Vous êtes-vous déjà demandé comment vous pouvez tirer parti d'Apache Livy dans votre projet pour faire passer votre expérience avec le cluster Apache Spark au niveau supérieur ? J'ai élaboré un guide étape par étape qui vous aidera à atteindre cet objectif.
Pour exécuter un exemple de projet et tirer le meilleur parti de ce guide, vous devez d'abord installer le service de conteneur Docker. Si vous n'êtes pas familier avec les conteneurs, vous trouverez plus de détails dans la documentation Docker.
En lisant cet article, vous apprendrez à créer un cluster Spark avec le serveur Livy et JupyterLab basé sur l'environnement virtuel Docker.
Vous découvrirez également comment préparer la logique métier dans JupyterLab et découvrirez comment j'ai utilisé un exemple de projet pour exécuter du code PySpark via le service Livy.
Qu'est-ce qu'Apache Spark ? Pourquoi devriez-vous l'utiliser ?
Apache Spark est un moteur d'analyse utilisé pour traiter des pétaoctets de données de manière parallèle.
Grâce à des API et des structures simples à utiliser telles que RDD, un ensemble de données, un cadre de données avec une riche collection d'opérateurs, ainsi que la prise en charge de langages tels que Python, Scala, R, Java et SQL, il est devenu un outil préféré. pour les ingénieurs de données.
En raison de sa vitesse (il est jusqu'à 100 fois plus rapide que Hadoop MapReduce) et de sa flexibilité (par exemple, prise en charge des requêtes SQL, de l'apprentissage automatique, du streaming et du traitement des graphes), Apache Spark est déployé à grande échelle par des entreprises dans un large éventail de secteurs. .

Source :https://databricks.com/spark/about
Qu'est-ce qu'Apache Livy ? En quoi cela profite-t-il à votre projet ?
Apache Livy est un service qui permet une interaction facile avec un cluster Spark via l'API REST.
Certaines de ses fonctionnalités utiles incluent :
- soumettre des tâches sous forme de jars précompilés ou d'extraits de code en Python/Scala/R,
- exécuter des tâches Spark de manière synchrone ou asynchrone,
- gérer plusieurs SparkContexts simultanément,
- SparkContext de longue durée peut être réutilisé par de nombreuses tâches Spark,
- partager des RDD mis en cache ou des trames de données sur plusieurs tâches et clients,
- communication authentifiée sécurisée.
Vous vous demandez peut-être comment simplifier l'utilisation d'Apache Spark dans le traitement automatisé.
Par exemple, nous pouvons imaginer une situation où nous soumettons du code Spark écrit en Python ou Scala dans un cluster, tout comme nous soumettons des requêtes SQL dans un moteur de base de données. Si nous ne voulons pas jouer avec la ligne de commande pour atteindre le cluster directement en utilisant SSH, alors Apache Livy entre en jeu avec son interface API REST.
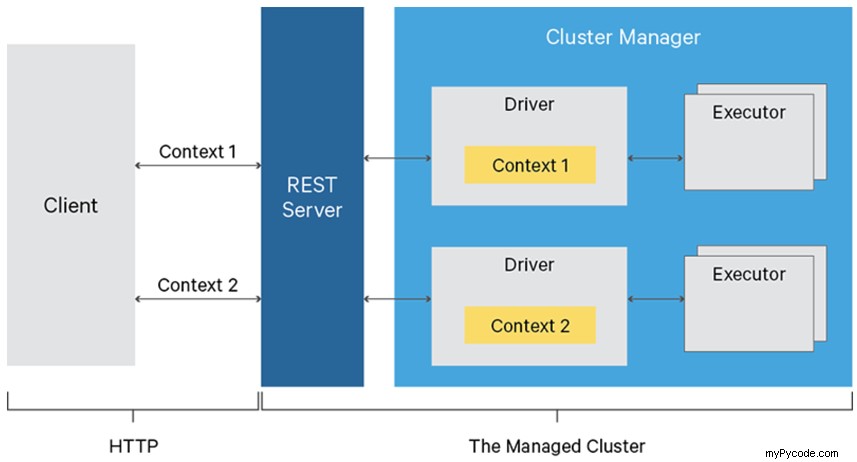
Source :https://livy.apache.org/assets/images/livy-architecture.png
Devez-vous créer une couche logique supplémentaire pour gérer les connexions et toutes les fonctionnalités de l'API REST ?
Non, heureusement, il existe une bibliothèque dédiée appelée pylivy que je vais utiliser dans l'exemple de projet. Vous pouvez trouver pylivy exemples et documentation ici.
Tester le concept d'utilisation d'Apache Livy dans les clusters Spark
Supposons que nous devions créer une application pour traiter certaines données client ou marché sur Spark et que notre application fonctionnera quotidiennement.
Du point de vue d'un développeur, nous devons d'abord préparer des scripts avec la logique métier. Ensuite, nous devons préparer les contrôleurs des tâches pour gérer la communication avec notre cluster Spark via l'API Livy REST.
Mais avant de développer quoi que ce soit, nous devons installer et configurer Livy et le cluster Spark.
Configuration requise
Comme je l'ai mentionné au début de cet article, pour garder le système d'exploitation exempt de dépendances, nous utilisons le service de conteneur Docker pour exécuter notre infrastructure. Donc, tout d'abord, nous devons préparer les fichiers Docker pour les conteneurs maître et travailleur Spark avec un conteneur séparé pour JupyterLab.
Installation et paramétrage des services
Si le service Docker n'est pas installé, suivez ces instructions pour le faire fonctionner sur votre ordinateur.
Si vous êtes ici, je suppose que Docker est prêt à exécuter nos conteneurs, nous pouvons donc nous concentrer sur le code.
Pour garder notre concept plus réaliste, j'ai décidé de scinder l'infrastructure en trois services distincts :
- jupyterlab,
- maître des étincelles,
- spark-worker-1.
De plus, pour garder la logique simple et claire, j'ai créé un dossier dédié aux services Docker appelé livy_poc_docker .
Dans un premier temps, nous allons créer une image de base.
L'image de base utilise Debian Linux et contient toutes les bibliothèques requises :python3, open-jdk-8 et des utilitaires, par ex. wget, curl et décompressez.
FROM debian:stretch
# System packages
RUN apt-get clean && apt-get update -y && \
apt-get install -y python3 python3-pip curl wget unzip procps openjdk-8-jdk && \
ln -s /usr/bin/python3 /usr/bin/python && \
rm -rf /var/lib/apt/lists/*
Pour simplifier la structure de l'image, j'ai décidé d'ajouter l'installation de Spark dans l'image de base. Pour une utilisation en production, Spark doit être ajouté à une image distincte.
# Install Spark
RUN curl https://apache.mirrors.tworzy.net/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz -o spark.tgz && \
tar -xf spark.tgz && \
mv spark-2.4.7-bin-hadoop2.7 /usr/bin/ && \
mkdir /usr/bin/spark-2.4.7-bin-hadoop2.7/logs && \
rm spark.tgz
Ensuite, j'ai créé les répertoires requis et configuré les variables d'environnement.
# Prepare dirs
RUN mkdir -p /tmp/logs/ && chmod a+w /tmp/logs/ && mkdir /app && chmod a+rwx /app && mkdir /data && chmod a+rwx /data
ENV JAVA_HOME=/usr
ENV SPARK_HOME=/usr/bin/spark-2.4.7-bin-hadoop2.7
ENV PATH=$SPARK_HOME:$PATH:/bin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
ENV SPARK_MASTER_HOST spark-master
ENV SPARK_MASTER_PORT 7077
ENV PYSPARK_PYTHON=/usr/bin/python
ENV PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
ENV APP=/app
ENV SHARED_WORKSPACE=/opt/workspace
RUN mkdir -p ${SHARED_WORKSPACE}
VOLUME ${SHARED_WORKSPACE}
Ensuite, j'ai créé une image pour le Spark master conteneur.
Le conteneur maître Spark est responsable de l'hébergement du nœud maître Spark et du service Livy.
Cette image est basée sur une image précédemment créée appelée mk-spark-base .
Des packages supplémentaires pour Python seront installés à cette étape.
FROM mk-spark-base
# Python packages
RUN pip3 install wget requests datawrangler
Et, bien sûr, nous ne pouvons pas oublier Apache Livy.
# Get Livy
RUN wget https://apache.mirrors.tworzy.net/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip -O livy.zip && \
unzip livy.zip -d /usr/bin/
Spark master sera l'image finale dont nous disposons pour exposer les ports et configurer le point d'entrée.
EXPOSE 8080 7077 8998 8888
WORKDIR ${APP}
ADD entryfile.sh entryfile.sh
ENTRYPOINT ["sh", "entryfile.sh"]
OK, la configuration de l'image principale est prête. Maintenant, nous avons besoin d'une image de travailleur .
Il est uniquement responsable de l'exécution du nœud Spark en mode travailleur, et rien d'autre.
Cette image utilise également le mk-spark-base image comme base.
FROM mk-spark-base
ENV APP=/app
ENV JAVA_HOME=/usr
ENV SPARK_HOME=/usr/bin/spark-2.4.7-bin-hadoop2.7
ENV PATH=$SPARK_HOME:$PATH:/bin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
ENV PYSPARK_PYTHON=/usr/bin/python
ENV PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
EXPOSE 8081 7077 8998 8888
WORKDIR ${APP}
CMD /usr/bin/spark-2.4.7-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker spark://${SPARK_MASTER_HOST}:${SPARK_MASTER_PORT} >> /tmp/logs/spark-worker.out
Il est maintenant temps de créer une configuration pour l'image JupyterLab . Appelons-le mk-jupyter .
FROM mk-spark-base
# Python packages
RUN pip3 install wget requests pandas numpy datawrangler findspark jupyterlab pyspark==2.4.7
EXPOSE 8888
WORKDIR ${SHARED_WORKSPACE}
CMD jupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root --NotebookApp.token=
C'est si simple ?
Enfin, nous avons la configuration pour tous les conteneurs de notre cluster, et il est temps de construire des images. Ce script simple exécute le `docker build` commande pour créer toutes les images requises.
# Builds images
docker build \
-f base.Dockerfile \
-t mk-spark-base .
docker build \
-f master.Dockerfile \
-t mk-spark-master .
docker build \
-f worker.Dockerfile \
-t mk-spark-worker .
docker build \
-f jupyter.Dockerfile \
-t mk-jupyter .
Exécutons-le dans la CLI :`sh build.sh`.
Pour démarrer les conteneurs déjà construits, nous devons préparer un fichier de composition Docker.
version: "3.6"
volumes:
shared-workspace:
name: "hadoop-distributed-file-system"
driver: local
services:
jupyterlab:
image: mk-jupyter
container_name: mk-jupyter
ports:
- 8888:8888
volumes:
- shared-workspace:/opt/workspace
spark-master:
image: mk-spark-master
container_name: mk-spark-master
ports:
- 8080:8080
- 7077:7077
- 8998:8998
volumes:
- shared-workspace:/opt/workspace
spark-worker-1:
image: mk-spark-worker
container_name: mk-spark-worker-1
environment:
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=512m
ports:
- 8081:8081
volumes:
- shared-workspace:/opt/workspace
depends_on:
- spark-master
Le fichier de composition Docker est responsable de l'orchestration des services et décrit les paramètres d'entrée tels que le nom du service, les ports, les volumes et les variables d'environnement, ainsi que les dépendances entre les services, le cas échéant.
Codage de la logique métier
Si vous êtes ici, je suppose que vous avez réussi toutes les étapes précédentes et que tous les conteneurs sont en cours d'exécution. Ceci est le site du serveur.
Maintenant, nous allons nous concentrer sur la logique métier de notre projet :le site client. Comme je l'ai mentionné précédemment, nous devons maintenant créer le script client pour communiquer avec le serveur Spark à l'aide de l'API REST.
Avant de commencer à coder, je recommande de créer un projet séparé dans lequel nous mettons notre code. Appelons-le livy_poc .
Pour jouer avec le serveur Livy, nous allons utiliser une bibliothèque Python appelée pylivy . Bien sûr, vous pouvez jouer avec l'API REST directement en utilisant les requêtes package mais à mon avis pylivy simplifiera beaucoup notre code.
Donc, d'abord, nous devons installer le pylivy requis package comme `pip install -U livy `.
C'est une pratique courante de créer un environnement virtuel dédié à un projet donné et d'installer tous les packages requis manuellement comme ci-dessus ou en utilisant le fichier requirements.txt `pip install -t requirements.txt` .
Vous pouvez trouver des informations utiles sur l'utilisation de venv ici.
Maintenant, nous pouvons créer un fichier appelé titanic_data.py et y mettre toute la logique.
Pour plus de simplicité, nous allons mettre toute la logique dans un seul fichier, mais dans un projet réel, il est recommandé de diviser la logique métier en plusieurs fichiers en fonction du framework ou de la structure de projet utilisée.
Dans le script client, nous devons importer tous les packages requis (livy et textwrap) pour rendre notre mode code convivial.
from livy import LivySession, SessionKind
import textwrap
Dans cet exemple, nous allons jouer avec l'ensemble de données Titanic, qui est très populaire et gratuit.
# Get and load Titanic data into Spark
get_titanic_data = textwrap.dedent(
"""
from pathlib import Path
import wget
data_file = Path("/opt/workspace/titanic.csv")
if not data_file.is_file():
url = "https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv"
wget.download(url, "/opt/workspace/titanic.csv")
"""
)
Comme vous pouvez le voir, nous avons intégré du code Python dans une chaîne multiligne et l'avons affecté à la variable Python get_titanic_data .
Nous pouvons traiter le code enveloppé par une chaîne multiligne comme un script de requête qui sera soumis à notre cluster Spark. Comme requête SQL dans le cas d'une base de données.
Remarquez les importations à l'intérieur de notre chaîne multiligne. Cela signifie que Spark doit importer ces packages avant d'exécuter le reste du code.
Maintenant, nous devons créer une SparkSession objet et chargez l'ensemble de données précédemment téléchargé dans un bloc de données Spark.
Ici vous pouvez trouver des importations supplémentaires de SparkSession , SQLContext libs, côté Spark.
load_to_spark = textwrap.dedent(
"""
from pyspark.sql import SparkSession, SQLContext
spark = SparkSession.\
builder.\
appName("pyspark-notebook-titanic").\
master("spark://spark-master:7077").\
config("spark.executor.memory", "512m").\
getOrCreate()
sql = SQLContext(spark)
data = sql.read.option("header", "true").option("inferSchema", "true").csv("/opt/workspace/titanic.csv")
print("---"*20)
print("Loaded rows:", data.count())
print("---"*20)
"""
)
Ci-dessous, vous pouvez voir la logique affectée aux variables qui seront exécutées sur l'ensemble de données Titanic sur le cluster Spark.
# Run some analysis
general_number_of_survived_passengers = textwrap.dedent(
"""
survived = data[data["Survived"] == 1]
survived_percent = survived.count()/data.count() * 100
print("Total number of passengers:", data.count())
print("Count of survived passengers:", survived.count())
print("Percent of survived passengers:", survived_percent)
"""
)
percent_of_survived_passengers_with_siblings_spouses = textwrap.dedent(
"""
sur_with_siblings = data[data["Siblings/Spouses Aboard"] != 0]
sur_with_siblings_percent = sur_with_siblings.count()/data.count() * 100
print("Count of passengers with siblings-spouses:", sur_with_siblings.count())
print("Percent of survived passengers with siblings-spouses", sur_with_siblings_percent)
"""
)
percent_of_survived_passengers_with_parent_children = textwrap.dedent(
"""
sur_with_parents = data[data["Parents/Children Aboard"] != 0]
sur_with_parents_percent = sur_with_parents.count()/data.count() * 100
print("Count of passengers with parents-children:", sur_with_parents.count())
print("Percent of survived passengers with parents-children", sur_with_parents_percent)
"""
)
some_aggregations = textwrap.dedent(
"""
grouped_passengers = data.groupby("pclass", "age", "survived").count() \
.orderBy(
data.Pclass,
data.Age.desc(),
data.Survived.asc()
)
print("---"*20)
print("Aggregated data:")
grouped_passengers.show(n=10)
print("---"*20)
"""
)
save_aggregations_as_parquet = textwrap.dedent(
"""
grouped_passengers.write \
.option("header", "true") \
.mode("overwrite") \
.parquet("/opt/workspace/titanic_grouped_passengers.parquet")
"""
)
Ce qui est important ici, c'est que le bloc de données source appelé data est utilisé et partagé par tous les extraits. Cela signifie que nous pouvons créer une variable ou un bloc de données à un endroit et l'utiliser à n'importe quel autre endroit de notre code dans une session Spark.
Il est maintenant temps de soumettre notre logique métier au cluster. Que se passe-t-il exactement ?
Dans le principal fonction, nous nous connecterons au serveur Livy et créerons la session objet. Ensuite, nous appellerons le run méthode et utiliser des variables avec une logique métier définie précédemment.
# Execute pyspark code
LIVY_SERVER = "http://127.0.0.1:8998"
def main():
with LivySession.create(LIVY_SERVER, kind=SessionKind.PYSPARK) as session:
session.run(get_titanic_data)
session.run(load_to_spark)
session.run(general_number_of_survived_passengers)
session.run(percent_of_survived_passengers_with_siblings_spouses)
session.run(percent_of_survived_passengers_with_parent_children)
session.run(some_aggregations)
session.run(save_aggregations_as_parquet)
# Let's download data locally from Spark as Pandas data frame
grouped_passengers_1 = session.read("grouped_passengers")
print("Spark data frame 'grouped_passengers' as local Pandas data frame:")
print("grouped_passengers_1: ", grouped_passengers_1)
# Run same aggregation using SparkSQL
session.run("data.createOrReplaceTempView('titanic_data')")
session.run(textwrap.dedent(
"""
grouped_passengers_2 = sql.sql(
'''
select pclass, age, survived, count(*) as cnt
from titanic_data
group by pclass, age, survived
'''
)
"""
))
# Read the result from spark as Pandas data frame
grouped_passengers_2 = session.read("grouped_passengers_2")
print("Spark data frame 'grouped_passengers' as local Pandas data frame generated by SparkSQL:")
print("grouped_passengers_2: ", grouped_passengers_2)
# Compare local data frames
print("---"*20)
print("Results comparison of Spark MR vs SparkSQL")
print(f"len(grouped_passengers_1) ==", str(len(grouped_passengers_1)))
print(f"len(grouped_passengers_2) ==", str(len(grouped_passengers_2)))
print("---"*20)
print("Spark session closed.")
if __name__ == "__main__":
main()
Comme vous pouvez le voir, nous avons utilisé deux méthodes différentes pour exécuter notre code Spark.
La course méthode est utilisée pour exécuter du code ; il renvoie un objet avec requête statut et texte contenant les dix premières lignes.
Cependant, si nous voulons utiliser les données traitées sur notre cluster Spark localement, nous pouvons utiliser le read méthode qui renvoie une trame de données Pandas.
De plus, Livy nous donne la possibilité d'utiliser SparkSQL (vous pouvez voir comment dans notre exemple simple). Vous pouvez également utiliser des méthodes dédiées telles que download_sql et read_sql .
Notamment, dans notre exemple, nous créons un objet de session en utilisant un with clause afin que nous n'ayons pas à nous soucier de fermer la session de Livy à la fin du script.
N'oubliez pas qu'après la fermeture d'une session Livy, tous les blocs de données, variables et objets seront définitivement détruits.
Exécution du cluster
Si vous avez installé pylivy à l'intérieur d'un environnement virtuel, il est temps de l'activer en `source my_venv/bin/activate `. Vous pouvez remplacer `source ` par `.` (un point).
Pour exécuter notre exemple de code, vous devez d'abord démarrer un serveur Docker sur votre machine. À l'étape suivante, à l'aide de la CLI, accédez à un projet avec la configuration des services Docker, dans ce cas appelé livy_poc_docker . Ensuite, écrivez le `docker-compose start ` et appuyez sur Entrée.
Après une ou deux minutes, lorsque tous les services s'exécutent à l'aide de la CLI, accédez au projet avec notre identifiant professionnel, dans notre cas appelé livy_poc .
Dans notre projet, écrivez `python tytanic_data.py ` et en sortie, vous devriez voir quelque chose comme ceci :
------------------------------------------------------------
Loaded rows: 887
------------------------------------------------------------
Total number of passengers: 887
Count of survived passengers: 342
Percent of survived passengers: 38.55693348365276
Count of passengers with siblings-spouses: 283
Percent of survived passengers with siblings-spouses 31.905298759864714
Count of passengers with parents-children: 213
Percent of survived passengers with parents-children 24.01352874859076
------------------------------------------------------------
Aggregated data:
+------+----+--------+-----+
|pclass| age|survived|count|
+------+----+--------+-----+
| 1|80.0| 1| 1|
| 1|71.0| 0| 2|
| 1|70.0| 0| 1|
| 1|65.0| 0| 2|
| 1|64.0| 0| 3|
| 1|63.0| 1| 1|
| 1|62.0| 0| 2|
| 1|62.0| 1| 1|
| 1|61.0| 0| 2|
| 1|60.0| 0| 2|
+------+----+--------+-----+
only showing top 10 rows
------------------------------------------------------------
Spark data frame 'grouped_passengers' as local Pandas data frame:
grouped_passengers_1: pclass age survived count
0 1 80.00 1 1
1 1 71.00 0 2
2 1 70.00 0 1
3 1 65.00 0 2
4 1 64.00 0 3
.. ... ... ... ...
277 3 2.00 1 2
278 3 1.00 0 2
279 3 1.00 1 3
280 3 0.75 1 2
281 3 0.42 1 1
[282 rows x 4 columns]
Spark data frame 'grouped_passengers' as local Pandas data frame generated by SparkSQL:
grouped_passengers_2: pclass age survived cnt
0 2 13.0 1 1
1 1 58.0 0 2
2 3 28.5 0 2
3 1 23.0 1 3
4 1 32.0 1 2
.. ... ... ... ...
277 3 22.0 1 9
278 2 21.0 0 5
279 2 33.0 1 2
280 3 20.0 1 4
281 1 60.0 1 2
[282 rows x 4 columns]
------------------------------------------------------------
Results comparison of Spark MR vs SparkSQL
len(grouped_passengers_1) == 282
len(grouped_passengers_2) == 282
------------------------------------------------------------
Spark session closed.
Surveillance de l'état dans Apache Livy, Apache Spark et JupyterLab
Enfin, nous avons tout mis en place. Mais comment pouvons-nous surveiller l'état du service ? Vous trouverez ci-dessous quelques conseils.
Surveillance des sessions Apache Livy
Pour vérifier l'état d'une session Livy, accédez à http://localhost:8998.
Si vous avez des sessions en cours, vous verrez la liste des sessions démarrées et leur statut.


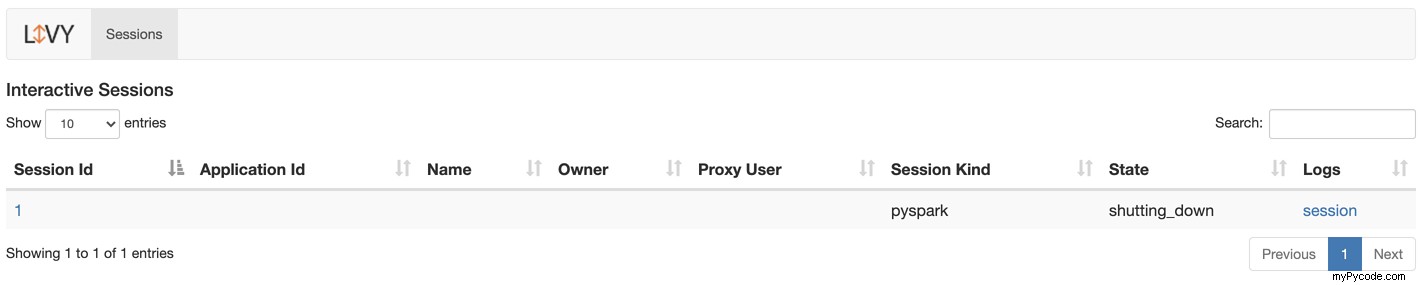
Vous pouvez cliquer sur le numéro de session pour voir les détails, tels que le code exécuté, le statut et la progression.
Si vous cliquez sur une session dans les journaux colonne pour voir tous les journaux de session, voici ce que vous verrez :
Et s'il n'y a pas de session en cours, vous verrez ceci :

Surveillance du cluster Apache Spark
Accédez à http://localhost:8080 pour vérifier le cluster Spark.
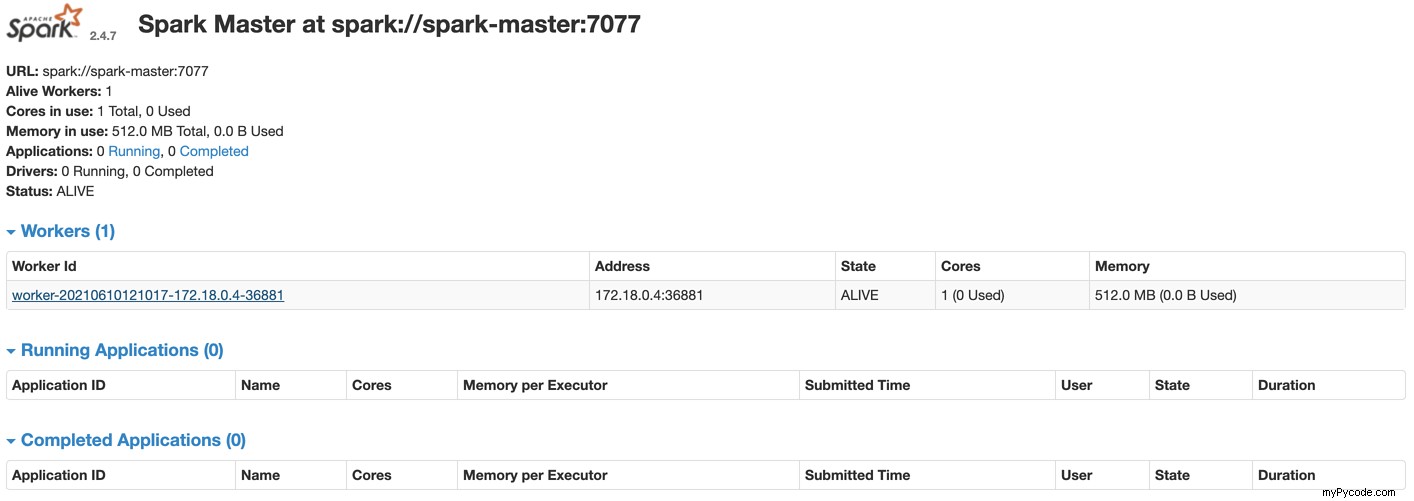
Développer avec JupyterLab
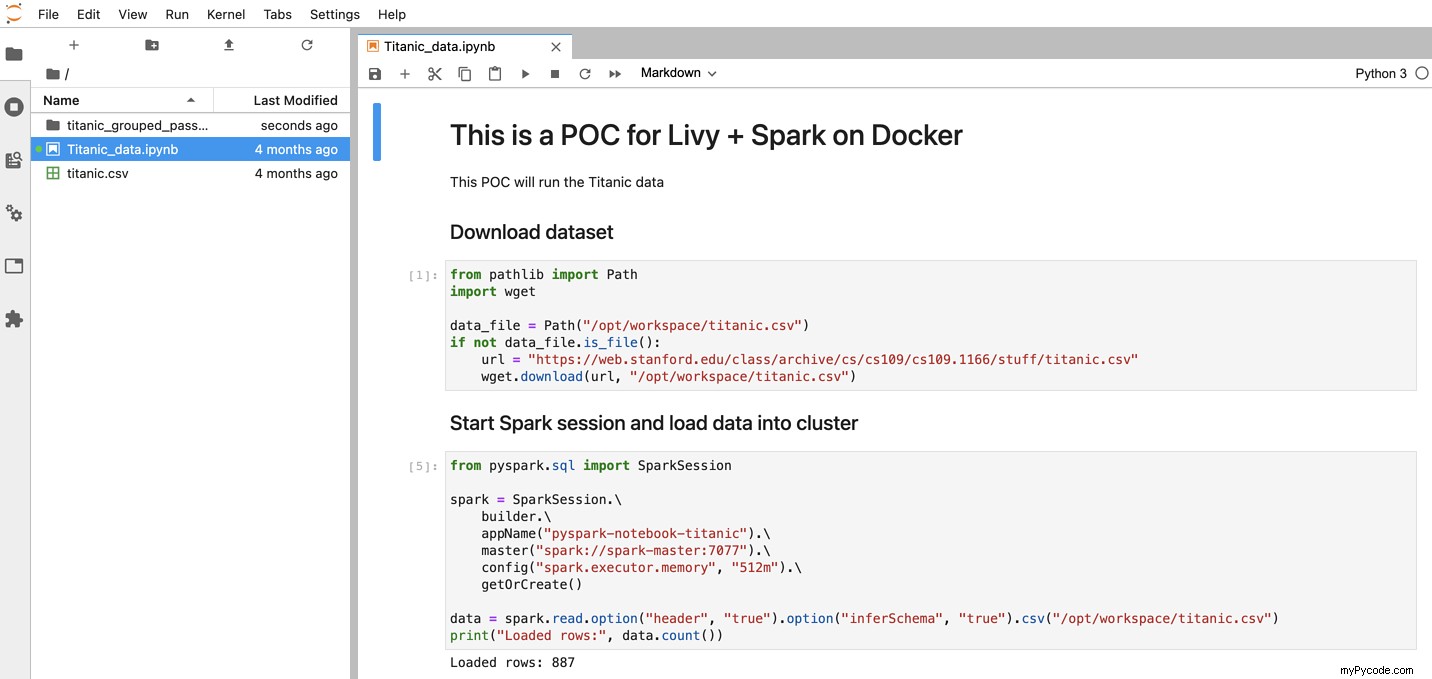
Il est maintenant temps d'expliquer pourquoi j'ai créé le service JupyterLab. Pour être honnête avec vous, j'aime beaucoup cette configuration car elle me donne la possibilité d'utiliser l'environnement JupyterLab pour développer et tester mes scripts Spark. Lorsqu'il est prêt, je peux les automatiser à l'aide de l'API Livy sans aucune autre configuration.
C'est ainsi que j'ai développé la logique métier de l'exemple présenté dans cet article.
Allez sur http://localhost:8888 pour voir l'interface de JupyterLab.
Réflexions finales sur l'API Apache Livy REST
Dans cet article, nous avons expliqué comment utiliser Apache Livy avec Spark et quels avantages Livy peut apporter à votre travail. J'ai également expliqué comment l'intégrer à un projet Python et préparer un projet simple basé sur l'environnement Docker, ce qui rend ce projet indépendant du système.
Même si cela peut sembler beaucoup à assimiler, rappelez-vous que ce que je vous ai montré n'est que la pointe de l'iceberg. Livy peut faire beaucoup plus, surtout si vous utilisez pylivy comme couche d'abstraction. Cela vous donnera un outil puissant pour créer et gérer vos tâches Spark à partir de votre application ou pour créer des pipelines de données plus flexibles.
Si vous décidez d'utiliser Apache Livy dans votre prochain projet, il sera avantageux pour vous de vous familiariser d'abord avec la documentation pylivy. Vous y trouverez de nombreuses classes et méthodes utiles qui rendent l'utilisation de Livy très efficace et simple.
En tant que Python Powerhouse en Europe, nous avons de nombreux autres guides techniques comme celui-ci à vous proposer. Nous pouvons également répondre à tous vos besoins en développement logiciel. Tout ce que vous avez à faire est de nous contacter et nous verrons avec plaisir si nous pouvons faire quelque chose pour vous !
Ressources supplémentaires et lectures complémentaires
Docker
- https://www.docker.com/get-started
Apache Livy
- https://livy.apache.org/
- https://livy.apache.org/docs/latest/rest-api.html
- https://livy.incubator.apache.org/examples/
PyLivy
- https://pylivy.readthedocs.io/en/stable/
- https://pylivy.readthedocs.io/en/stable/api/session.html
Apache Spark
- https://spark.apache.org/
- https://spark.apache.org/examples.html
JupyterLab
- https://jupyter.org/