La visualisation des données est un élément essentiel de la science des données. Nous vous montrons comment tracer des moyennes glissantes à l'aide de matplotlib
La moyenne mobile, également connue sous le nom de moyenne mobile ou moyenne mobile, peut aider à filtrer le bruit et à créer une courbe lisse à partir de données de séries chronologiques. Cela peut également aider à mettre en évidence différents cycles saisonniers dans les données de séries chronologiques. Il s'agit d'un outil très courant utilisé dans de nombreux domaines, de la physique aux sciences de l'environnement et à la finance.
Dans cet article, nous expliquons ce qu'est la moyenne mobile et comment elle est calculée. Nous vous montrons également comment visualiser les résultats à l'aide de matplotlib en Python. Nous discutons en outre de certains éléments importants à comprendre sur les moyennes mobiles pour vous aider à améliorer vos compétences en analyse de données.
Cet article s'adresse aux personnes ayant un peu d'expérience dans l'analyse de données. Si vous cherchez une introduction à la science des données, nous avons un cours qui fournit les compétences de base. Pour plus de matériel qui s'appuie sur cela, jetez un œil à cette piste de science des données.
Qu'est-ce qu'une moyenne mobile ?
Pour générer une moyenne mobile, nous devons décider d'une taille de fenêtre dans laquelle calculer les valeurs moyennes. Il peut s'agir de n'importe quel nombre compris entre 2 et n-1, où n est le nombre de points de données dans la série temporelle. Nous définissons une fenêtre, calculons une moyenne dans la fenêtre, faisons glisser la fenêtre d'un point de données et répétons jusqu'à la fin.
Pour le démontrer, définissons quelques données et calculons une moyenne mobile en Python dans une boucle for :
>>> import numpy as np >>> data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> window = 2 >>> average_data = [] >>> for ind in range(len(data) – window + 1): ... average_data.append(np.mean(data[ind:ind+window]))
Ici, nous définissons une taille de fenêtre de 2 points de données et utilisons une tranche de liste pour obtenir le sous-ensemble de données que nous voulons moyenner. Ensuite, nous utilisons NumPy pour calculer la valeur moyenne. L'index est ensuite avancé avec une boucle for, et nous répétons. Remarquez que la boucle est terminée len(data) – window + 1 , ce qui signifie que nos données lissées ne comportent que 9 points de données.
Si vous souhaitez comparer la moyenne mobile aux données d'origine, vous devez les aligner correctement. Un moyen pratique de le faire est d'insérer un NaN au début de la liste en utilisant list.insert() . Essayez-le par vous-même.
Tracé d'une moyenne mobile dans matplotlib
En conséquence de cette méthode de lissage des données, les caractéristiques (par exemple, les pics ou les creux) dans un graphique d'une moyenne mobile sont en retard sur les caractéristiques réelles des données d'origine. L'amplitude des valeurs est également différente des données réelles. Il est important de garder cela à l'esprit si vous souhaitez identifier quand un pic dans les données s'est produit et quelle est son ampleur.
Pour le démontrer, nous pouvons créer une onde sinusoïdale et calculer une moyenne mobile en Python comme nous l'avons fait précédemment :
>>> x = np.linspace(0, 10, 50) >>> y = np.sin(x) >>> window = 5 >>> average_y = [] >>> for ind in range(len(y) - window + 1): ... average_y.append(np.mean(y[ind:ind+window]))
Voici comment ajouter NaNs au début de la moyenne mobile pour s'assurer que la liste a la même longueur que les données d'origine :
>>> for ind in range(window - 1): ... average_y.insert(0, np.nan)
Maintenant, nous pouvons tracer les résultats en utilisant matplotlib :
>>> import matplotlib.pyplot as plt >>> plt.figure(figsize=(10, 5)) >>> plt.plot(x, y, 'k.-', label='Original data') >>> plt.plot(x, average_y, 'r.-', label='Running average') >>> plt.yticks([-1, -0.5, 0, 0.5, 1]) >>> plt.grid(linestyle=':') >>> plt.legend() >>> plt.show()
L'exécution du code ci-dessus produit le tracé suivant dans une nouvelle fenêtre :
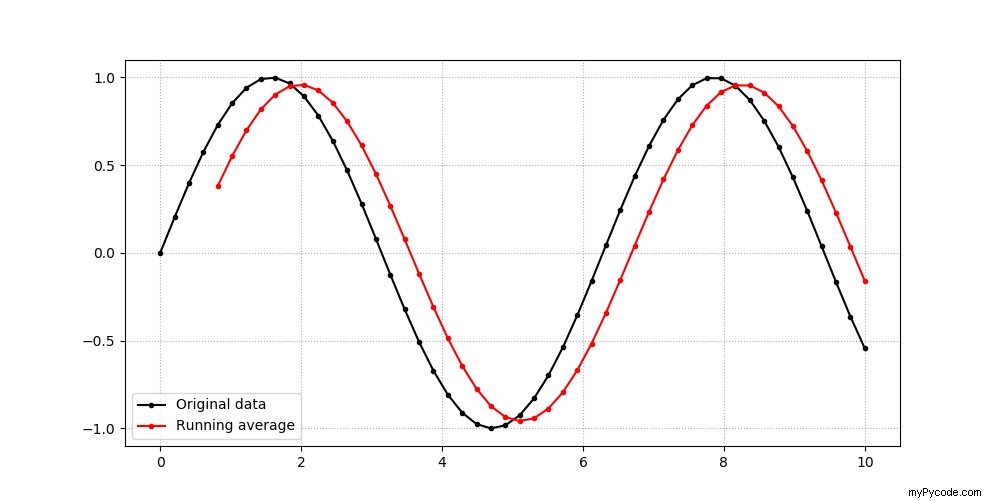
Plus la taille de la fenêtre est grande, plus les décalages des pics et des creux sont grands, mais plus les données sont lisses. Vous devez tester quelques valeurs pour déterminer le meilleur équilibre pour votre cas d'utilisation particulier.
Un bon exercice pour avoir une idée de cela consiste à prendre l'exemple de code ci-dessus et à ajouter du bruit à l'onde sinusoïdale. Le bruit peut être des nombres aléatoires entre, par exemple, 0 et 1. Ensuite, lissez les données en calculant la moyenne mobile, puis tracez les deux courbes.
Qu'en est-il des pandas ?
La bibliothèque pandas est devenue l'épine dorsale de l'analyse de données en Python. Sa structure de données de base est Series.
pandas est livré avec de nombreuses fonctions intégrées pour faciliter le traitement des données, y compris des fonctions pour calculer les moyennes glissantes. C'est aussi très utile pour nettoyer les données, dont nous parlons dans cet article.
Dans la plupart des cas, vous avez vos données dans un fichier que vous pouvez lire dans un bloc de données. Nous avons deux articles utiles :comment lire les fichiers CSV et comment lire les fichiers Excel en Python. Cet article ne se concentre pas sur la façon de charger des données à l'aide de pandas, nous supposons donc que vous avez déjà chargé vos données et que vous êtes prêt à commencer le traitement et le traçage. Si vous souhaitez des informations sur l'utilisation des blocs de données dans les pandas, consultez cet article.
Pour cet exemple, nous disposons d'environ 7 mois de relevés de température quotidiens depuis Berlin, allant de janvier 2021 à fin juillet 2021. La moyenne mobile sur une semaine peut être calculée par :
>>> temperature = df['temp'] >>> t_average = temperature.rolling(window=7).mean()
C'est super pratique, car il calcule rapidement et facilement une moyenne mobile (c'est-à-dire une moyenne mobile) sur la fenêtre que vous définissez dans rolling() . De plus, il aligne automatiquement les données correctement et remplit les données manquantes avec NaN . Maintenant, nous pouvons utiliser matplotlib pour tracer les résultats :
>>> plt.figure(figsize=(10, 5))
>>> plt.plot(temperature, 'k-', label='Original')
>>> plt.plot(t_average, 'r-', label='Running average')
>>> plt.ylabel('Temperature (deg C)')
>>> plt.xlabel('Date')
>>> plt.grid(linestyle=':')
>>> plt.fill_between(t_average.index, 0, t_average, color='r', alpha=0.1)
>>> plt.legend(loc='upper left')
>>> plt.show()
Cela ouvre la figure suivante dans une nouvelle fenêtre :
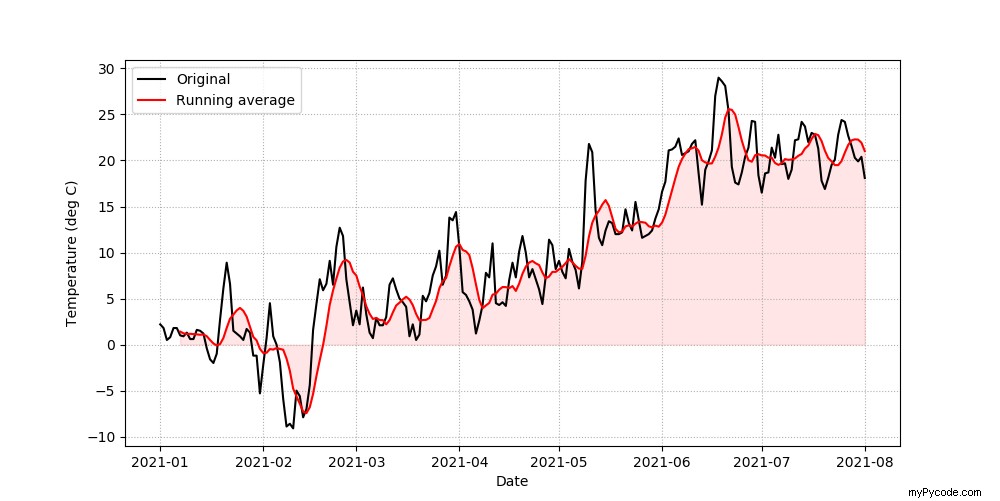
Vous devriez remarquer ici que nous n'avons spécifié les valeurs y que lorsque nous avons appelé plot(). En effet, l'index du bloc de données inclut les dates, ce qui est reconnu et automatiquement géré par pandas.
Dans ce graphique, vous pouvez voir la tendance à l'augmentation de la température allant de l'hiver à l'été. Il existe également une variation sur les petites échelles de temps qui ressort des données lissées produites à partir de la moyenne mobile sur 7 jours. L'ajout du quadrillage aide à guider l'œil vers les valeurs de date et de température pertinentes ; l'ombrage sous la moyenne mobile aide à souligner sa valeur au-dessus ou en dessous de zéro degré.
Faites passer les moyennes glissantes en Python au niveau supérieur
Dans cet article, nous vous avons montré comment calculer une moyenne mobile en Python et tracer les résultats à l'aide de matplotlib. Le traçage est une compétence cruciale pour comprendre les données. Pour une démonstration sur l'utilisation de matplotlib pour visualiser les données sonores, consultez cet article.
Si vous travaillez beaucoup avec des données tabulaires, il est important de présenter les tableaux de manière visuellement attrayante. Nous avons un article sur les jolies tables d'impression en Python.
Pour cet article, chaque point de données dans la fenêtre de calcul de la moyenne a contribué de manière égale à la moyenne. Cependant, cela ne doit pas nécessairement être le cas. Une moyenne mobile exponentielle, par exemple, accorde plus de poids aux données récentes, ce qui aide à résoudre le problème du décalage.
Nous aimerions vous encourager à utiliser ce que vous avez appris ici et à jouer un peu avec. Essayez d'implémenter une moyenne mobile exponentielle et voyez comment elle fonctionne pour lisser une onde sinusoïdale bruyante. Avec un peu de pratique, vous ferez passer vos compétences Python au niveau supérieur.