Bienvenue dans cet article sur la régression polynomiale dans Machine Learning. Vous pouvez parcourir les articles sur la régression linéaire simple et la régression linéaire multiple pour mieux comprendre cet article.
Cependant, revenons rapidement sur ces concepts.
Révision rapide de la régression linéaire simple et de la régression linéaire multiple
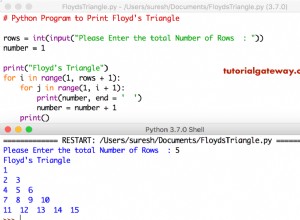
La régression linéaire simple est utilisée pour prédire les valeurs finies d'une série de données numériques. Il y a une variable indépendante x qui est utilisée pour prédire la variable y. Il y a des constantes comme b0 et b1 qui s'ajoutent comme paramètres à notre équation.
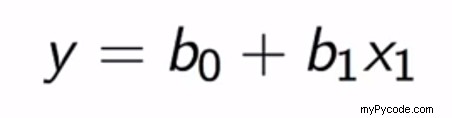
En ce qui concerne la régression linéaire multiple, nous prédisons des valeurs en utilisant plus d'une variable indépendante. Ces variables indépendantes sont transformées en une matrice de caractéristiques, puis utilisées pour la prédiction de la variable dépendante. L'équation peut être représentée comme suit :
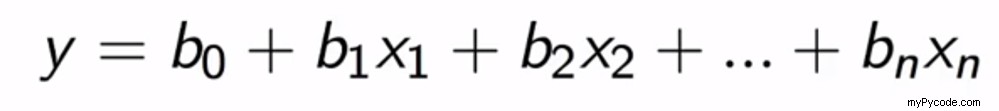
Qu'est-ce que la régression polynomiale ?
La régression polynomiale, également un type de régression linéaire, est souvent utilisée pour faire des prédictions à l'aide des puissances polynomiales des variables indépendantes. Vous pouvez mieux comprendre ce concept en utilisant l'équation ci-dessous :
Quand la régression polynomiale est-elle utilisée ?
Dans le cas d'une régression linéaire simple, certaines données sont au-dessus ou en dessous de la ligne et ne sont donc pas exactes. C'est là que la régression polynomiale peut être utilisée.
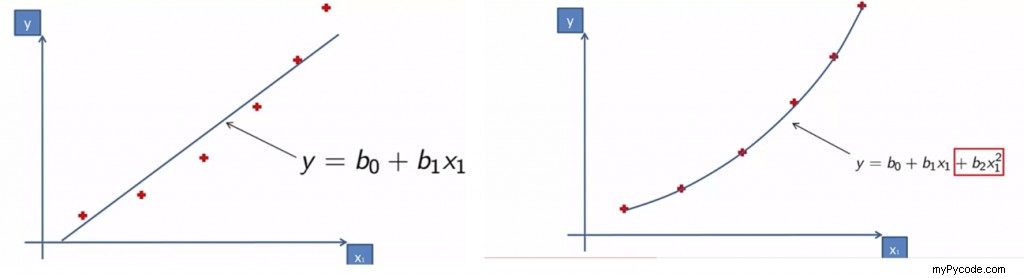
Dans l'image affichée sur le côté gauche, vous pouvez remarquer qu'il y a des points au-dessus de la ligne de régression et des points en dessous de la ligne de régression. Cela rend le modèle moins précis. C'est le cas de la régression linéaire.
Maintenant, regardez l'image sur le côté droit, il s'agit de la régression polynomiale. Ici, notre droite ou courbe de régression s'ajuste et passe par tous les points de données. Ainsi, rendant cette régression plus précise pour notre modèle.
Pourquoi la régression polynomiale est-elle appelée linéaire ?
La régression polynomiale est parfois appelée régression linéaire polynomiale. Pourquoi donc ?
Même s'il a d'énormes pouvoirs, il est toujours appelé linéaire. En effet, lorsque nous parlons de linéaire, nous ne le considérons pas du point de vue de la variable x. On parle de coefficients.
Y est une fonction de X. Cette fonction peut-elle être exprimée comme une combinaison linéaire de coefficients, car elle est finalement utilisée pour brancher X et prédire Y.
Par conséquent, en regardant simplement l'équation du point de vue des coefficients, la rend linéaire. Intéressant non ?
Nous allons maintenant examiner un exemple pour comprendre comment effectuer cette régression.
Un exemple simple de régression polynomiale en Python
Voyons rapidement comment effectuer une régression polynomiale. Pour cet exemple, j'ai utilisé un ensemble de données de prédiction de salaire.
Supposons que vous, l'équipe RH d'une entreprise, vouliez vérifier les détails de travail passés d'un nouvel employé potentiel qu'ils vont embaucher. Cependant, ils obtiennent des informations sur seulement 10 salaires dans leurs postes.
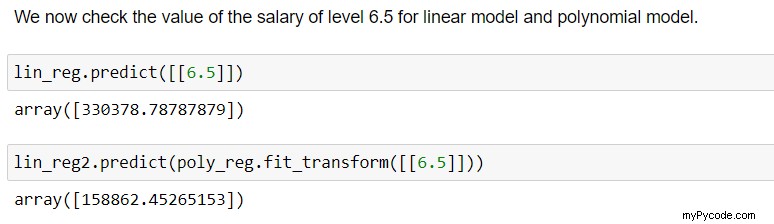
Avec cela, l'équipe RH peut se rapporter au poste de la personne, disons au niveau 6.5, et peut vérifier si l'employé a bluffé à propos de son ancien salaire.
Par conséquent, nous allons construire un détecteur de bluff.
L'ensemble de données peut être trouvé ici - https://github.com/content-anu/dataset-polynomial-regression
1. Importation du jeu de données
Pour importer et lire l'ensemble de données, nous utiliserons la bibliothèque Pandas et utiliserons la méthode read_csv pour lire les colonnes dans des cadres de données.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Position_Salaries.csv')
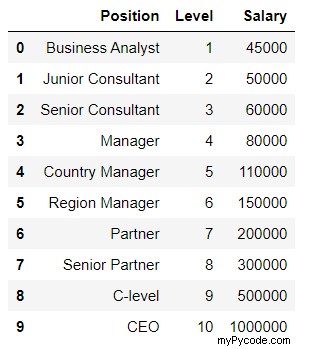
dataset
La sortie du code ci-dessus montre l'ensemble de données qui est le suivant :
2. Prétraitement des données
En observant l'ensemble de données, vous voyez que seules les colonnes "niveau" et "salaire" sont nécessaires et que la position a été encodée dans le niveau. Elle peut donc être ignorée. Alors sautez "Position" de la matrice des fonctionnalités.
X = dataset.iloc[:,1:2].values y = dataset.iloc[:,2].values
Comme nous n'avons que 10 observations, nous ne séparerons pas l'ensemble de test et d'entraînement. Ceci pour 2 raisons :
- De petites observations n'ont pas de sens, car nous ne disposons pas de suffisamment d'informations pour nous entraîner sur un ensemble et tester le modèle sur l'autre.
- Nous voulons faire une prédiction très précise. Nous avons besoin de plus d'informations sur le train. Par conséquent, l'ensemble de données est utilisé uniquement pour la formation.
3. Ajustement d'un modèle de régression linéaire
Nous l'utilisons pour comparer les résultats avec la régression polynomiale.
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X,y)
La sortie du code ci-dessus est une seule ligne qui déclare que le modèle a été ajusté.
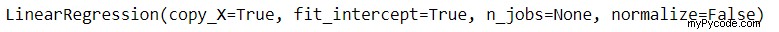
4. Visualisation des résultats du modèle de régression linéaire
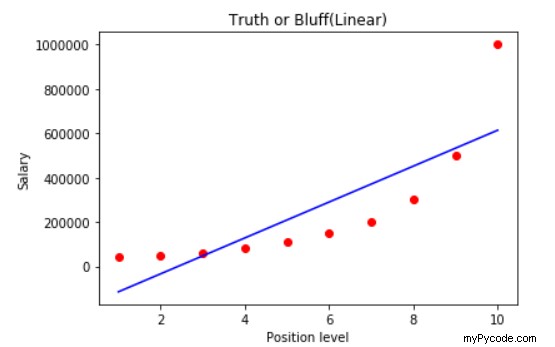
plt.scatter(X,y, color='red')
plt.plot(X, lin_reg.predict(X),color='blue')
plt.title("Truth or Bluff(Linear)")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
Le code ci-dessus produit un graphique contenant une droite de régression et se présente comme indiqué ci-dessous :
5. Ajustement d'un modèle de régression polynomiale
Nous allons importer PolynomialFeatures classer. poly_reg est un outil de transformation qui transforme la matrice de caractéristiques X en une nouvelle matrice de caractéristiques X_poly. Il contient x1, x1^2,……, x1^n.
degree Le paramètre spécifie le degré des caractéristiques polynomiales dans X_poly. Nous considérons la valeur par défaut soit 2.
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree=2) X_poly = poly_reg.fit_transform(X) X # prints X
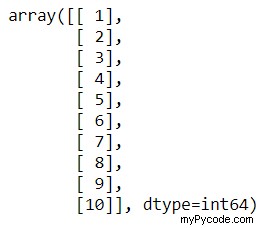
X_poly # prints the X_poly

X est les valeurs d'origine. X_poly a trois colonnes. La première colonne est la colonne de 1 pour la constante. X contenant des valeurs réelles est la colonne du milieu, c'est-à-dire x1. La deuxième colonne est un carré de x1.
L'ajustement doit être inclus dans un modèle de régression linéaire multiple. Pour ce faire, nous devons créer un nouvel objet de régression linéaire lin_reg2 et cela sera utilisé pour inclure l'ajustement que nous avons fait avec l'objet poly_reg et notre X_poly.
lin_reg2 = LinearRegression() lin_reg2.fit(X_poly,y)
Le code ci-dessus produit la sortie suivante :
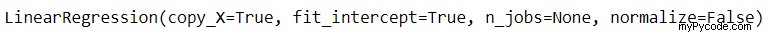
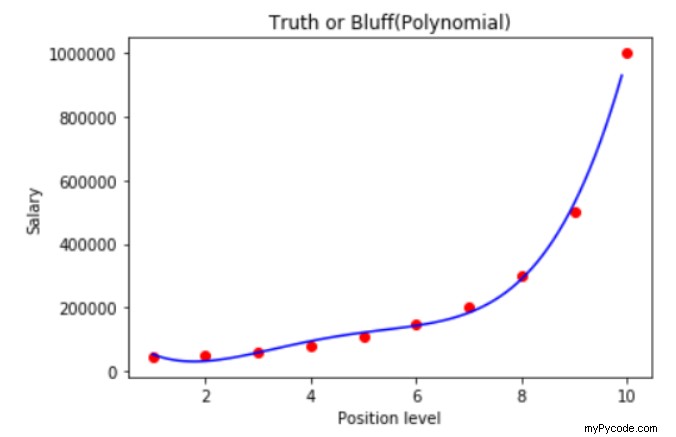
6. Visualisation du modèle de régression polynomiale
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=4)
X_poly = poly_reg.fit_transform(X)
lin_reg2 = LinearRegression()
lin_reg2.fit(X_poly,y)
X_grid = np.arange(min(X),max(X),0.1)
X_grid = X_grid.reshape(len(X_grid),1)
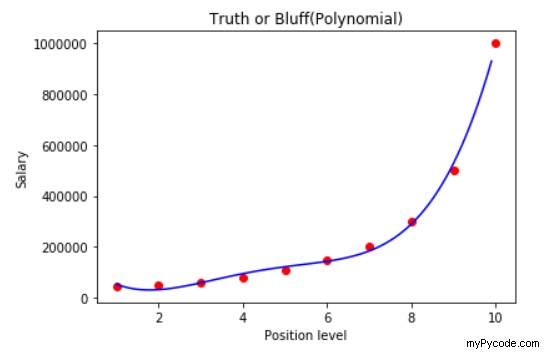
plt.scatter(X,y, color='red')
plt.plot(X_grid, lin_reg2.predict(poly_reg.fit_transform(X_grid)),color='blue')
plt.title("Truth or Bluff(Polynomial)")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
7. Prédire le résultat
Code complet pour la régression polynomiale en Python
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Position_Salaries.csv')
dataset
X = dataset.iloc[:,1:2].values
y = dataset.iloc[:,2].values
# fitting the linear regression model
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
# visualising the linear regression model
plt.scatter(X,y, color='red')
plt.plot(X, lin_reg.predict(X),color='blue')
plt.title("Truth or Bluff(Linear)")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
# polynomial regression model
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=2)
X_poly = poly_reg.fit_transform(X)
X_poly # prints X_poly
lin_reg2 = LinearRegression()
lin_reg2.fit(X_poly,y)
# visualising polynomial regression
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=4)
X_poly = poly_reg.fit_transform(X)
lin_reg2 = LinearRegression()
lin_reg2.fit(X_poly,y)
X_grid = np.arange(min(X),max(X),0.1)
X_grid = X_grid.reshape(len(X_grid),1)
plt.scatter(X,y, color='red')
plt.plot(X_grid, lin_reg2.predict(poly_reg.fit_transform(X_grid)),color='blue')
plt.title("Truth or Bluff(Polynomial)")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
Le code ci-dessus génère le graphique ci-dessous :
Conclusion
Ceci vient à la fin de cet article sur la régression polynomiale. J'espère que vous avez compris le concept de régression polynomiale et que vous avez essayé le code que nous avons illustré. Faites-nous part de vos commentaires dans la section des commentaires ci-dessous.