Supprimer les doublons d'une liste est assez simple. Vous pouvez le faire avec un one-liner Python :
>>> initial = [1, 1, 9, 1, 9, 6, 9, 7] >>> result = list(set(initial)) >>> result [1, 7, 9, 6]
Les éléments d'ensemble Python doivent être uniques afin que la conversion d'une liste en un ensemble et inversement permette d'obtenir le résultat souhaité.
Et si l'ordre d'origine de la liste est important ? Cela rend les choses un peu plus compliquées car les ensembles ne sont pas ordonnés, donc une fois la conversion terminée, l'ordre de la liste sera perdu.
Heureusement, il existe plusieurs façons de surmonter ce problème. Dans cet article, nous examinerons une gamme de solutions différentes au problème et examinerons leurs mérites relatifs.
Méthode 1 - Boucle For
Une méthode de base pour obtenir le résultat requis consiste à utiliser une boucle for :
>>> initial = [1, 1, 9, 1, 9, 6, 9, 7]
>>> result = []
>>> for item in initial:
if item not in result:
result.append(item)
>>> result
[1, 9, 6, 7]
Cette approche a au moins l'avantage d'être facile à lire et à comprendre. C'est assez inefficace cependant comme le not i n vérification est en cours pour chaque élément du initial liste.
Ce n'est peut-être pas un problème avec cet exemple simple, mais la surcharge de temps deviendra de plus en plus évidente si la liste devient très longue.
Méthode 2 - Compréhension de la liste
Une alternative consiste à utiliser une compréhension de liste :
>>> initial = [1, 1, 9, 1, 9, 6, 9, 7] >>> result = [] >>> [result.append(item) for item in initial if item not in result] [None, None, None, None] >>> result [1, 9, 6, 7]
Les compréhensions de liste sont des outils Python pratiques et très puissants qui vous permettent de combiner des variables, des boucles for et des instructions if. Ils permettent de créer une liste avec une seule ligne de code (mais vous pouvez aussi les diviser en plusieurs lignes pour améliorer la lisibilité !).
Bien que plus court et toujours assez clair, utiliser une compréhension de liste dans ce cas n'est pas une très bonne idée.
C'est parce qu'il adopte la même approche inefficace des tests d'adhésion que nous avons vu dans la Méthode 1 . Il s'appuie également sur les effets secondaires de la compréhension pour construire la liste des résultats, ce que beaucoup considèrent comme une mauvaise pratique.
Pour expliquer davantage, même si elle n'est pas affectée à une variable pour une utilisation ultérieure, une compréhension de liste crée toujours un objet de liste. Ainsi, lors du processus d'ajout d'éléments de la liste initiale au result list, notre code crée également une troisième liste contenant la valeur de retour de chaque result.append(item) appeler.
Les fonctions Python renvoient la valeur None si aucune autre valeur de retour n'est spécifiée, cela signifie que (comme vous pouvez le voir ci-dessus) le résultat de la troisième liste est :
[None, None, None, None]
Une boucle for est plus claire et ne repose pas sur des effets secondaires, c'est donc la meilleure méthode des deux à cette occasion.
Méthode 3 - Ensemble trié
Nous ne pouvons pas simplement convertir notre liste en un ensemble pour supprimer les doublons si nous voulons préserver l'ordre. Cependant, l'utilisation de cette approche en conjonction avec la fonction triée est une autre voie potentielle :
>>> initial = [1, 1, 9, 1, 9, 6, 9, 7] >>> result = sorted(set(initial), key=initial.index) >>> result [1, 9, 6, 7]
Comme vous pouvez le voir, cette méthode utilise l'index de la liste initiale pour trier l'ensemble des valeurs uniques dans le bon ordre.
Le problème est que même si c'est assez facile à comprendre, ce n'est pas beaucoup plus rapide que la boucle for de base montrée dans la Méthode 1 .
Méthode 4 - Dictionnaire fromkeys()
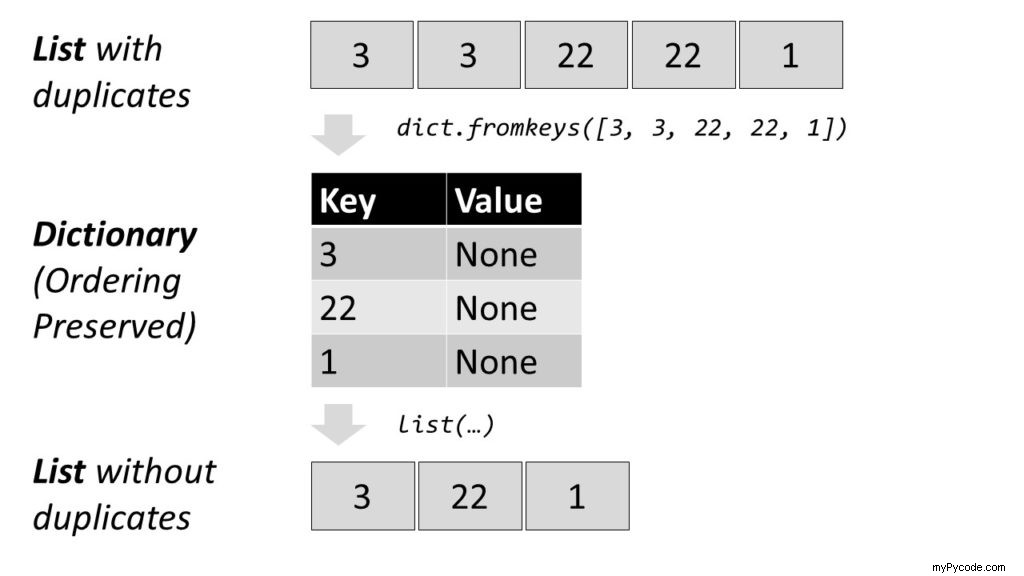
Une approche très rapide consiste à utiliser un dictionnaire :
>>> initial = [1, 1, 9, 1, 9, 6, 9, 7] >>> result = list(dict.fromkeys(initial)) >>> result [1, 9, 6, 7]
Comme les ensembles, les dictionnaires utilisent des tables de hachage, ce qui signifie qu'ils sont extrêmement rapides.
Les clés de dictionnaire Python sont uniques par défaut, donc la conversion de notre liste en dictionnaire supprimera automatiquement les doublons.
Le dict.fromkeys() La méthode crée un nouveau dictionnaire en utilisant les éléments d'un itérable comme clés.
Une fois que cela a été fait avec notre liste initiale, reconvertir le dictionnaire en liste donne le résultat que nous recherchons.
Les dictionnaires n'ont été ordonnés dans toutes les implémentations de python que lorsque Python 3.7 a été publié (il s'agissait également d'un détail d'implémentation de CPython 3.6).
Donc, si vous utilisez une ancienne version de Python, vous devrez importer le OrderedDict classe du package de collections dans la bibliothèque standard à la place :
>>> from collections import OrderedDict >>> initial = [1, 1, 9, 1, 9, 6, 9, 7] >>> result = list(OrderedDict.fromkeys(initial)) >>> result [1, 9, 6, 7]
Cette approche n'est peut-être pas aussi rapide que l'utilisation d'un dictionnaire standard, mais elle reste très rapide !
Exercice : Exécutez le code. Est-ce que ça marche ?
Méthode 5 - plus d'itertools
Jusqu'à présent, nous n'avons examiné que les listes contenant des éléments immuables. Mais que se passe-t-il si votre liste contient des types de données modifiables tels que des listes, des ensembles ou des dictionnaires ?
Il est toujours possible d'utiliser la boucle for de base illustrée dans la Méthode 1 , mais cela ne coupera pas la moutarde si la vitesse est essentielle.
Aussi, si nous essayons d'utiliser dict.fromkeys() nous recevrons un TypeError car les clés du dictionnaire doivent être hachables.
Une excellente réponse à cette énigme se présente sous la forme d'une bibliothèque appelée more-itertools. Il ne fait pas partie de la bibliothèque standard Python, vous devrez donc l'installer par pip.
Cela fait, vous pouvez importer et utiliser son unique_everseen() fonctionner comme ceci :
>>> from more_itertools import unique_everseen >>> mutables = [[1, 2, 3], [2, 3, 4], [1, 2, 3]] >>> result = list(unique_everseen(mutables)) >>> result [[1, 2, 3], [2, 3, 4]]
La bibliothèque more-itertools est conçu spécifiquement pour travailler efficacement avec les types de données itérables de Python (il complète itertools qui FAIT partie de la bibliothèque standard).
La fonction unique_everseen() produit des éléments uniques tout en préservant l'ordre et, surtout, il peut gérer des types de données modifiables, c'est donc exactement ce que nous recherchons.
La fonction permet également de supprimer encore plus rapidement les doublons d'une liste de listes :
... >>> result = list(unique_everseen(mutables, key=tuple)) >>> result [[1, 2, 3], [2, 3, 4]]
Cela fonctionne bien car il convertit les listes non hachables en tuples hachables pour accélérer les choses.
Si vous souhaitez appliquer cette astuce à une liste d'ensembles, vous pouvez utiliser frozenset comme clé :
...
>>> mutables = [{1, 2, 3}, {2, 3, 4}, {1, 2, 3}]
>>> result = list(unique_everseen(mutables, key=frozenset))
>>> result
[{1, 2, 3}, {2, 3, 4}]
Spécifier une clé avec une liste de dictionnaires est un peu plus compliqué, mais peut toujours être réalisé à l'aide d'une fonction lambda :
...
>>> mutables = [{'one': 1}, {'two': 2}, {'one': 1}]
>>> result = list(
unique_everseen(mutables, key=lambda x: frozenset(x.items()))
)
>>> result
[{'one': 1}, {'two': 2}]
La fonction unique_everseen() peut également être utilisé avec des listes contenant un mélange d'éléments itérables et non itérables (pensez aux entiers et aux flottants), ce qui est un vrai plus. Tenter de fournir une clé dans cette instance entraînera un TypeError cependant.
Méthode 6 – NumPy unique()
Si vous travaillez avec des données numériques, la bibliothèque tierce numpy est également une option :
>>> import numpy as np >>> initial = np.array([1, 1, 9, 1, 9, 6, 9, 7]) >>> _, idx = np.unique(initial, return_index=True) >>> result = initial[np.sort(idx)] >>> result [1 9 6 7]
Les valeurs d'index des éléments uniques peuvent être stockées en utilisant le np.unique() fonction avec le return_index paramètre défini sur True .
Ceux-ci peuvent ensuite être transmis à np.sort() pour produire une tranche correctement ordonnée avec les doublons supprimés.
Techniquement, cette méthode pourrait être appliquée à une liste standard en la convertissant d'abord en un tableau numpy, puis en la reconvertissant au format de liste à la fin. Cependant, ce serait un moyen trop compliqué et inefficace d'obtenir le résultat.
L'utilisation de ces types de techniques n'a vraiment de sens que si vous utilisez également certaines des fonctionnalités puissantes de numpy pour d'autres raisons.
Méthode 7 – pandas uniques()
Pandas est une autre bibliothèque tierce que nous pourrions utiliser :
>>> import pandas as pd >>> initial = pd.Series([1, 1, 9, 1, 9, 6, 9, 7]) >>> result = pd.unique(initial) >>> result [1 9 6 7]
pandas est mieux adapté à la tâche car il conserve l'ordre par défaut et pd.unique() est nettement plus rapide que np.unique() .
Comme avec la méthode numpy, il serait parfaitement possible de convertir le résultat en une liste standard à la fin.
Encore une fois cependant, à moins que vous n'utilisiez les incroyables outils d'analyse de données fournis par les pandas à d'autres fins, il n'y a aucune raison évidente de choisir cette approche plutôt que l'option encore plus rapide utilisant le type de données de dictionnaire intégré de Python (Méthode 4 ).
Résumé
Comme nous l'avons vu, il existe un large éventail de façons de résoudre ce problème et la décision de choisir celle à choisir doit être motivée par votre situation particulière.
Si vous écrivez un script rapide et que votre liste n'est pas énorme, vous pouvez choisir d'utiliser une simple boucle for par souci de clarté.
Cependant, si l'efficacité est un facteur et que vos listes ne contiennent pas d'éléments modifiables, optez pour dict.fromkeys() est une excellente option. C'est formidable que cette méthode utilise l'un des types de données intégrés de Python et conserve un bon niveau de lisibilité tout en améliorant considérablement la vitesse de la boucle for.
Alternativement, si vous utilisez une ancienne version de Python, OrderedDict.fromkeys() est un très bon choix car il est toujours très rapide.
Si vous avez besoin de travailler avec des listes contenant des éléments modifiables, importez more-itertools afin de pouvoir tirer parti de l'excellent unique_everseen() fonction a beaucoup de sens.
Enfin, si vous faites des calculs sérieux avec numpy ou manipulez des données avec des pandas, il serait probablement sage d'utiliser les méthodes intégrées à ces outils à cette fin.
Le choix vous appartient bien sûr, et j'espère que cet article vous a fourni des informations utiles qui vous aideront à choisir la bonne approche pour le travail à accomplir.

