Vous pouvez extraire du texte à partir d'images avec EasyOCR, un outil OCR basé sur l'apprentissage en profondeur en Python. EasyOCR fonctionne très bien sur les factures, l'écriture manuscrite, les plaques d'immatriculation et les panneaux publics.
Publié pour la première fois en 2007, PyTesseract [1] est la bibliothèque incontournable pour extraire du texte à partir d'images . Il utilise des méthodes classiques de vision par ordinateur pour effectuer la reconnaissance optique de caractères (OCR), puis intègre des composants de réseau de neurones tels que LSTM à partir de sa quatrième version.
Vous pouvez vous demander :Existe-t-il une alternative aussi efficace que PyTesseract pour l'OCR ? Oui, c'est EasyOCR [2]. Il s'agit d'un nouveau module basé sur l'apprentissage en profondeur pour lire du texte à partir de toutes sortes d'images dans plus de 80 langues.
Dans cet article, nous allons suivre un tutoriel en trois étapes.
- Tout d'abord, nous allons installer les bibliothèques requises.
- Deuxièmement, nous effectuerons un traitement image-texte à l'aide d'EasyOCR sur diverses images.
- Troisièmement, nous utiliserons OpenCV pour superposer les textes détectés sur les images d'origine. Commençons.
Étape 1 :Installer et importer les modules requis
La reconnaissance optique de caractères est un processus de lecture de texte à partir d'images. Une tâche facile pour les humains, mais plus de travail pour les ordinateurs pour identifier le texte à partir des pixels de l'image. Pour ce tutoriel, nous aurons besoin des modules OpenCV, Matplotlib, Numpy, PyTorch et EasyOCR. Voici le référentiel GitHub de ce tutoriel.
Vous pouvez suivre le tutoriel dans notre notebook Jupyter interactif en ligne :
Tout d'abord, créez un environnement virtuel pour ce projet. Ensuite, installez les modules mentionnés dans un notebook Jupyter :
!pip install opencv-python !pip install matplotlib !pip install numpy !pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html !pip install easyocr
Le module OpenCV est destiné aux opérations liées à la vision par ordinateur en Python. Plus précisément, nous l'utiliserons pour superposer des images avec des textes reconnus respectifs plus tard. Nous avons besoin du module Matplotlib pour afficher les images. Et nous utiliserons le module Numpy pour convertir les images en tableaux.
PyTorch est un prérequis pour le module EasyOCR. Son installation varie en fonction des exigences du système d'exploitation et du pilote GPU. Vous pouvez obtenir les commandes d'installation sur la page d'accueil de PyTorch [3]. Copiez et exécutez la commande respective comme illustré à la figure 1 si vous travaillez sous Windows.

Maintenant, allez-y et installez le module EasyOCR - l'outil dont nous avons besoin pour extraire le texte des images. À ce stade, vous devriez être en mesure d'exécuter les lignes de code suivantes dans votre bloc-notes :
import cv2 import numpy as np import easyocr import matplotlib.pyplot as plt %matplotlib inline
Notez que le %matplotlib inline La commande magique est exclusive aux notebooks Jupyter. Ce n'est pas obligatoire dans un script Python. Il définit le backend du module Matplotlib pour afficher les chiffres en ligne et non sur une fenêtre séparée.
Vous partez du bon pied ! Maintenant, passons à l'étape suivante.
Étape 2 :Charger les images et extraire le texte à l'aide d'EasyOCR
Pour des raisons de droits d'auteur, toutes les images utilisées dans l'exemple de bloc-notes ne sont pas fournies dans le référentiel GitHub. N'hésitez pas à les télécharger depuis Unsplash.com ou à utiliser vos images. Définissez le chemin d'une image à l'aide du code suivant :
im_1_path = './folder/image_name.jpg'
Ensuite, initialisez un lecteur EasyOCR avec une liste de langues que vous souhaitez utiliser. Utilisez le lecteur pour lire une image avec la fonction suivante :
def recognize_text(img_path):
'''loads an image and recognizes text.'''
reader = easyocr.Reader(['en'])
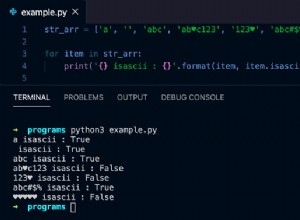
return reader.readtext(img_path) Cela vous a-t-il surpris que deux lignes de code suffisent pour effectuer l'OCR ? « Facile » pour EasyOCR ! Le recognize_text() La fonction initialise un lecteur OCR à une variable nommée reader. Il prend une liste de langues comme paramètre. Pour ce tutoriel, nous voulons uniquement reconnaître le texte anglais, donc le ‘en’ dans la liste. Le texte lu La méthode lit une image en fonction de son répertoire stocké. Le résultat OCR renvoyé est transmis comme sortie de recognize_text() fonction.
result = recognize_text(im_1_path) result
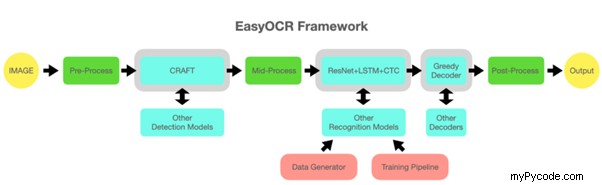
Notez qu'il faudra plus de temps pour exécuter EasyOCR sur un CPU au lieu d'un GPU. Le im_1_path l'image a pris environ dix secondes pour être exécutée par recognize_text() . La figure 2 montre les opérations dans le cadre EasyOCR. Le cadre comprend le prétraitement d'images, la reconnaissance de modèles d'apprentissage en profondeur et le post-traitement d'images.
Voici la sortie du module EasyOCR :
[([[1421, 1139], [1453, 1139], [1453, 1177], [1421, 1177]], 'S', 0.8625819477165351), ([[1524, 1038], [2201, 1038], [2201, 1211], [1524, 1211]], 'CCC444', 0.9068348515895301), ([[1641, 1201], [2012, 1201], [2012, 1245], [1641, 1245]], 'T E S L A.C O M', 0.33458756243407134), ([[2519, 1254], [2790, 1254], [2790, 1284], [2519, 1284]], 'DUAL MSTOF', 0.24584700695087508)]
Il renvoie une liste de texte détecté, chaque élément de texte contenant trois types d'informations. Lesquels sont :le texte, ses sommets de boîte englobante et le niveau de confiance de la détection de texte. À partir de la sortie, EasyOCR a détecté quatre éléments de texte :"S", "CCC444", "T E S L A.C O M" et "DUAL MSTOF".
Pour vérifier l'exactitude de l'OCR, nous devons afficher l'image originale sur notre ordinateur portable :
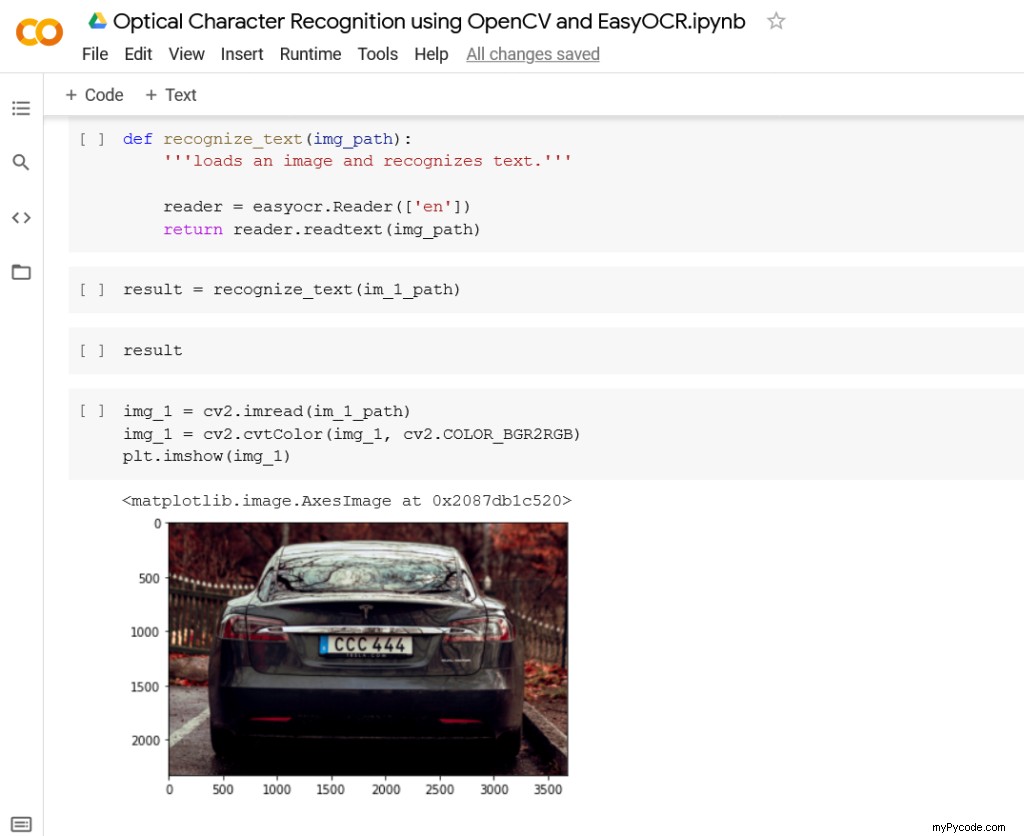
img_1 = cv2.imread(im_1_path) img_1 = cv2.cvtColor(img_1, cv2.COLOR_BGR2RGB) plt.imshow(img_1)
Le imread La méthode du module OpenCV charge une image sous forme de tableau Numpy, qui est affecté à img_1 variable. Les canaux de couleur par défaut d'OpenCV sont (Bleu, Vert, Rouge) au lieu de (Rouge, Vert, Bleu). C'est pourquoi nous utilisons le cvtColor méthode de conversion des canaux. Sinon, nous verrons l'image avec sa couleur bleue supposée rouge et vice versa. L'image est montrée sur la figure 3, qui est une voiture avec une vue arrière de sa plaque d'immatriculation.

En comparant l'image avec sa sortie OCR, la plaque de la voiture est capturée avec précision. EasyOCR détecte le code du pays et le nom du fournisseur de voiture. Pourtant, le texte "DUAL MOTOR" sur le côté droit de la voiture est détecté comme "DUAL MSTOF". Pour cela, des techniques de prétraitement d'image peuvent être utilisées pour augmenter la précision de l'OCR. Mais pour l'instant, nous ne testerons que les performances d'EasyOCR prêtes à l'emploi.
Étape 3 :superposer le texte reconnu sur les images à l'aide d'OpenCV
Maintenant, nous voulons dessiner un rectangle autour de chaque élément de texte reconnu sur son image d'origine. Le overlay_ocr_text() fonction sera expliquée tâche par tâche.
def overlay_ocr_text(img_path, save_name):
'''loads an image, recognizes text, and overlays the text on the image.'''
# loads image
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dpi = 80
fig_width, fig_height = int(img.shape[0]/dpi), int(img.shape[1]/dpi)
plt.figure()
f, axarr = plt.subplots(1,2, figsize=(fig_width, fig_height))
axarr[0].imshow(img)
Tout d'abord, nous utilisons le module OpenCV pour charger une image en tant que tableau Numpy et corriger ses canaux de couleur. Le tableau est affecté à la variable img . Nous souhaitons afficher deux images - l'image d'origine et l'image d'origine avec les textes reconnus. Les sous-parcelles La méthode de Matplotlib est utilisée pour afficher plusieurs chiffres à la fois. Le imshow méthode du axarr[0] variable affiche l'image d'origine.
# recognize text
result = recognize_text(img_path)
# if OCR prob is over 0.5, overlay bounding box and text
for (bbox, text, prob) in result:
if prob >= 0.5:
# display
print(f'Detected text: {text} (Probability: {prob:.2f})')
# get top-left and bottom-right bbox vertices
(top_left, top_right, bottom_right, bottom_left) = bbox
top_left = (int(top_left[0]), int(top_left[1]))
bottom_right = (int(bottom_right[0]), int(bottom_right[1]))
# create a rectangle for bbox display
cv2.rectangle(img=img, pt1=top_left, pt2=bottom_right, color=(255, 0, 0), thickness=10)
# put recognized text
cv2.putText(img=img, text=text, org=(top_left[0], top_left[1] - 10), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 0, 0), thickness=8)
Le recognize_text() la fonction renvoie la sortie OCR et l'affecte au résultat variable. Un pour boucle est créée pour parcourir chaque élément de texte contenu dans la variable. Les éléments de texte reconnus ne sont affichés que si leurs niveaux de confiance OCR sont supérieurs à 0,5 (prob>=0,5 ). Ensuite, les sommets supérieur gauche et inférieur droit de chaque boîte englobante sont obtenus. Ils sont convertis en tuples de valeurs entières (comme requis par OpenCV).
Le rectangle La méthode crée une boîte englobante verte pour chaque élément de texte détecté. Le putText La méthode affiche le texte reconnu au-dessus de sa zone de délimitation respective. Comme tout cela est fait dans un for boucle, l'opération se répète pour chaque texte reconnu dans le résultat variables.
# show and save image
axarr[1].imshow(img)
plt.savefig(f'./output/{save_name}_overlay.jpg', bbox_inches='tight') Enfin, le overlay_ocr_text() La fonction affiche chaque texte créé et chaque boîte englobante. Le imshow méthode du axarr[1] variable affiche l'image finale. Comme les images de gauche et de droite se trouvent dans la même sous-parcelle, elles sont affichées comme une seule image finale. La savefig La méthode stocke l'image finale dans un répertoire local défini.
Quelle est la performance d'EasyOCR ?
Les figures ci-dessous montrent les performances d'EasyOCR pour différents types d'images. Nous testerons la bibliothèque sur l'écriture manuscrite, les chiffres, une facture électronique et un panneau public. Pour un aperçu complet, veuillez vous référer au bloc-notes de démonstration dans le dépôt GitHub donné.

EasyOCR détecte correctement la majeure partie du texte de la figure 7, à l'exception du texte sur le côté droit.

EasyOCR parvient à détecter chaque texte de la figure 5. Mais la séquence de texte n'est pas entièrement correcte.
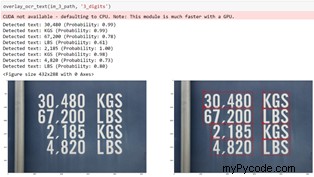
EasyOCR détecte correctement tout dans la Figure 6. Il s'agit d'une image relativement grande avec des chiffres et des textes imprimés clairs, ce qui améliore les performances de l'OCR.

EasyOCR parvient à détecter avec précision chaque texte de la facture sans prétraitement d'image.

Encore une fois, EasyOCR le cloue pour la figure 8. Chaque texte sur la figure est correctement détecté.
Nous avons eu l'impression qu'EasyOCR était très performant sur les images avec du texte clair. Cela fonctionne bien sans avoir à prétraiter les images, ce qui permet d'économiser du temps et de l'argent.
Bonus :reconnaissance de la synthèse vocale
Les sorties de l'OCR peuvent être davantage utilisées avec une simple application de reconnaissance de la synthèse vocale. Il convertit le texte en un énoncé vocal. Tout d'abord, nous devons installer le module PyTTSX3 [4] comme suit :
!pip install pyttsx3
L'implémentation peut se faire en cinq lignes de code :
import pyttsx3
engine = pyttsx3.init()
engine.setProperty('rate', 100)
engine.say(sentence)
engine.runAndWait()
Le code initialise un moteur TTS et l'affecte au moteur variable. Le setProperty La méthode définit la vitesse de l'énoncé. Le dire La méthode enregistre la phrase de texte à prononcer. Enfin, le runAndWait La méthode exécute l'opération de synthèse vocale.
Conclusion
Cet article explique comment extraire des éléments de texte à partir d'images à l'aide d'EasyOCR. Il montre également comment superposer du texte reconnu sur des images à l'aide d'OpenCV. Une simple synthèse vocale est également introduite en tant qu'application étendue pour la sortie OCR.
Références
[1] https://github.com/madmaze/pytesseract
[2] https://github.com/JaidedAI/EasyOCR
[3] https://pytorch.org/get-started/locally/
[4] https://pypi.org/project/pyttsx3/
Humour de programmation