Les probabilités et les statistiques jouent un rôle très important dans le domaine de la science des données et de l'apprentissage automatique. Dans cet article de blog, vous apprendrez le concept d'échantillonnage proportionnel et comment pouvons-nous l'implémenter à partir de zéro sans utiliser de bibliothèque
Échantillonnage proportionnel
Prenons un exemple de lancer de dé pour mieux comprendre le concept d'échantillonnage proportionnel. Un dé sans biais est un dé dans lequel la probabilité d'obtenir un nombre compris entre 1 et 6 est égale. Imaginons maintenant que le dé soit biaisé, c'est-à-dire qu'une valeur de poids est donnée à chaque côté du dé.
| 1 | 2 | 3 | 4 | 5 | 6 |
| 20 | 12 | 60 | 58 | 33 | 10 |
L'échantillonnage proportionnel est une technique dans laquelle la probabilité de sélectionner un nombre est proportionnelle au poids de ce nombre. Ainsi, par exemple, si nous exécutons une expérience consistant à lancer un dé 100 fois, la probabilité d'obtenir un 6 serait la plus faible puisque la valeur de poids du côté 6 est de 10, ce qui est la plus faible parmi toutes les autres valeurs de poids. D'autre part, la probabilité d'obtenir un 4 serait la plus élevée puisque la valeur de poids pour 3 est de 60, ce qui est la plus élevée parmi toutes les autres valeurs.
Il y a 3 étapes essentielles pour échantillonner proportionnellement un nombre dans une liste.
- Calcul des valeurs de la somme normalisée cumulée
- Choisir une valeur aléatoire à partir d'une distribution uniforme
- Échantillonner une valeur
Somme normalisée cumulée
Afin de calculer la valeur de somme normalisée cumulative, nous devons d'abord calculer la somme totale des valeurs de poids, puis normaliser les valeurs de poids en divisant chaque valeur de poids par la somme totale. Après normalisation des valeurs de poids, nous aurons toutes les valeurs entre 0 et 1 et la somme de toutes les valeurs sera toujours égale à 1.
Déclarons une variable appelée dés et poids qui représente les 6 faces du dé et les valeurs de poids correspondantes
dice = [1, 2, 3, 4, 5, 6] weights = [20, 12, 60, 58, 33, 10]
Nous allons maintenant calculer la somme de tous les poids et la stocker dans une variable appelée total_sum . Nous pouvons utiliser la fonction de somme intégrée pour ce faire.
total_sum = sum(weights) normalized_weights = [weight/total_sum for weight in weights] print(normalized_weights)
Les poids normalisés ont des valeurs comprises entre 0 et 1 et la somme de toutes les valeurs est égale à 1
[0.10362694300518134, 0.06217616580310881, 0.31088082901554404, 0.3005181347150259, 0.17098445595854922, 0.05181347150259067]
La somme cumulée est utilisée pour surveiller la détection des changements dans un ensemble de données séquentiel. Notons la somme cumulée par une variable appelée weight_cum_sum et le calculer comme suit
weight_cum_sum[0] = normalized_weights[0] weight_cum_sum[1] = weight_cum_sum[0] + normalized_weights[1] weight_cum_sum[2] = weight_cum_sum[1] + normalized_weights[2] weight_cum_sum[3] = weight_cum_sum[2] + normalized_weights[3] weight_cum_sum[4] = weight_cum_sum[3] + normalized_weights[4] weight_cum_sum[5] = weight_cum_sum[4] + normalized_weights[5]
Nous pouvons le faire efficacement en python en exécutant un for boucle et en ajoutant les valeurs de somme cumulées dans une liste
cum_sum = [normalized_weights[0]]
for i in range(1, len(normalized_weights)):
cum_sum.append(cum_sum[i-1] + normalized_weights[i])
Si nous imprimons cum_sum , nous obtiendrons les valeurs suivantes
[0.10362694300518134, 0.16580310880829013, 0.47668393782383417, 0.7772020725388601, 0.9481865284974094, 1.0]
Choisir une valeur aléatoire
Maintenant que nous avons calculé la somme cumulée des valeurs de poids, nous allons maintenant choisir au hasard un nombre entre 0 et 1 à partir d'une distribution uniforme. Nous pouvons le faire en utilisant la fonction uniforme du module random en python. Nous noterons ce nombre par r.
from random import uniform r = uniform(0,1)
Échantillonnage
Nous allons maintenant parcourir le cum_sum tableau et si la valeur de r est inférieure ou égale au cum_sum valeur à un index particulier, alors nous renverrons la valeur du dé à cet index
for index, value in enumerate(cum_sum):
if r <= value:
return dice[index] Vous pouvez voir le code entier ci-dessous
from random import uniform
def proportional_sampling(dice, weights):
total_sum = sum(weights)
normalized_weights = [weight/total_sum for weight in weights]
cum_sum = [normalized_weights[0]]
r = uniform(0,1)
for i in range(1, len(normalized_weights)):
cum_sum.append(cum_sum[i-1] + normalized_weights[i])
for index, value in enumerate(cum_sum):
if r <= value:
return dice[index]
dice = [1,2,3,4,5,6]
weights = [20, 12, 60, 58, 33, 10]
sampled_value = proportional_sampling(dice, weights) Expérimentation
Nous allons maintenant lancer une expérience où appellera le proportional_sampling 100 fois et analysez le résultat de l'échantillonnage d'un nombre
dice_result = {}
for i in range(0, 100):
sampled_value = proportional_sampling(dice, weights)
if sampled_value not in dice_result:
dice_result[sampled_value] = 1
else:
dice_result[sampled_value] += 1 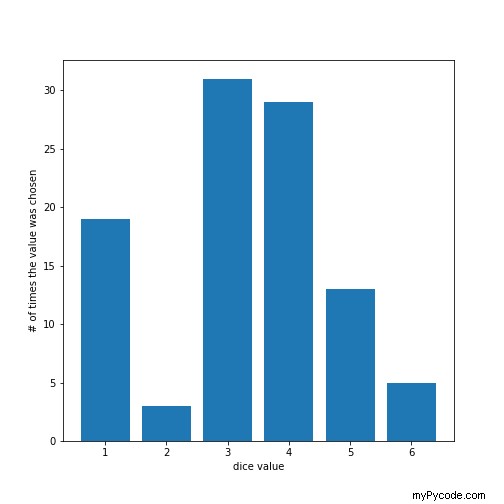
Comme vous pouvez le voir sur la figure ci-dessus, la probabilité d'obtenir un 3 est la plus élevée puisque 3 a reçu un poids de 60, qui était le plus grand nombre dans le tableau des poids. Si nous exécutons ce test sur 1 000 itérations au lieu de 100, vous pouvez vous attendre à obtenir des résultats encore plus précis.