Comment la bibliothèque pandas de Python peut-elle être utilisée pour analyser des données de séries chronologiques ? Découvrons.
La bibliothèque pandas est fréquemment utilisée pour importer, gérer et analyser des ensembles de données dans une variété de formats. Dans cet article, nous l'utiliserons pour analyser les cours des actions de Microsoft pour les années précédentes. Nous verrons également comment effectuer des tâches de base, telles que le rééchantillonnage temporel et décalage horaire , avec des pandas.
Qu'est-ce que les données de séries chronologiques ?
Les données de séries chronologiques contiennent des valeurs dépendant d'une sorte d'unité de temps. Voici tous des exemples de données de séries chronologiques :
- Le nombre d'articles vendus par heure pendant une période de 24 heures
- Le nombre de passagers qui voyagent au cours d'une période d'un mois
- Le prix du stock par jour
Dans tous ces cas, les données dépendent des unités de temps ; dans un graphique, le temps est présenté sur l'axe des x et les valeurs de données correspondantes sont présentées sur l'axe des y.
Obtenir les données
Nous utiliserons un ensemble de données contenant les cours des actions de Microsoft de 2013 à 2018. L'ensemble de données peut être téléchargé gratuitement sur Yahoo Finance. Vous devrez peut-être saisir la durée de téléchargement des données, qui arriveront au format CSV.
Importer les bibliothèques requises
Avant de pouvoir importer le jeu de données dans votre application, vous devez importer les bibliothèques requises. Exécutez le script suivant pour ce faire.
import numpy as np import pandas as pd %matplotlib inline import matplotlib.pyplot as plt
Ce script importe les bibliothèques NumPy, pandas et matplotlib. Ce sont les bibliothèques nécessaires pour exécuter les scripts de cet article.
Remarque : Tous les scripts de l'ensemble de données ont été exécutés à l'aide du bloc-notes Jupyter pour Python.
Importer et analyser l'ensemble de données
Pour importer le jeu de données, nous utiliserons le read_csv() méthode de la bibliothèque pandas. Exécutez le script suivant :
stock_data = pd.read_csv('E:/Datasets/MSFT.csv')
Pour voir à quoi ressemble le jeu de données, vous pouvez utiliser le head() méthode. Cette méthode renvoie les cinq premières lignes de l'ensemble de données.
stock_data.head()
La sortie ressemble à ceci :

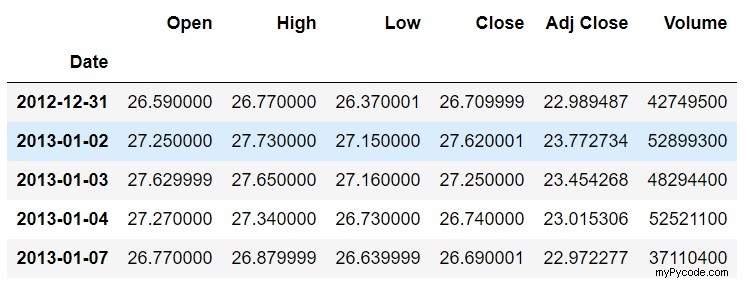
Vous pouvez voir que l'ensemble de données contient la date et les cours d'ouverture, haut, bas, de clôture et de clôture ajustés pour l'action Microsoft. Pour le moment, le Date colonne est traitée comme une simple chaîne. Nous voulons les valeurs dans le Date colonne à traiter comme des dates. Pour ce faire, nous devons convertir le Date colonne à datetime taper. Le script suivant fait cela :
stock_data['Date'] = stock_data['Date'].apply(pd.to_datetime)
Enfin, nous avons besoin que la colonne Date soit utilisée comme colonne d'index, puisque toutes les autres colonnes dépendent des valeurs de cette colonne. Pour cela, exécutez le script suivant :
stock_data.set_index('Date',inplace=True)
Si vous utilisez head() à nouveau, vous verrez que les valeurs dans le Date colonne sont en gras, comme illustré dans l'image suivante. C'est parce que le Date la colonne est maintenant traitée comme la colonne d'index :
Maintenant, traçons les valeurs de la colonne Ouvrir par rapport à la date. Pour cela, exécutez le script suivant :
plt.rcParams['figure.figsize'] = (10, 8) # Increases the Plot Size stock_data['Open'].plot(grid = True)
La sortie montre les cours d'ouverture des actions de janvier 2013 à fin 2017 :

Ensuite, nous utiliserons la bibliothèque pandas pour le rééchantillonnage temporel. Si vous avez besoin d'actualiser vos compétences pandas, matplotlib ou NumPy avant de continuer, consultez le cours Introduction à Python pour la science des données de LearnPython.com.
Rééchantillonnage temporel
Le rééchantillonnage temporel fait référence à l'agrégation de données de séries chronologiques par rapport à une période de temps spécifique. Par défaut, vous disposez d'informations sur le cours de l'action pour chaque jour. Que faire si vous souhaitez obtenir les informations sur le cours moyen des actions pour chaque année ? Vous pouvez utiliser le rééchantillonnage temporel pour ce faire.
La bibliothèque pandas est livrée avec le resample() fonction, qui peut être utilisée pour le rééchantillonnage temporel. Tout ce que vous avez à faire est de définir un décalage pour la règle attribut avec la fonction d'agrégation (par exemple, maximum, minimum, moyenne, etc.).
Voici quelques-uns des décalages qui peuvent être utilisés comme valeurs pour la règle attribut du resample() fonction :
W weekly frequency M month end frequency Q quarter end frequency A year end frequency
La liste complète des valeurs de décalage se trouve dans la documentation pandas.
Vous disposez maintenant de toutes les informations dont vous avez besoin pour le rééchantillonnage temporel. Mettons-le en œuvre. Supposons que vous souhaitiez trouver les cours moyens des actions pour toutes les années. Pour cela, exécutez le script suivant :
stock_data.resample(rule='A').mean()
La valeur de décalage 'A' indique que vous souhaitez rééchantillonner par rapport à l'année. Le moyen() La fonction spécifie que vous souhaitez trouver les valeurs moyennes des stocks.
La sortie ressemble à ceci :

Vous pouvez voir que la valeur du Date colonne est le dernier jour de cette année. Toutes les autres valeurs sont les valeurs moyennes pour toute l'année.
De même, vous pouvez trouver les cours boursiers hebdomadaires moyens à l'aide du script suivant. (Remarque :le décalage pour la semaine est 'W'.)
stock_data.resample(rule='W').mean()
Sortie :

Utilisation du rééchantillonnage temporel pour tracer des graphiques
Vous pouvez également tracer des graphiques pour une colonne spécifique à l'aide du rééchantillonnage temporel. Regardez le script suivant :
plt.rcParams['figure.figsize'] = (8, 6) # change plot size
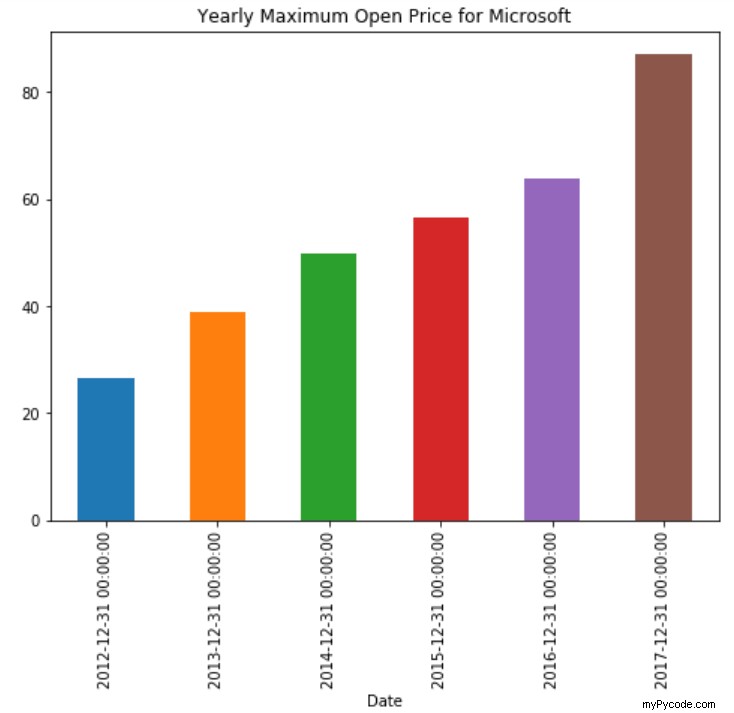
stock_data['Open'].resample('A').max().plot(kind='bar')
plt.title('Yearly Maximum Open Price for Microsoft')
Le script ci-dessus trace un graphique à barres indiquant le prix maximum annuel de l'action. Vous pouvez voir qu'au lieu de l'ensemble de données complet, la méthode de rééchantillonnage n'est appliquée qu'à la colonne Ouvrir. Le max() et plot() les fonctions sont enchaînées pour 1) trouver d'abord le prix d'ouverture maximum pour chaque année, et 2) tracer le graphique à barres. La sortie ressemble à ceci :
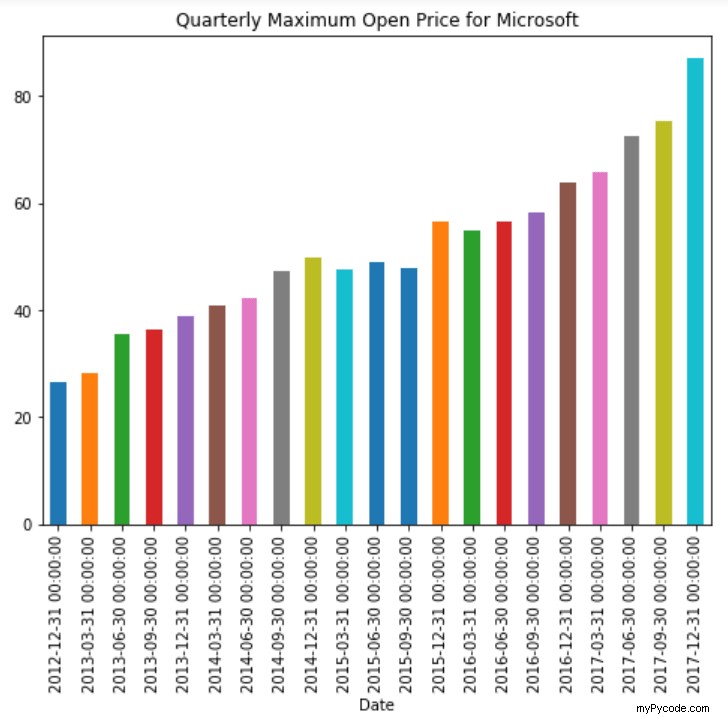
De même, pour tracer le cours d'ouverture maximal trimestriel, nous définissons simplement la valeur de décalage sur "Q" :
plt.rcParams['figure.figsize'] = (8, 6) # change plot size
stock_data['Open'].resample('Q').max().plot(kind='bar')
plt.title('Quarterly Maximum Open Price for Microsoft')
Vous pouvez maintenant voir le cours d'ouverture maximal trimestriel pour Microsoft :
Décalage horaire
Le décalage temporel fait référence au déplacement des données vers l'avant ou vers l'arrière le long de l'index temporel. Voyons ce que nous entendons par décaler les données vers l'avant ou vers l'arrière.
Tout d'abord, nous verrons à quoi ressemblent les cinq premières lignes et les cinq dernières lignes de notre ensemble de données en utilisant le head() et queue() les fonctions. La tête() affiche les cinq premières lignes de l'ensemble de données, tandis que la fonction tail() la fonction affiche les cinq dernières lignes.
Exécutez les scripts suivants :
stock_data.head()
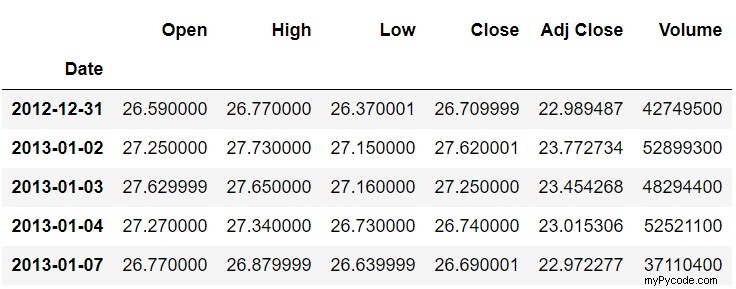
stock_data.tail()
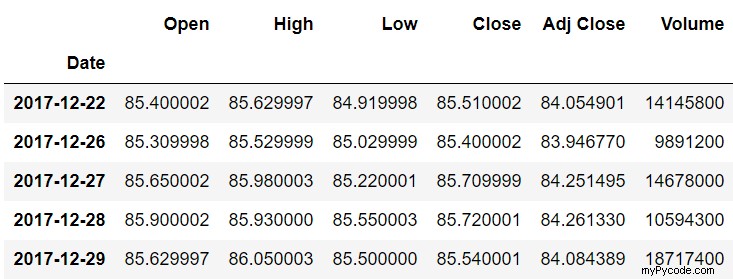
Nous avons imprimé les enregistrements à partir de la tête et de la queue de l'ensemble de données, car lorsque nous décalerons les données plus tard, nous verrons les différences entre les données réelles et décalées.
Déplacer vers l'avant
Faisons maintenant le déplacement proprement dit. Pour décaler les données vers l'avant, il suffit de passer le nombre d'index à déplacer vers le décalage () méthode, comme indiqué ci-dessous :
stock_data.shift(1).head()
Le script ci-dessus déplace nos données d'un index vers l'avant, ce qui signifie que les valeurs de Open , Close , Adjusted Close , et Volume colonnes qui appartenaient auparavant à l'enregistrement N appartiennent désormais à l'enregistrement N+1 . La sortie ressemble à ceci :
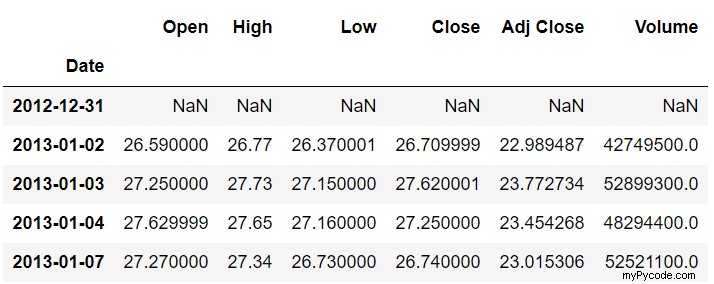
Vous pouvez voir à partir de la sortie que le premier index (2012-12-31) n'a plus de données. Le deuxième index contient les enregistrements qui appartenaient auparavant au premier index (2013-01-02).
De même, à la fin, vous verrez que le dernier index (2017-12-29) contient désormais les enregistrements qui appartenaient auparavant à l'avant-dernier index (2017-12-28). Ceci est illustré ci-dessous :

Auparavant, la valeur de la colonne Open 85,900002 appartenait à l'index 2017-12-28, mais après avoir avancé d'un index, elle appartient désormais à 2017-12-29.
Reculer
Pour décaler les données vers l'arrière, transmettez le nombre d'index avec un signe moins. Le décalage d'un index vers l'arrière signifie que les valeurs de Open , Close , Adjusted Close , et Volume colonnes qui appartenaient auparavant à l'enregistrement N appartiennent maintenant à l'enregistrement N-1 .
Pour reculer d'un pas, exécutez le script suivant :
stock_data.shift(-1).head()
La sortie ressemble à ceci :

Nous pouvons voir qu'après avoir reculé d'un indice, la valeur d'ouverture de 27,250000 appartient à l'indice 2012-12-31. Auparavant, il appartenait à l'index 2013-01-02.
Décalage des données à l'aide d'un décalage horaire
Dans la section de rééchantillonnage temporel, nous avons utilisé un décalage de la table de décalage pandas pour spécifier la période de rééchantillonnage. Nous pouvons également utiliser la même table de décalage pour le décalage temporel. Pour ce faire, nous devons transmettre des valeurs pour les périodes et fréq paramètres du tshift() fonction. La période l'attribut spécifie le nombre de pas, tandis que la freq L'attribut spécifie la taille de l'étape. Par exemple, si vous souhaitez décaler vos données de deux semaines, vous pouvez utiliser le tshift() fonctionnent comme suit :
stock_data.tshift(periods=2,freq='W').head()
Dans le résultat, vous verrez des données avancées de deux semaines :

En savoir plus sur les données de séries temporelles en Python
L'analyse de séries chronologiques est l'une des principales tâches que vous devrez accomplir en tant qu'expert financier, avec l'analyse de portefeuille et la vente à découvert. Dans cet article, vous avez vu comment la bibliothèque pandas de Python peut être utilisée pour visualiser des données de séries chronologiques. Vous avez appris à effectuer un échantillonnage temporel et un décalage temporel. Cependant, cet article effleure à peine la surface de l'utilisation des pandas et de Python pour l'analyse des séries chronologiques. Python offre des capacités d'analyse de séries chronologiques plus avancées, telles que la prévision des cours futurs des actions et l'exécution d'opérations de roulement et d'expansion sur des données de séries chronologiques.
Si vous souhaitez en savoir plus sur Python pour l'analyse de séries chronologiques et d'autres tâches financières, je vous recommande vivement de vous inscrire à notre cours d'introduction à Python pour la science des données afin d'acquérir plus d'expérience pratique.

