Pouvez-vous repérer les valeurs aberrantes dans l'ordre suivant :000000001000000001 ? La détection rapide des valeurs aberrantes peut être essentielle pour de nombreuses applications dans les domaines militaire, du transport aérien et de la production d'énergie.
Cet article vous présente l'algorithme de détection des valeurs aberrantes le plus élémentaire :si une valeur observée s'écarte de la moyenne de plus que l'écart type, elle est considérée comme une valeur aberrante. Vous pouvez également regarder la vidéo explicative ici :
Qu'est-ce qu'une valeur aberrante ?
Tout d'abord, étudions ce qu'est exactement une valeur aberrante. Dans cet article, nous faisons l'hypothèse de base que toutes les données observées sont normalement distribuées autour d'une valeur moyenne. Par exemple, considérez la séquence suivante :
[ 8.78087409 10.95890859 8.90183201 8.42516116 9.26643393 12.52747974 9.70413087 10.09101284 9.90002825 10.15149208 9.42468412 11.36732294 9.5603904 9.80945055 10.15792838 10.13521324 11.0435137 10.06329581 ... 10.74304416 10.47904781]
Si vous tracez cette séquence, vous obtiendrez la figure suivante :
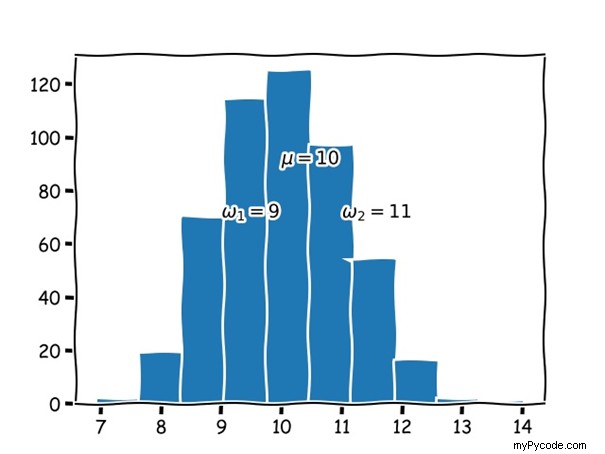
Voici le code utilisé pour générer ce tracé :
import numpy as np
import matplotlib.pyplot as plt
sequence = np.random.normal(10.0, 1.0, 500)
print(sequence)
plt.xkcd()
plt.hist(sequence)
plt.annotate(r"$\omega_1=9$", (9, 70))
plt.annotate(r"$\omega_2=11$", (11, 70))
plt.annotate(r"$\mu=10$", (10, 90))
plt.savefig("plot.jpg")
plt.show()
La séquence ressemble à une distribution normale avec une valeur moyenne de 10 et un écart type de 1.
La moyenne est la valeur moyenne de toutes les valeurs de séquence.
L'écart type est l'écart par rapport à la moyenne, de sorte qu'environ 68 % de toutes les valeurs d'échantillon se situent dans l'intervalle d'écart type.
Dans ce qui suit, nous supposons simplement que toute valeur observée qui est en dehors de l'intervalle marqué par l'écart type autour de la moyenne est une aberration .
Méthode 1 :Détecter les valeurs aberrantes dans l'analyse de site Web (One-Liner)
Imaginez que vous êtes l'administrateur d'une application en ligne et que vous devez analyser en permanence le trafic du site Web. En tant qu'administrateur de l'application Web Python Finxter.com, c'est l'une de mes activités quotidiennes.
Ce one-liner examine le problème suivant :"Trouver tous les jours aberrants dont les statistiques (colonnes) s'écartent de plus que l'écart type de leurs statistiques moyennes"
## Dependencies
import numpy as np
## Website analytics data:
## (row = day), (col = users, bounce, duration)
a = np.array([[815, 70, 115],
[767, 80, 50],
[912, 74, 77],
[554, 88, 70],
[1008, 65, 128]])
mean, stdev = np.mean(a, axis=0), np.std(a, axis=0)
# Mean: [811.2 76.4 88. ]
# Std: [152.97764543 6.85857128 29.04479299]
## Find Outliers
outliers = ((np.abs(a[:,0] - mean[0]) > stdev[0])
* (np.abs(a[:,1] - mean[1]) > stdev[1])
* (np.abs(a[:,2] - mean[2]) > stdev[2]))
## Result
print(a[outliers]) L'ensemble de données se compose de plusieurs lignes et colonnes. Chaque ligne comprend des statistiques quotidiennes composées de trois colonnes (utilisateurs actifs quotidiens, taux de rebond et durée moyenne de session en secondes).
Pour chaque colonne (métrique suivie statistiquement), nous calculons la valeur moyenne et l'écart type. Par exemple, la valeur moyenne de la colonne "utilisateurs actifs quotidiens" est de 811,2 et son écart type est de 152,97. Notez que nous utilisons l'argument d'axe pour calculer la moyenne et l'écart type de chaque colonne séparément.
Rappelons que notre objectif est de détecter les valeurs aberrantes. Mais comment faire cela pour notre analyse de site Web ? Le code suppose simplement que chaque valeur observée qui ne tombe pas dans l'écart type autour de la moyenne de chaque colonne spécifique est une valeur aberrante. C'est aussi simple que ça.
Par exemple, la valeur moyenne de la colonne "utilisateurs actifs quotidiennement" est de 811,2 et son écart type est de 152,97. Ainsi, toute valeur observée pour la métrique "utilisateurs actifs quotidiens" qui est inférieure à 811,2-152,97=658,23 ou supérieure à 811,2+152,23=963,43 est considérée comme une valeur aberrante pour cette colonne.
Cependant, nous considérons qu'un jour est une valeur aberrante uniquement si les trois colonnes observées sont des valeurs aberrantes. Il est facile d'y parvenir en combinant les trois tableaux booléens à l'aide de l'opération "logique et" de NumPy. Le et logique peut être remplacé par un schéma de multiplication simple car Vrai est représenté par un entier 1 et Faux par un entier 0.
Nous utilisons np.abs() dans l'extrait de code qui convertit simplement les valeurs négatives d'un tableau NumPy en leurs homologues positifs.
Cet article est basé sur mon livre. Je vais vous montrer la prochaine méthode pour détecter les valeurs aberrantes dans un instant.
Mais avant de continuer, je suis ravi de vous présenter mon nouveau livre Python Python One-Liners (Lien Amazon).
Si vous aimez les one-liners, vous allez adorer le livre. Il vous apprendra tout ce qu'il y a à savoir sur une seule ligne de code Python. Mais c'est aussi une introduction à l'informatique , science des données, apprentissage automatique et algorithmes. L'univers en une seule ligne de Python !

Le livre est sorti en 2020 avec l'éditeur de livres de programmation de classe mondiale NoStarch Press (San Francisco).
Lien :https://nostarch.com/pythononeliners
Méthode 2 :IQR
Cette méthode de cette base de code GitHub utilise la plage interquartile pour supprimer les valeurs aberrantes des données x. Cette excellente vidéo de Khan Academy explique l'idée rapidement et efficacement :
L'extrait de code suivant supprime les valeurs aberrantes à l'aide de NumPy :
import numpy as np
def removeOutliers(x, outlierConstant):
a = np.array(x)
upper_quartile = np.percentile(a, 75)
lower_quartile = np.percentile(a, 25)
IQR = (upper_quartile - lower_quartile) * outlierConstant
quartileSet = (lower_quartile - IQR, upper_quartile + IQR)
resultList = []
for y in a.tolist():
if y >= quartileSet[0] and y <= quartileSet[1]:
resultList.append(y)
return resultList Méthode 3 :Supprimer les valeurs aberrantes du tableau NumPy à l'aide de np.mean() et np.std()
Cette méthode est basée sur l'extrait de code utile fourni ici.
Pour supprimer une valeur aberrante d'un tableau NumPy, suivez ces cinq étapes de base :
- Créer un tableau avec des valeurs aberrantes
- Déterminer la moyenne et l'écart type
- Normaliser le tableau autour de 0
- Définir le nombre maximal d'écarts types
- Accéder uniquement aux valeurs non aberrantes à l'aide de l'indexation booléenne
import numpy as np # 1. Create an array with outliers a = np.array([1, 1, 1, 1, 1, 1, 42, 1, 1]) # 2. Determine mean and standard deviation mean = np.mean(a) std_dev = np.std(a) # 3. Normalize array around 0 zero_based = abs(a - mean) # 4. Define maximum number of standard deviations max_deviations = 2 # 5. Access only non-outliers using Boolean Indexing no_outliers = a[zero_based < max_deviations * std_dev] print(no_outliers) # [1 1 1 1 1 1 1 1]