Deux choses m'ont poussé à écrire ce code :-
1. Les couches sont chères et économiser un dollar ou deux dessus chaque mois, c'est cool.
2. Si vous n'utilisez pas Python pour automatiser certaines choses, vous ne le faites pas correctement.
Alors, voici comment j'ai utilisé la mise au rebut Web pour trouver des offres bon marché sur les couches :-
Amazon propose certaines offres d'entrepôt, qui, au moins dans le cas des couches, consistent en des produits qui sont retournés par les acheteurs et dont l'original est défectueux emballage. Mais, le produit à l'intérieur est pour la plupart neuf et inutilisé. Ainsi, trouver de telles offres peut vous aider à économiser quelques dollars sur certaines choses. Passons donc à la partie codage :
Nous utiliserons les requêtes et BeautifulSoup. Alors, importons-les et puisque amazon.com n'aime pas que Python fasse défiler son site Web, ajoutons quelques en-têtes.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
}
Maintenant, nous devrons trouver l'URL cible, vous pouvez facilement la trouver en parcourant le site Web, en sélectionnant les offres d'entrepôt dans le menu déroulant, en entrant les mots-clés et en appuyant sur le bouton de recherche. Laissez-moi vous faciliter la tâche. Entrez simplement les codes suivants :-
AMAZON = 'https:/www.amazon.com'
BASE_URL = 'https://www.amazon.com/s/search-alias%3Dwarehouse-deals&field-keywords='
SEARCH_WORDS = 'huggies+little+movers+Size 4'
url = BASE_URL + SEARCH_WORDS
Si vous effectuez une recherche manuelle sur le site Web, vous obtiendrez le type d'écran suivant :-
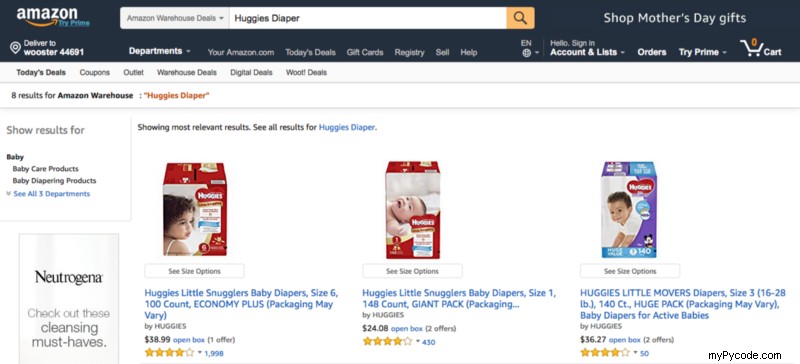
Vous devez vous concentrer sur la ligne qui indique 8 résultats pour Amazon Warehouse :« Huggies Diaper ». Désormais, nous pouvons rencontrer les quatre cas suivants lorsque nous recherchons un article dans les offres d'entrepôt :-
- Aucun accord n'est en cours.
- Il y a un nombre limité d'offres présentes et toutes sont sur une seule page. (par exemple, 8 résultats pour Amazon Warehouse :"Couche Huggies")
- Le nombre d'offres disponibles est limité, mais elles sont réparties sur plusieurs pages. (par exemple, 1–24 sur 70 résultats pour Amazon Warehouse :"câlins")
- Il y a plus de 1 000 offres présentes (par exemple, 1 à 24 sur plus de 4 000 résultats pour Amazon Warehouse :"iphone")
Je traiterai ci-dessus comme ci-dessous :-
En cas de non offres présentes, je quitterai la fonction. (Nous pouvons enregistrer de tels cas)
Dans le second cas, nous créerons un dictionnaire des données à l'aide de la fonction scrap_data(). Nous allons bientôt le vérifier en détail.
Dans les troisième et quatre cas, nous devrons parcourir plusieurs pages et pour faire simple, nous parcourrons un maximum de 96 résultats, soit 4 pages.
Créons donc une soupe à l'aide de BeautifulSoup et des requêtes, puisque nous allons créer des soupes pour plusieurs URL dans certains cas, il est préférable de créer une fonction différente pour cela :-
def create_soup(url):
req = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(req.text, 'html.parser')
return soup
Si nous inspectons l'élément, nous constaterons que ladite ligne de texte a span id ="s-result-count". Maintenant, nous allons saisir le texte en utilisant le code suivant :-
result = soup.find("span", id="s-result-count").text
Nous utiliserons regex pour faire correspondre les troisième et quatrième scénarios et rechercherons simplement les 96 premiers résultats (ou quatre pages) dans le cas du quatrième scénario. Le code pour le même serait comme ci-dessous :-
import re
def parse_result(result):
''' This will take care of 4 cases of results
Case 1 When no result is available.
Case 2 When all the results available are shown on first page only i.e. 24 results.
Case 3 When there are more than 24 results and there are more than one page but the number of result is certain.
Case 4 When there are over 500, 1000 or more results.
'''
matchRegex = re.compile(r'''(
(1-\d+)\s
(of)\s
(over\s)?
(\d,\d+|\d+)\s
)''', re.VERBOSE)
matchGroup = matchRegex.findall(result)
# Case 1 simply exits the function
# TODO Log such cases
if "Amazon Warehouse" not in result:
exit()
else:
# Case2
if not matchGroup:
resultCount = int(result.split()[0])
# Case4
elif matchGroup[0][3] == "over ":
resultCount = 96
# Case3
else:
resultCount = min([(int(matchGroup[0][4])), 96])
return resultCount
Effectuons quelques calculs et obtenons le nombre de résultats et le nombre de pages dont nous avons besoin pour naviguer :-
def crunch_numbers():
soup = create_soup(url)
result = soup.find("span", id="s-result-count").text
resultCount = parse_result(result)
navPages = min([resultCount // 24 + 1, 4])
return resultCount, navPages
Donc, enfin, nous avons un nombre cible sous la forme de resultCount et nous allons extraire les données pour ce nombre. En inspectant de près l'élément de la page Web, vous constaterez que tous les résultats se trouvent à l'intérieur de la balise li avec un id="result_0" (Oui, ils sont indexés à zéro).
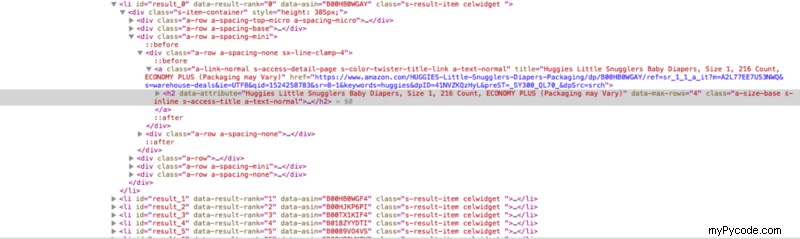
Le nom de l'article, le lien et le prix sont dans les balises h2, a et span à l'intérieur de la balise li. Cependant, même si les résultats jusqu'au numéro 96 seront avec l'identifiant "result_96", ils seront répartis sur 4 pages. Donc, nous devons également obtenir l'url des pages précédentes. Ainsi, le lien vers la deuxième page de résultats est dans un span avec une classe "pagenLink" et il a deux références au numéro de page "sr_pg_2" et "page=2". Donc, si nous allons saisir ceci, nous pouvons facilement obtenir les deux URL suivantes en remplaçant 2 par 3 et 4 pour les pages suivantes :-

En fonction du nombre de navPages, nous allons créer un dictionnaire pour remplacer le chiffre "2" par le chiffre souhaité comme ci-dessous :-
dict_list = [{
"sr_pg_2": "sr_pg_" + str(i),
"page=2": "page=" + str(i)
} for i in range(2, navPages + 1)]
Nous saisirons la deuxième URL en utilisant le code suivant :-
nextUrl = soup.find("span", class_="pagnLink").find("a")["href"]
Et, en remplaçant le chiffre à l'aide de la fonction suivante :-
def get_url(text, dict):
for key, value in dict.items():
url = AMAZON + text.replace(key, value)
return url
Enfin, nous extrairons le nom, l'url et le prix du produit souhaité. Dans le cas de plusieurs pages de résultats, nous utiliserons les instructions if elif pour créer de nouvelles soupes pour les prochaines URL saisies ci-dessus. Enfin, nous ajouterons les données à un dictionnaire pour un traitement ultérieur. Le code sera comme ci-dessous :-
def scrap_data():
resultCount, navPages = crunch_numbers()
soup = create_soup(url)
try:
nextUrl = soup.find("span", class_="pagnLink").find("a")["href"]
renameDicts = [{
"sr_pg_2": "sr_pg_" + str(i),
"page=2": "page=" + str(i)
} for i in range(2, navPages + 1)]
urlList = [get_url(nextUrl, dict) for dict in renameDicts]
except AttributeError:
pass
productName = []
productLink = []
productPrice = []
for i in range(resultCount):
if i > 23 and i <= 47:
soup = create_soup(urlList[0])
elif i > 47 and i <= 71:
soup = create_soup(urlList[1])
elif i > 71:
soup = create_soup(urlList[2])
id = "result_{}".format(i)
try:
name = soup.find("li", id=id).find("h2").text
link = soup.find("li", id="result_{}".format(i)).find("a")["href"]
price = soup.find(
"li", id="result_{}".format(i)).find("span", {
'class': 'a-size-base'
}).text
except AttributeError:
name = "Not Available"
link = "Not Available"
price = "Not Available"
productName.append(name)
productLink.append(link)
productPrice.append(price)
finalDict = {
name: [link, price]
for name, link, price in zip(productName, productLink, productPrice)
}
return finalDict
Afin d'automatiser le processus, nous voudrons que notre programme nous envoie la liste des produits disponibles à un moment donné. Pour cela, nous allons créer un fichier "email_message.txt" vide. Nous allons filtrer davantage le finalDict généré par scrap_data.py et créer un message électronique personnalisé à l'aide du code suivant :
def create_email_message():
finalDict = scrap_data()
notifyDict = {}
with open("email_message.txt", 'w') as f:
f.write("Dear User,\n\nFollowing deals are available now:\n\n")
for key, value in finalDict.items():
# Here we will search for certain keywords to refine our results
if "Size 4" in key:
notifyDict[key] = value
for key, value in notifyDict.items():
f.write("Product Name: " + key + "\n")
f.write("Link: " + value[0] + "\n")
f.write("Price: " + value[1] + "\n\n")
f.write("Yours Truly,\nPython Automation")
return notifyDict
```
So, now we will be notifying the user via email for that we will be using .env to save the user credentials and even the emails (though you can use the .txt file to save the emails also). You can read more about using dotenv from the link below:-
https://github.com/uditvashisht/til/blob/master/python/save-login-credential-in-env-files.md
Create an empty .env file and save the credentials:-
```
#You can enter as many emails as you want, separated by a whitespace
emails = '[email protected] [email protected]'
MY_EMAIL_ADDRESS = "[email protected]"
MY_PASSWORD = "yourpassword"
Ensuite, vous devrez effectuer les importations suivantes dans votre programme et charger l'environnement comme suit :
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
De plus, nous utiliserons smtplib pour envoyer des e-mails. J'ai copié la plupart du code pour cette partie de ce post par Arjun Krishna Babu :-
def notify_user():
load_dotenv(find_dotenv())
notifyDict = create_email_message()
emails = os.getenv("emails").split()
if notifyDict != {}:
s = smtplib.SMTP(host="smtp.gmail.com", port=587)
s.starttls()
s.login(os.getenv("MY_EMAIL_ADDRESS"), os.getenv("MY_PASSWORD"))
for email in emails:
msg = MIMEMultipart()
message = open("email_message.txt", "r").read()
msg['From'] = os.getenv("MY_EMAIL_ADDRESS")
msg['To'] = email
msg['Subject'] = "Hurry Up: Deals on Size-4 available."
msg.attach(MIMEText(message, 'plain'))
s.send_message(msg)
del msg
s.quit()
Et enfin :-
if __name__ == '__main__':
notify_user()
Maintenant, vous pouvez programmer ce script pour qu'il s'exécute sur votre propre ordinateur ou sur un serveur cloud pour vous avertir périodiquement.
Le code complet est disponible ici