Les nuages de points sont un outil clé dans l'arsenal de tout analyste de données. Si vous voulez voir la relation entre deux variables, vous allez généralement créer un nuage de points.
Dans cet article, vous apprendrez les concepts de base et intermédiaires pour créer de superbes nuages de points matplotlib.
Exemple de diagramme de dispersion minimal
Le code suivant montre un exemple minimal de création d'un nuage de points en Python.
import matplotlib.pyplot as plt x = [0, 1, 2, 3, 4, 5] y = [1, 2, 4, 8, 16, 32] plt.plot(x, y, 'o') plt.show()
Vous effectuez les étapes suivantes :
- Importer le module matplotlib.
- Créer les données pour le
(x,y)points. - Tracer les données en utilisant le
plt.plot()fonction. Le premier argument est l'itérable dexvaleurs. Le deuxième argument est l'itérable deyvaleurs. Le troisième argument est le style des points de dispersion.
Voici à quoi ressemble le résultat :
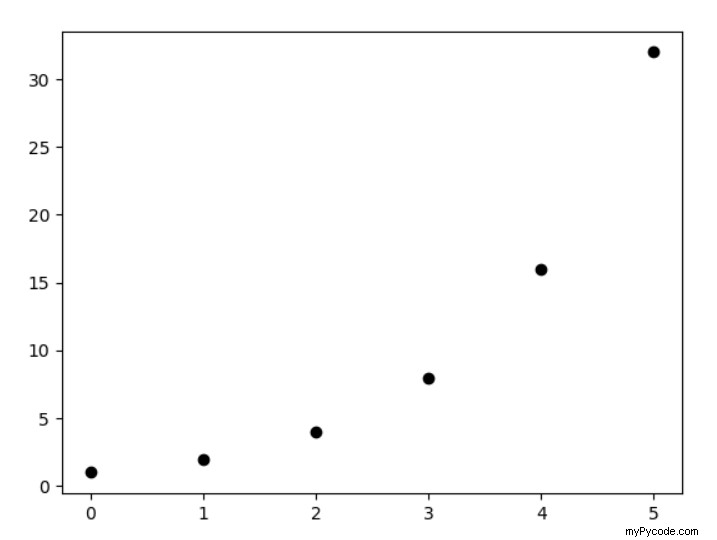
Cependant, vous n'aimerez peut-être pas le style de ce nuage de points. Plongeons-nous ensuite dans un exemple plus avancé !
Exemple de diagramme de dispersion Matplotlib
Imaginons que vous travailliez dans un restaurant. Vous êtes payé un petit salaire et gagnez ainsi la majeure partie de votre argent grâce aux pourboires. Vous voulez gagner le plus d'argent possible et donc maximiser le nombre de pourboires. Au cours du dernier mois, vous avez attendu 244 tables et collecté des données à leur sujet.
Nous allons explorer ces données à l'aide de nuages de points. Nous voulons voir s'il existe des relations entre les variables. S'il y en a, nous pouvons les utiliser pour gagner plus à l'avenir.
- Remarque :cet ensemble de données est intégré dans le cadre du
seabornbibliothèque.
Tout d'abord, importons les modules que nous allons utiliser et chargeons le jeu de données.
import matplotlib.pyplot as plt
import seaborn as sns
# Optional step
# Seaborn's default settings look much nicer than matplotlib
sns.set()
tips_df = sns.load_dataset('tips')
total_bill = tips_df.total_bill.to_numpy()
tip = tips_df.tip.to_numpy()
La variable tips_df est un DataFrame pandas. Ne vous inquiétez pas si vous ne comprenez pas encore ce que c'est. Les variables total_bill et tip sont tous deux des tableaux NumPy.
Faisons un nuage de points de total_bill contre pointe. C'est très facile à faire dans matplotlib - utilisez le plt.scatter() fonction. On passe d'abord la variable de l'axe des x, puis celle de l'axe des y. Nous appelons la première la variable indépendante et ce dernier la variable dépendante . Un graphique en nuage de points montre ce qui arrive à la variable dépendante (y ) lorsque nous changeons la variable indépendante (x ).
plt.scatter(total_bill, tip) plt.show()
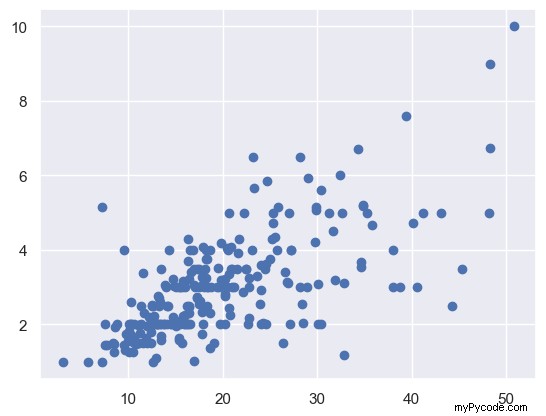
Agréable! Il semble qu'il y ait une corrélation positive entre un total_bill et tip . Cela signifie que plus la facture augmente, plus le pourboire augmente. Nous devons donc essayer d'inciter nos clients à dépenser le plus possible.
Nuage de points Matplotlib avec étiquettes
Les étiquettes sont le texte sur les axes. Ils nous en disent plus sur l'intrigue et est-il essentiel que vous les incluiez dans chaque intrigue que vous créez.
Ajoutons quelques étiquettes d'axe et un titre pour faciliter la compréhension de notre nuage de points.
plt.scatter(total_bill, tip)
plt.title('Total Bill vs Tip')
plt.xlabel('Total Bill ($)')
plt.ylabel('Tip ($)')
plt.show() 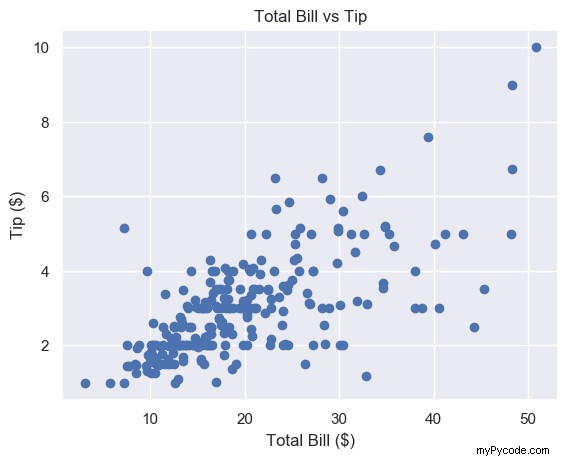
Beaucoup mieux. Pour économiser de l'espace, nous n'inclurons plus l'étiquette ou le code de titre à partir de maintenant, mais assurez-vous de le faire.
Cela a l'air bien mais les marqueurs sont assez grands. Il est difficile de voir la relation dans la fourchette de facture totale de 10 $ à 30 $.
Nous pouvons résoudre ce problème en modifiant la taille du marqueur.
Taille du marqueur de dispersion Matplotlib
Le s l'argument du mot-clé contrôle la taille de marqueurs en plt.scatter() . Il accepte un scalaire ou un tableau.
Taille du marqueur de dispersion Matplotlib – Scalaire
Dans plt.scatter() , la taille de marqueur par défaut est s=72 .
Les docs définissent s comme :
Taille du marqueur en points**2.
Cela signifie que si nous voulons qu'un marqueur ait la zone 5, nous devons écrire s=5**2 .
Les autres fonctions matplotlib ne définissent pas la taille du marqueur de cette manière. Pour la plupart d'entre eux, si vous voulez des marqueurs avec la zone 5, vous écrivez s=5 . Nous ne savons pas pourquoi plt.scatter() définit cela différemment.
Une façon de se souvenir de cette syntaxe est que les graphes sont constitués de régions carrées. Les marqueurs colorent certaines zones de ces régions. Pour obtenir l'aire d'une région carrée, nous faisons length**2 . Pour plus d'informations, consultez cette réponse Stack Overflow.
Pour définir la meilleure taille de marqueur pour un nuage de points, dessinez-le plusieurs fois avec différents s valeurs.
# Small s plt.scatter(total_bill, tip, s=1) plt.show()
Un petit nombre rend chaque marqueur petit. Réglage s=1 est trop petit pour ce graphique et le rend difficile à lire. Pour certains tracés avec beaucoup de données, le réglage s à un très petit nombre facilite grandement la lecture.
# Big s plt.scatter(total_bill, tip, s=100) plt.show()
Alternativement, un grand nombre agrandit les marqueurs. C'est trop grand pour notre intrigue et obscurcit une grande partie des données.
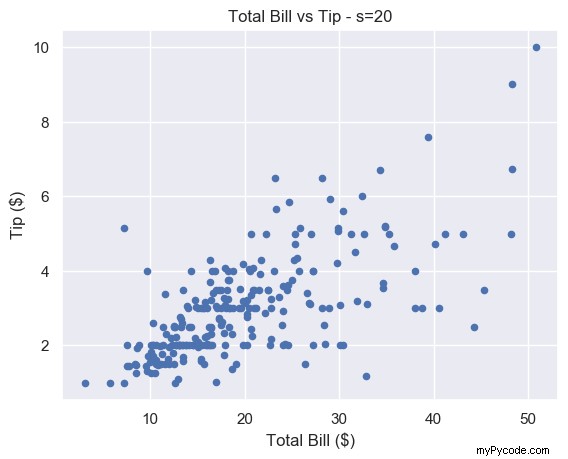
Nous pensons que s=20 trouve un bel équilibre pour cette parcelle particulière.
# Just right plt.scatter(total_bill, tip, s=20) plt.show()
Il y a encore un certain chevauchement entre les points, mais il est plus facile à repérer. Et contrairement à s=1 , vous n'avez pas à vous forcer pour voir les différents marqueurs.
Taille du marqueur de dispersion Matplotlib - Tableau
Si nous passons un tableau à s , nous définissons la taille de chaque point individuellement. Ceci est incroyablement utile, utilisons pour afficher plus de données sur notre nuage de points. Nous pouvons l'utiliser pour modifier la taille de nos marqueurs en fonction d'une autre variable.
Vous avez également enregistré la taille de chacune des tables que vous avez attendues. Ceci est stocké dans le tableau NumPy size_of_table . Il contient des nombres entiers compris entre 1 et 6, représentant le nombre de personnes que vous avez servies.
# Select column 'size' and turn into a numpy array size_of_table = tips_df['size'].to_numpy() # Increase marker size to make plot easier to read size_of_table_scaled = [3*s**2 for s in size_of_table] plt.scatter(total_bill, tip, s=size_of_table_scaled) plt.show()
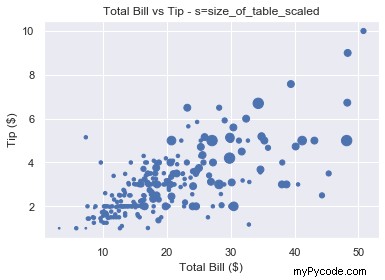
Non seulement le pourboire augmente lorsque la facture totale augmente, mais servir plus de personnes entraîne également un pourboire plus important. Cela correspond à ce à quoi nous nous attendions et c'est formidable que nos données correspondent à nos hypothèses.
Pourquoi avons-nous mis à l'échelle le size_of_table valeurs avant de le passer à s ? Parce que le changement de taille n'est pas visible si nous définissons s=1 , …, s=6 comme indiqué ci-dessous.
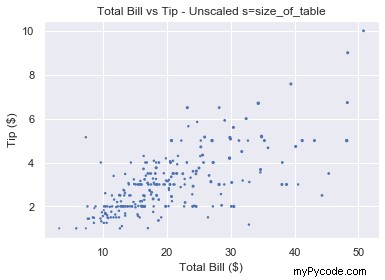
Donc, nous mettons d'abord au carré chaque valeur et la multiplions par 3 pour rendre la différence de taille plus prononcée.
Nous devrions tout étiqueter sur nos graphiques, alors ajoutons une légende.
Légende de dispersion Matplotlib
Pour ajouter une légende, nous utilisons le plt.legend() fonction. Ceci est facile à utiliser avec des tracés linéaires. Si nous dessinons plusieurs lignes sur un graphique, nous les étiquetons individuellement en utilisant le label mot-clé. Ensuite, lorsque nous appelons le plt.legend() , matplotlib dessine une légende avec une entrée pour chaque ligne.
Mais nous avons un problème. Nous n'avons ici qu'un seul ensemble de données. Nous ne pouvons pas étiqueter les points individuellement en utilisant le label mot-clé.
Comment résoudre ce problème ?
Nous pourrions créer 6 ensembles de données différents, les tracer les uns sur les autres et donner à chacun une taille et une étiquette différentes. Mais cela prend du temps et n'est pas évolutif.
Heureusement, matplotlib a une méthode de diagramme de dispersion que nous pouvons utiliser. Il s'appelle le legend_elements() car nous voulons étiqueter les différents éléments de notre nuage de points.
Les éléments de ce nuage de points sont de tailles différentes. Nous avons 6 points de tailles différentes pour représenter les 6 tables de tailles différentes. Nous voulons donc legend_elements() pour diviser notre intrigue en 6 sections que nous pouvons étiqueter sur notre légende.
Voyons comment legend_elements() œuvres. Tout d'abord, que se passe-t-il lorsque nous l'appelons sans aucun argument ?
# legend_elements() is a method so we must name our scatter plot scatter = plt.scatter(total_bill, tip, s=size_of_table_scaled) legend = scatter.legend_elements() print(legend) # ([], [])
Appel legend_elements() sans paramètre, renvoie un tuple de longueur 2. Il contient deux listes vides.
Les docs nous disent legend_elements() renvoie le tuple (handles, labels) . Les poignées sont les parties du tracé que vous souhaitez étiqueter. Les étiquettes sont les noms qui apparaîtront dans la légende. Pour notre intrigue, les poignées sont les marqueurs de différentes tailles et les étiquettes sont les chiffres 1-6. Le plt.legend() La fonction accepte 2 arguments :handles et labels.
Le plt.legend() la fonction accepte deux arguments :plt.legend(handles, labels) . Comme scatter.legend_elements() est un tuple de longueur 2, nous avons deux options. On peut soit utiliser l'astérisque * opérateur pour le déballer ou nous pouvons le déballer nous-mêmes.
# Method 1 - unpack tuple using * legend = scatter.legend_elements() plt.legend(*legend) # Method 2 - unpack tuple into 2 variables handles, labels = scatter.legend_elements() plt.legend(handles, labels)
Les deux produisent le même résultat. Les documents matplotlib utilisent la méthode 1. Pourtant, la méthode 2 nous donne plus de flexibilité. Si nous n'aimons pas les étiquettes créées par matplotlib, nous pouvons les écraser nous-mêmes (comme nous le verrons dans un instant).
Actuellement, handles et labels sont des listes vides. Changeons cela en passant quelques arguments à legend_elements() .
Il y a 4 arguments optionnels mais concentrons-nous sur le plus important :prop .
Prop – la propriété du nuage de points que vous souhaitez mettre en évidence dans votre légende. La valeur par défaut est 'colors' , l'autre option est 'sizes' .
Nous examinerons différents nuages de points colorés dans la section suivante. Comme notre tracé contient 6 marqueurs de tailles différentes, nous définissons prop='sizes' .
scatter = plt.scatter(total_bill, tip, s=size_of_table_scaled) handles, labels = scatter.legend_elements(prop='sizes')
Regardons maintenant le contenu de handles et labels .
>>> type(handles) list >>> len(handles) 6 >>> handles [<matplotlib.lines.Line2D object at 0x1a2336c650>, <matplotlib.lines.Line2D object at 0x1a2336bd90>, <matplotlib.lines.Line2D object at 0x1a2336cbd0>, <matplotlib.lines.Line2D object at 0x1a2336cc90>, <matplotlib.lines.Line2D object at 0x1a2336ce50>, <matplotlib.lines.Line2D object at 0x1a230e1150>]
Handles est une liste de longueur 6. Chaque élément de la liste est un matplotlib.lines.Line2D objet. Vous n'avez pas besoin de comprendre exactement ce que c'est. Sachez simplement que si vous passez ces objets à plt.legend() , matplotlib rend un 'picture' approprié . Pour les lignes colorées, c'est une ligne courte de cette couleur. Dans ce cas, il s'agit d'un seul point et chacun des 6 points aura une taille différente.
Il est possible de créer des poignées personnalisées, mais cela sort du cadre de cet article. Regardons maintenant labels .
>>> type(labels)
list
>>> len(labels)
6
>>> labels
['$\\mathdefault{3}$',
'$\\mathdefault{12}$',
'$\\mathdefault{27}$',
'$\\mathdefault{48}$',
'$\\mathdefault{75}$',
'$\\mathdefault{108}$']
Encore une fois, nous avons une liste de longueur 6. Chaque élément est une chaîne. Chaque chaîne est écrite en utilisant la notation LaTeX '$...$' . Les étiquettes sont donc les chiffres 3, 12, 27, 48, 75 et 108.
Pourquoi ces chiffres ? Parce que ce sont les valeurs uniques dans la liste size_of_table_scaled . Cette liste définit la taille du marqueur.
>>> np.unique(size_of_table_scaled) array([ 3, 12, 27, 48, 75, 108])
Nous avons utilisé ces nombres parce que l'utilisation de 1 à 6 n'est pas une différence de taille suffisante pour que les humains le remarquent.
Cependant, pour notre légende, nous souhaitons utiliser les chiffres 1 à 6 car il s'agit de la taille réelle du tableau. Alors écrasons labels .
labels = ['1', '2', '3', '4', '5', '6']
Notez que chaque élément doit être une chaîne.
Nous avons maintenant tout ce dont nous avons besoin pour créer une légende. Mettons cela ensemble.
# Increase marker size to make plot easier to read size_of_table_scaled = [3*s**2 for s in size_of_table] # Scatter plot with marker sizes proportional to table size scatter = plt.scatter(total_bill, tip, s=size_of_table_scaled) # Generate handles and labels using legend_elements method handles, labels = scatter.legend_elements(prop='sizes') # Overwrite labels with the numbers 1-6 as strings labels = ['1', '2', '3', '4', '5', '6'] # Add a title to legend with title keyword plt.legend(handles, labels, title='Table Size') plt.show()
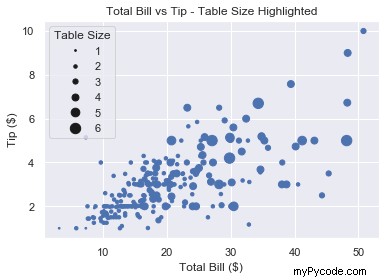
Parfait, nous avons une légende qui montre au lecteur exactement ce que représente le graphique. Il est facile à comprendre et ajoute beaucoup de valeur à l'intrigue.
Voyons maintenant une autre façon de représenter plusieurs variables sur notre nuage de points :la couleur.
Couleur du nuage de points Matplotlib
La couleur est une partie extrêmement importante du traçage. Cela pourrait être un article entier en soi. Consultez les documents Seaborn pour un excellent aperçu.
La couleur peut faire ou défaire votre intrigue. Certaines combinaisons de couleurs rendent ridiculement facile la compréhension des données. D'autres le rendent impossible.
Cependant, l'une des raisons de changer la couleur est purement esthétique.
On choisit la couleur des points en plt.scatter() avec le mot clé c ou color .
Vous pouvez définir la couleur de votre choix à l'aide d'un tuple RVB ou RVBA (rouge, vert, bleu, alpha). Chaque élément de ces tuples est un flottant dans [0.0, 1.0] . Vous pouvez également passer une chaîne hexadécimale RGB ou RGBA telle que '#1f1f1f' . Cependant, la plupart du temps, vous utiliserez l'une des plus de 50 couleurs nommées intégrées. Les plus courantes sont :
'b'ou'blue''r'ou'red''g'ou'green''k'ou'black''w'ou'white'
Voici le tracé de total_bill contre tip utiliser des couleurs différentes
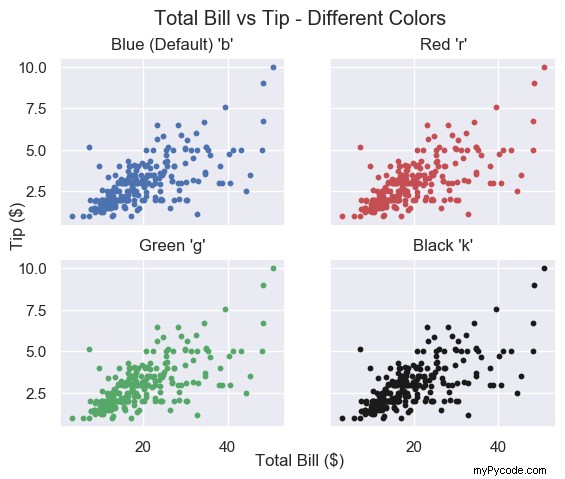
Pour chaque parcelle, appelez le plt.scatter() avec total_bill et pourboire et définir color (ou c ) à votre choix
# Blue (the default value) plt.scatter(total_bill, tip, color='b') # Red plt.scatter(total_bill, tip, color='r') # Green plt.scatter(total_bill, tip, c='g') # Black plt.scatter(total_bill, tip, c='k')
Remarque :on met les tracés sur une figure pour gagner de la place. Nous expliquerons comment procéder dans un autre article (indice :utilisez plt.subplots() )
Matplotlib Scatter Plot Différentes Couleurs
Notre restaurant dispose d'un espace fumeur. Nous voulons voir si un groupe assis dans la zone fumeurs affecte le montant de leur pourboire.
Nous pourrions le montrer en modifiant la taille des marqueurs comme ci-dessus. Mais cela n'a pas beaucoup de sens de le faire. Un plus grand groupe implique logiquement un plus grand marqueur. Mais la taille du marqueur et le fait d'être fumeur n'ont aucun lien et peuvent être déroutants pour le lecteur.
Au lieu de cela, nous colorerons nos marqueurs différemment pour représenter les fumeurs et les non-fumeurs.
Nous avons divisé nos données en quatre tableaux NumPy :
- Axe des abscisses :non_smoking_total_bill, smoking_total_bill
- Axe des ordonnées :non_smoking_tip, smoking_tip
Si vous dessinez plusieurs nuages de points à la fois, matplotlib les colore différemment. Cela facilite la reconnaissance des différents ensembles de données.
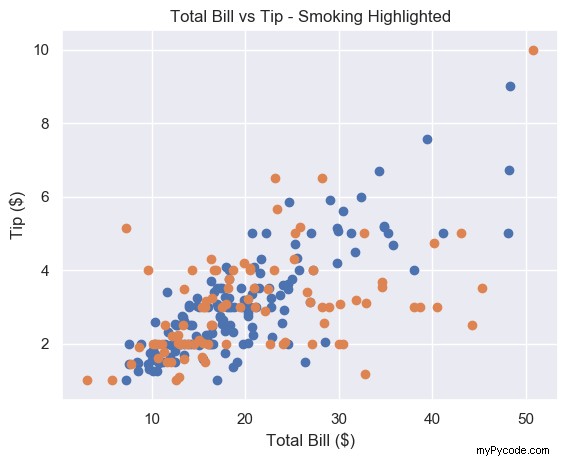
plt.scatter(non_smoking_total_bill, non_smoking_tip) plt.scatter(smoking_total_bill, smoking_tip) plt.show()
Cela a l'air génial. Il est très facile de distinguer les marqueurs orange et bleu. Le seul problème, c'est qu'on ne sait pas qui est quoi. Ajoutons une légende.
Comme nous avons 2 plt.scatter() appels, nous pouvons étiqueter chacun d'eux, puis appeler le plt.legend() .
# Add label names to each scatter plot plt.scatter(non_smoking_total_bill, non_smoking_tip, label='Non-smoking') plt.scatter(smoking_total_bill, smoking_tip, label='Smoking') # Put legend in upper left corner of the plot plt.legend(loc='upper left') plt.show()
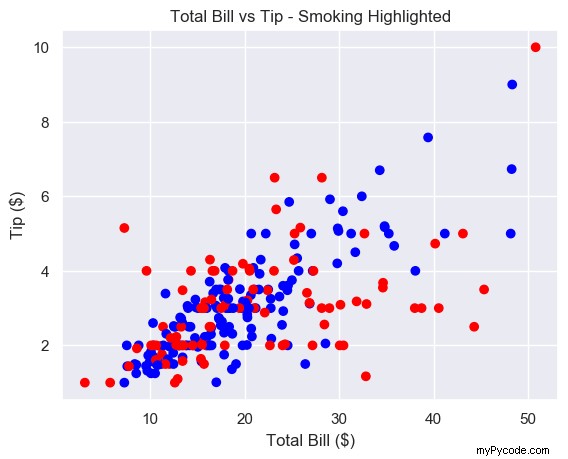
Beaucoup mieux. Il semble que les données sur les fumeurs soient plus étalées et plates que les données sur les non-fumeurs. Cela implique que les fumeurs donnent à peu près le même pourboire, quelle que soit la taille de leur facture. Essayons de servir moins de tables fumeurs et plus de tables non-fumeurs.
Cette méthode fonctionne bien si nous avons des données séparées. Mais la plupart du temps, nous ne le faisons pas et le séparer peut être fastidieux.
Heureusement, comme avec size , nous pouvons passer c un tableau/séquence.
Disons que nous avons une liste smoker qui contient 1 si la table a fumé et 0 si ce n'est pas le cas.
plt.scatter(total_bill, tip, c=smoker) plt.show()
Remarque :si on passe un tableau/séquence, on doit le mot clé c au lieu de color . Python lève un ValueError si vous utilisez ce dernier.
ValueError: 'color' kwarg must be an mpl color spec or sequence of color specs. For a sequence of values to be color-mapped, use the 'c' argument instead.
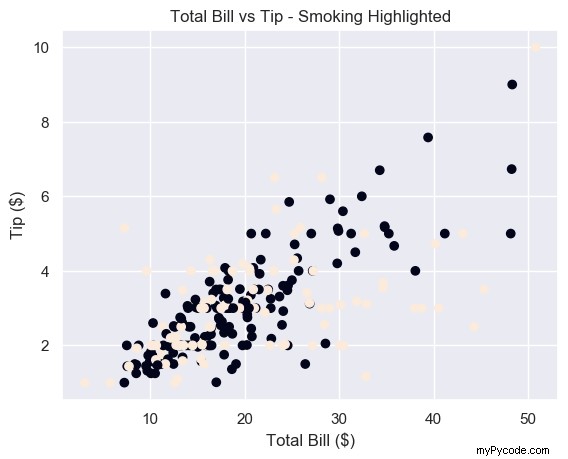
Génial, nous avons maintenant un tracé avec deux couleurs différentes dans 2 lignes de code. Mais les couleurs sont difficiles à voir.
Matplotlib Scatter Colormap
Une palette de couleurs est une gamme de couleurs que matplotlib utilise pour ombrer vos tracés. Nous définissons une palette de couleurs avec le cmap dispute. Toutes les palettes de couleurs possibles sont répertoriées ici.
Nous choisirons 'bwr' qui signifie bleu-blanc-rouge. Pour deux ensembles de données, il choisit uniquement le bleu et le rouge.
Si la théorie des couleurs vous intéresse, nous vous recommandons vivement cet article. Dans celui-ci, l'auteur crée bwr . Ensuite, il soutient que cela devrait être le schéma de couleurs par défaut pour toutes les visualisations scientifiques.
plt.scatter(total_bill, tip, c=smoker, cmap='bwr') plt.show()
Beaucoup mieux. Ajoutons maintenant une légende.
Comme nous avons un plt.scatter() appeler, nous devons utiliser scatter.legend_elements() comme nous l'avons fait plus tôt. Cette fois, nous allons définir prop='colors' . Mais comme il s'agit du paramètre par défaut, nous appelons legend_elements() sans aucun argument.
# legend_elements() is a method so we must name our scatter plot
scatter = plt.scatter(total_bill, tip, c=smoker_num, cmap='bwr')
# No arguments necessary, default is prop='colors'
handles, labels = scatter.legend_elements()
# Print out labels to see which appears first
print(labels)
# ['$\\mathdefault{0}$', '$\\mathdefault{1}$']
Nous décompactons notre légende en handles et labels comme avant. Ensuite, nous imprimons des étiquettes pour voir l'ordre choisi par matplotlib. Il utilise un ordre croissant. Donc 0 (non-fumeurs) est le premier.
Maintenant, nous écrasons labels avec des chaînes descriptives et passez tout à plt.legend() .
# Re-name labels to something easier to understand labels = ['Non-Smokers', 'Smokers'] plt.legend(handles, labels) plt.show()
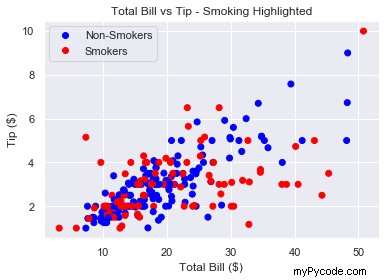
Ceci est un grand nuage de points. Il est facile de distinguer les couleurs et la légende nous dit ce qu'elles signifient. Comme fumer est malsain, c'est aussi bien que cela soit représenté par du rouge comme cela le suggère 'danger' .
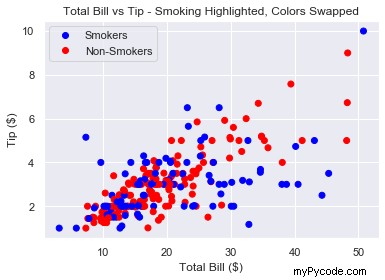
Et si on voulait échanger les couleurs ?
Faites la même chose que ci-dessus mais faites le smoker liste 0 pour les fumeurs et 1 pour les non-fumeurs.
smokers_swapped = [1 - x for x in smokers]
Enfin, comme 0 vient en premier, nous écrasons labels dans l'ordre inverse d'avant.
labels = ['Smokers', 'Non-Smokers']
Types de marqueurs de dispersion Matplotlib
Au lieu d'utiliser la couleur pour représenter les fumeurs et les non-fumeurs, nous pourrions utiliser différents types de marqueurs.
Vous avez le choix entre plus de 30 marqueurs intégrés. De plus, vous pouvez utiliser n'importe quelle expression LaTeX et même définir vos propres formes. Nous couvrirons les types intégrés les plus courants que vous verrez. Heureusement, la syntaxe pour les choisir est intuitive.
Dans notre plt.scatter() appeler, utilisez le marker argument de mot-clé pour définir le type de marqueur. Habituellement, la forme de la chaîne reflète la forme du marqueur. Ou la chaîne est une lettre unique correspondant à la première lettre de la forme.
Voici les exemples les plus courants :
'o'– cercle (par défaut)'v'– triangle vers le bas'^'– triangle vers le haut's'– carré'+'– plus'D'– diamant'd'– diamant fin'$...$'– Syntaxe LaTeX, par ex.'$\pi$'fait de chaque marqueur la lettre grecque π.
Voyons quelques exemples
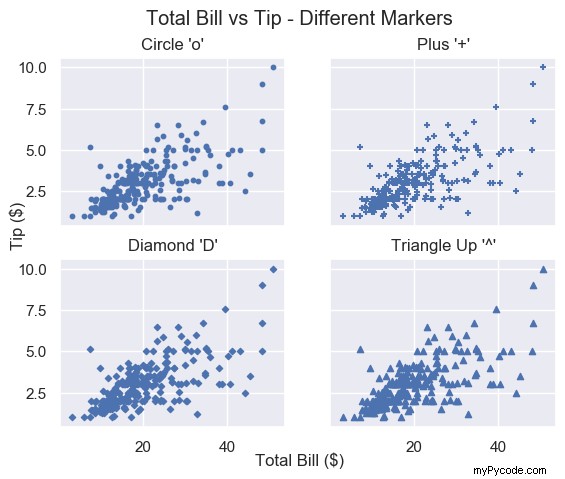
Pour chaque parcelle, appelez plt.scatter() avec total_bill et pourboire et régler marker à votre choix
# Circle plt.scatter(total_bill, tip, marker='o') # Plus plt.scatter(total_bill, tip, marker='+') # Diamond plt.scatter(total_bill, tip, marker='D') # Triangle Up plt.scatter(total_bill, tip, marker='^')
Au moment de la rédaction, vous ne pouvez pas passer un tableau à marker comme vous pouvez avec color ou size . Il existe un problème GitHub ouvert demandant l'ajout de cette fonctionnalité. Mais pour l'instant, pour tracer deux jeux de données avec des marqueurs différents, vous devez le faire manuellement.
# Square marker
plt.scatter(non_smoking_total_bill, non_smoking_tip, marker='s',
label='Non-smoking')
# Plus marker
plt.scatter(smoking_total_bill, smoking_tip, marker='+',
label='Smoking')
plt.legend(loc='upper left')
plt.show() 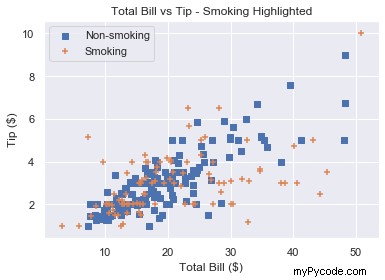
N'oubliez pas que si vous dessinez plusieurs nuages de points à la fois, matplotlib les colore différemment. Cela facilite la reconnaissance des différents ensembles de données. Il y a donc peu de valeur à changer également le type de marqueur.
Pour obtenir un tracé d'une seule couleur avec différents types de marqueurs, définissez la même couleur pour chaque tracé et modifiez chaque marqueur.
# Square marker, blue color
plt.scatter(non_smoking_total_bill, non_smoking_tip, marker='s', c='b'
label='Non-smoking')
# Plus marker, blue color
plt.scatter(smoking_total_bill, smoking_tip, marker='+', c='b'
label='Smoking')
plt.legend(loc='upper left')
plt.show() 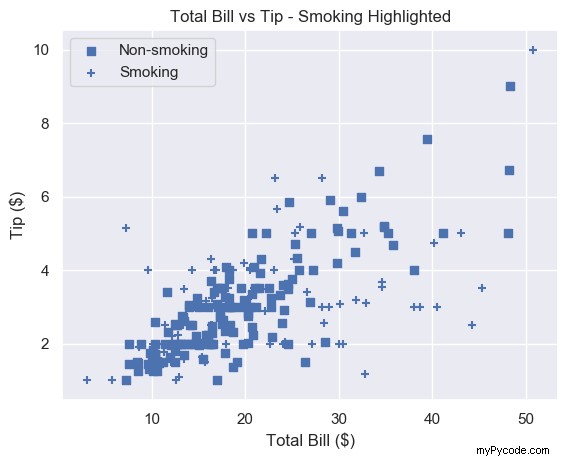
La plupart conviendraient que différentes couleurs sont plus faciles à distinguer que différents marqueurs. Mais maintenant, vous avez la possibilité de choisir.
Résumé
Vous connaissez maintenant les 4 choses les plus importantes pour faire d'excellents nuages de points.
Vous pouvez créer des nuages de points de base matplotlib. Vous pouvez modifier la taille du marqueur pour faciliter la compréhension des données. Et vous pouvez modifier la taille du marqueur en fonction d'une autre variable.
Vous avez appris à choisir n'importe quelle couleur imaginable pour votre intrigue. De plus, vous pouvez modifier la couleur en fonction d'une autre variable.
Pour ajouter de la personnalité à vos tracés, vous pouvez utiliser un type de marqueur personnalisé.
Enfin, vous pouvez faire tout cela avec une légende d'accompagnement (quelque chose que la plupart des Pythonistes ne savent pas utiliser !).
Où aller à partir d'ici
Voulez-vous gagner plus d'argent? Êtes-vous dans un emploi sans issue 9-5? Vous rêvez de vous libérer et de coder à temps plein, mais vous ne savez pas par où commencer ?
Devenir codeur à temps plein fait peur. Il y a tellement d'informations de codage là-bas que c'est écrasant.
La plupart des tutoriels vous enseignent Python et vous disent d'obtenir un emploi à temps plein.
C'est bien, mais pourquoi voudriez-vous un autre travail de bureau ?
Vous n'avez pas soif de liberté ? Vous n'avez pas envie de parcourir le monde ? Vous ne voulez pas passer plus de temps avec vos amis et votre famille ?
Il n'y a pratiquement pas de tutoriels qui vous enseignent Python et comment être votre propre patron. Et il n'y en a aucun qui vous apprend à faire six chiffres par an.
Jusqu'ici.
Nous sommes des pigistes Python à temps plein. Nous travaillons de n'importe où dans le monde. Nous fixons nos propres horaires et tarifs horaires. Nos calendriers sont réservés des mois à l'avance et nous avons un flux constant de nouveaux clients.
Cela semble trop beau pour être vrai, non ?
Pas du tout. Nous voulons vous montrer les étapes exactes que nous avons utilisées pour arriver ici. Nous voulons vous offrir une vie de liberté. Nous voulons que vous soyez un codeur à six chiffres.
Cliquez sur le lien ci-dessous pour regarder notre webinaire sur la valeur pure. Nous vous montrons les étapes exactes pour vous emmener d'où vous êtes à un pigiste Python à temps plein. Ce sont des méthodes éprouvées, sans BS, qui vous permettent d'obtenir des résultats rapidement.
https://tinyurl.com/python-freelancer-webinar
Peu importe que vous soyez un novice Python ou un pro Python. Si vous ne gagnez pas six chiffres par an avec Python en ce moment, vous apprendrez quelque chose de ce webinaire.
Cliquez sur le lien ci-dessous maintenant et découvrez comment devenir un pigiste Python.
https://tinyurl.com/python-freelancer-webinar
Références
- https://stackoverflow.com/questions/14827650/pyplot-scatter-plot-marker-size
- https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.scatter.html
- https://seaborn.pydata.org/generated/seaborn.scatterplot.html
- https://matplotlib.org/3.1.1/api/collections_api.html#matplotlib.collections.PathCollection.legend_elements
- https://blog.finxter.com/what-is-asterisk-in-python/
- https://matplotlib.org/3.1.1/api/markers_api.html#module-matplotlib.markers
- https://stackoverflow.com/questions/31726643/how-do-i-get-multiple-subplots-in-matplotlib
- https://matplotlib.org/3.1.0/gallery/color/named_colors.html
- https://matplotlib.org/3.1.0/tutorials/colors/colors.html#xkcd-colors
- https://github.com/matplotlib/matplotlib/issues/11155
- https://matplotlib.org/3.1.1/tutorials/colors/colormaps.html
- https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.legend.html
- https://matplotlib.org/tutorials/intermediate/legend_guide.html
- https://seaborn.pydata.org/tutorial/color_palettes.html
- https://cfwebprod.sandia.gov/cfdocs/CompResearch/docs/ColorMapsExpanded.pdf
- https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.subplots.html