Prenons la définition de la notation Big-O de Wikipédia :
La notation Big O est une notation mathématique qui décrit le comportement limite d'une fonction lorsque l'argument tend vers une valeur particulière ou vers l'infini.
...
En informatique, la notation Big O est utilisée pour classer les algorithmes en fonction de la croissance de leur temps d'exécution ou de leur espace requis à mesure que la taille de l'entrée augmente.
Donc Big-O est similaire à :

Ainsi, lorsque vous comparez deux algorithmes sur les petites plages/nombres, vous ne pouvez pas vous fier fortement à Big-O. Analysons l'exemple :
Nous avons deux algorithmes :le premier est O(1) et fonctionne pour exactement 10000 ticks et le second est O(n^2) . Ainsi, dans la plage 1~100, la seconde sera plus rapide que la première (100^2 == 10000 donc (x<100)^2 < 10000 ). Mais à partir de 100 le deuxième algorithme sera plus lent que le premier.
Le comportement similaire est dans vos fonctions. Je les ai chronométrés avec différentes longueurs d'entrée et j'ai construit des tracés de chronométrage. Voici les horaires de vos fonctions sur les grands nombres (le jaune est sort , le bleu est heap ):
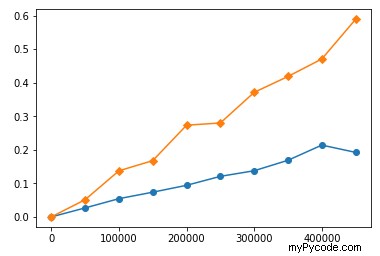
Vous pouvez voir que sort prend plus de temps que heap , et le temps augmente plus vite que heap's . Mais si nous regardons de plus près sur la gamme inférieure :
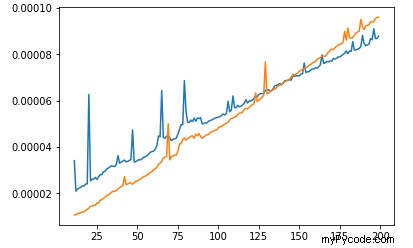
Nous verrons que sur petite plage sort est plus rapide que heap ! Ressemble à heap a une consommation de temps "par défaut". Il n'est donc pas faux que l'algorithme avec le pire Big-O fonctionne plus rapidement que l'algorithme avec le meilleur Big-O. Cela signifie simplement que leur plage d'utilisation est trop petite pour qu'un meilleur algorithme soit plus rapide que le pire.
Voici le code temporel du premier tracé :
import timeit
import matplotlib.pyplot as plt
s = """
import heapq
def k_heap(points, K):
return heapq.nsmallest(K, points, key = lambda P: P[0]**2 + P[1]**2)
def k_sort(points, K):
points.sort(key = lambda P: P[0]**2 + P[1]**2)
return points[:K]
"""
random.seed(1)
points = [(random.random(), random.random()) for _ in range(1000000)]
r = list(range(11, 500000, 50000))
heap_times = []
sort_times = []
for i in r:
heap_times.append(timeit.timeit('k_heap({}, 10)'.format(points[:i]), setup=s, number=1))
sort_times.append(timeit.timeit('k_sort({}, 10)'.format(points[:i]), setup=s, number=1))
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
#plt.plot(left, 0, marker='.')
plt.plot(r, heap_times, marker='o')
plt.plot(r, sort_times, marker='D')
plt.show()
Pour le deuxième tracé, remplacez :
r = list(range(11, 500000, 50000)) -> r = list(range(11, 200))
plt.plot(r, heap_times, marker='o') -> plt.plot(r, heap_times)
plt.plot(r, sort_times, marker='D') -> plt.plot(r, sort_times)
Comme cela a été discuté, la mise en œuvre rapide du tri à l'aide du tri tim en python est un facteur. L'autre facteur ici est que les opérations de tas ne sont pas aussi conviviales pour le cache que le tri par fusion et le tri par insertion (le tri par tim est l'hybride des deux).
Les opérations de tas accèdent aux données stockées dans des index distants.
Python utilise un tableau basé sur l'index 0 pour implémenter sa bibliothèque de tas. Ainsi, pour la kième valeur, ses indices de nœuds enfants sont k * 2 + 1 et k * 2 + 2.
Chaque fois que vous effectuez les opérations de percolation vers le haut/vers le bas après avoir ajouté/retiré un élément vers/du tas, il essaie d'accéder aux nœuds parents/enfants qui sont éloignés de l'index actuel. Ce n'est pas compatible avec le cache. C'est aussi pourquoi le tri par tas est généralement plus lent que le tri rapide, bien que les deux soient asymptotiquement identiques.