Résumé : Utilisez urllib.parse.urljoin() pour gratter l'URL de base et le chemin relatif et les joindre pour extraire le complet/absolu URL. Vous pouvez également concaténer l'URL de base et le chemin absolu pour dériver le chemin absolu; mais assurez-vous de prendre soin des situations erronées comme une barre oblique supplémentaire dans ce cas.
Formulation du problème
Problème : Comment extraire toutes les URL absolues d'une page HTML ?
Exemple : Considérez la page Web suivante qui contient de nombreux liens :
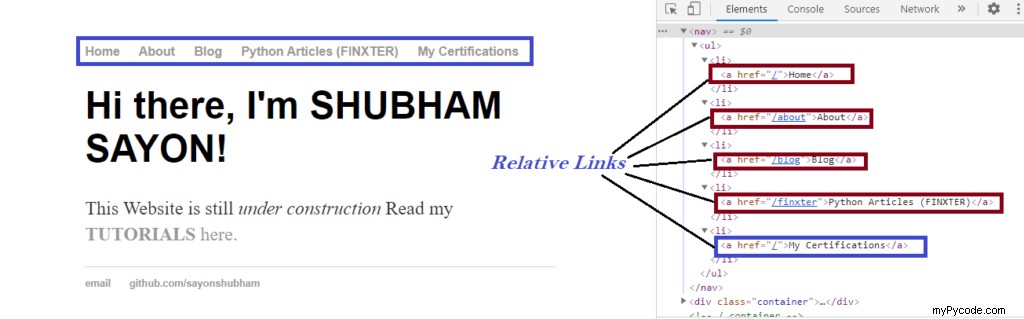
Maintenant, lorsque vous essayez de gratter les liens comme indiqué ci-dessus, vous constatez que seuls les liens/chemins relatifs sont extraits au lieu du chemin absolu complet. Jetons un coup d'œil au code ci-dessous qui montre ce qui se passe lorsque vous essayez d'extraire les éléments "href" normalement.
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
print(url['href']) Sortie :
/ /about /blog /finxter /
La sortie ci-dessus n'est pas ce que vous souhaitiez. Vous vouliez extraire les chemins absolus comme indiqué ci-dessous :
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
Par conséquent, sans plus tarder, essayons d'extraire les chemins absolus au lieu des chemins relatifs.
Méthode 1 :Utilisation de urllib.parse.urljoin()
La solution la plus simple à notre problème est d'utiliser la méthode urllib.parse.urljoin().
D'après la documentation Python :urllib.parse.urljoin() est utilisé pour construire une URL complète/absolue en combinant « l'URL de base » avec une autre URL. L'avantage d'utiliser le urljoin() est qu'il résout correctement le chemin relatif, que ce soit BASE_URL est le domaine de l'URL, ou l'URL absolue de la page Web.
from urllib.parse import urljoin URL_1 = 'http://www.example.com' URL_2 = 'http://www.example.com/something/index.html' print(urljoin(URL_1, '/demo')) print(urljoin(URL_2, '/demo'))
Sortie :
http://www.example.com/demo http://www.example.com/demo
Maintenant que nous avons une idée sur urljoin , examinons le code suivant qui résout avec succès notre problème et nous aide à extraire les chemins complets/absolus de la page HTML.
Solution :
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
print(urljoin(web_url, url.get('href'))) Sortie :
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
Méthode 2 :concaténer manuellement l'URL de base et l'URL relative
Une autre solution à notre problème consiste à concaténer manuellement la partie de base de l'URL et les URL relatives, tout comme deux chaînes ordinaires. Le problème, dans ce cas, est que l'ajout manuel des chaînes peut entraîner des erreurs "ponctuelles" (repérez le supplément / ci-dessous) :
URL_1 = 'http://www.example.com/' print(URL_1+'/demo') # Output – > http://www.example.com//demo
Par conséquent, afin d'assurer une concaténation correcte, vous devez modifier votre code en conséquence afin que tout caractère supplémentaire pouvant entraîner des erreurs soit supprimé. Jetons un coup d'œil au code suivant qui nous aide à concaténer la base et les chemins relatifs sans la présence d'une barre oblique supplémentaire.
Solution :
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
# extract the href string
x = url['href']
# remove the extra forward-slash if present
if x[0] == '/':
print(web_url + x[1:])
else:
print(web_url+x) Sortie :
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
⚠️ Attention : Ce n'est pas la méthode recommandée pour extraire le chemin absolu d'une page HTML donnée. Dans des situations, lorsque vous avez un script automatisé qui doit résoudre une URL mais qu'au moment de l'écriture du script, vous ne savez pas quel site Web votre script visite, dans ce cas, cette méthode ne servira pas votre objectif et votre départ -to méthode serait d'utiliser urlljoin . Néanmoins, cette méthode mérite d'être mentionnée car dans notre cas, elle sert avec succès l'objectif et nous aide à extraire les URL absolues.
Conclusion
Dans cet article, nous avons appris à extraire les liens absolus d'une page HTML donnée à l'aide de BeautifulSoup. Si vous souhaitez maîtriser les concepts de la bibliothèque Pythons BeautifulSoup et plonger dans les concepts avec des exemples et des leçons vidéo, veuillez consulter le lien suivant et suivez les articles un par un dans lequel vous trouverez chaque aspect de BeautifulSoup expliqué en grande détails.
LIEN DE L'ARTICLE :Web Scraping avec BeautifulSoup en Python
TUTORIEL VIDÉO :Web Scraping avec BeautifulSoup en Python
Sur ce, nous arrivons à la fin de ce tutoriel ! Veuillez rester à l'écoute et abonnez-vous pour des contenus plus intéressants à l'avenir.