre fichier sous un nom avec l'extension qui correspond au fichier que nous voulons télécharger (si nous voulons télécharger une photo, l'extension doit être par exemple jpg).
with open('A light in the attic – book cover.jpg', 'wb') as f:
f.write(r.content)
Code complet :
import requests
url_to_the_file = 'http://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg'
r = requests.get(url_to_the_file)
with open('A light in the attic – book cover.jpg', 'wb') as f:
f.write(r.content)
Une fois le code exécuté, l'image apparaîtra dans le répertoire de travail actuel. Avec cette méthode, nous pouvons facilement télécharger une seule image, mais que se passe-t-il si nous voulons télécharger plusieurs fichiers à la fois ? Passons à la méthode suivante pour l'apprendre !
Méthode 2 - Module de requêtes et classe Beautifulsoup du module bs4
Si vous souhaitez télécharger plusieurs fichiers à partir d'une même page, cette méthode est idéale. Au début nous importons le requests et bs4 modules (dont nous prenons la classe BeautifulSoup) et créer des variables :
- url – lien vers la page à partir de laquelle vous souhaitez télécharger des fichiers,
- résultat – lien vers la page et son code html,
- soupe - objet de classe BeautifulSoup (nous l'utilisons pour trouver des éléments),
- data - les données qui nous intéressent, dans ce cas les lignes de code html qui commencent par et se terminent par (ces lignes de code ont un attribut href qui a un lien vers quelque chose).
import requests
from bs4 import BeautifulSoup
url = 'https://telugump3audio.com/devi-1999-songs.html'
result = requests.get(url).content
soup = BeautifulSoup(result, 'html.parser')
data = soup.find_all('a') Ensuite, nous devons écrire une fonction qui vérifie si les liens ont l'extension mp3, puis la même fonction télécharge les fichiers avec cette extension :
def get_mp3_files(data_):
links = []
names_of_mp3_files = []
for link in data_:
if '.mp3' in link['href']:
print(link['href'])
links.append(link['href'])
names_of_mp3_files.append(link.text)
if len(names_of_mp3_files) == 0:
raise Exception
else:
for place in range(len(links)):
with open(names_of_mp3_files[place], 'wb') as f:
content = requests.get(links[place]).content
f.write(content)
Code complet :
import requests
from bs4 import BeautifulSoup
def get_mp3_files(data_):
links = []
names_of_mp3_files = []
for link in data_:
if '.mp3' in link['href']:
print(link['href'])
links.append(link['href'])
names_of_mp3_files.append(link.text)
if len(names_of_mp3_files) == 0:
raise Exception
else:
for place in range(len(links)):
with open(names_of_mp3_files[place], 'wb') as f:
content = requests.get(links[place]).content
f.write(content)
url = 'https://telugump3audio.com/devi-1999-songs.html'
result = requests.get(url).content
soup = BeautifulSoup(result, 'html.parser')
data = soup.find_all('a')
get_mp3_files(data) En utilisant cette méthode, nous pouvons même télécharger des dizaines de fichiers !
Méthode 3 – Module urllib
Le module urllib est fourni par défaut en Python, vous n'avez donc pas besoin de l'installer avant utilisation.
Tout d'abord, nous importons urllib.request , car il contient le urlretrieve() fonction, qui nous permet de télécharger des images ou des fichiers musicaux. Cette fonction a 4 arguments (1 obligatoire et 3 optionnels), cependant les deux premiers sont les plus importants :
- url – lien vers le fichier que vous souhaitez obtenir,
- filename – le nom sous lequel vous souhaitez enregistrer le fichier.
import urllib.request
url = 'http://books.toscrape.com/media/cache/' \
'2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg'
file_name = 'A light in the attic.jpg'
urllib.request.urlretrieve(url, filename)
Remarque : Selon la documentation, urllib.request.urlretrieve est une "interface héritée" et "pourrait devenir obsolète à l'avenir"
Cependant, il existe un autre moyen de télécharger le fichier à l'aide de ce module :
import urllib.request
url = 'http://books.toscrape.com/media/cache/' \
'2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg'
file_name = 'A light in the attic.jpg'
response = urllib.request.urlopen(url)
html = response.read()
with open(filename, 'wb') as f:
f.write(html)
En utilisant cette méthode, nous importons également urllib.request , mais nous utilisons d'autres fonctions, d'abord urlopen( ) pour se connecter à la page, puis read() pour enregistrer le code html de la page dans une variable, nous ouvrons ensuite le fichier avec le nom enregistré dans la variable filename et enregistrons le code html du fichier sous forme binaire. De cette façon, nous avons le fichier que nous voulions !
Méthode 4 - Module de téléchargement
- Dans la version Python>=3.6, vous pouvez également utiliser le
dloadmodule pour télécharger un fichier. Lesave()la fonction a 3 arguments (1 obligatoire, 2 optionnels) : url– lien vers le fichier,path– le nom sous lequel vous souhaitez enregistrer votre fichier, si vous ne précisez pas de nom, le nom dépendra de la fin du lien vers le fichier (dans notre cas le fichier s'appellerait2cdad67c44b002e7ead0cc35693c0e8b.jpg, il est donc préférable de préciser votre nom de fichier),overwrite– S'il y a un fichier portant le même nom dans notre répertoire de travail, il l'écrasera, s'il est égal à True, et s'il est False, il ne téléchargera pas le fichier (par défaut =False).
import dload
url = 'http://books.toscrape.com/media/cache/' \
'2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg'
filename = 'A light in the attic.jpg'
dload.save(url, filename)
Résumé
Vous avez appris une explication sur la façon de vérifier si nous avons l'autorisation de télécharger des fichiers. Vous avez appris qu'il existe 4 méthodes de téléchargement de fichiers à l'aide de modules nommés dans l'ordre :requests, requests dans beautifulsoup, urllib dans dload.
J'espère que cet article vous aidera à télécharger tous les fichiers que vous voulez.