
Une trame de données dans Pandas est un tableau à deux dimensions qui comporte des lignes et des colonnes. La trame de données est le composant principal de la populaire bibliothèque Pandas Python. Pandas est une bibliothèque Python open source qui fournit des structures de données et des outils d'analyse hautes performances et faciles à utiliser. Pandas s'exécute sur Python NumPy, et nous verrons comment démarrer avec les dataframes dans Pandas pour ce tutoriel.
Pandas contre Numpy
Avant d'examiner les dataframes dans Pandas, comparons rapidement NumPy et Pandas.
| NumPy | Pandas |
|
|
Liste vers Dataframe
Nous savons ce qu'est une liste python et comment l'utiliser. Voici une liste simple.
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
print(simple_list)['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
Nous pouvons charger cette liste dans un Pandas Dataframe comme ça.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
data = pd.DataFrame(simple_list)
print(data)Nous pouvons voir que les données résultantes semblent maintenant un peu différentes. Vous pouvez voir que la liste est maintenant organisée en lignes et en colonnes.
0 0 Sam 1 Bob 2 Joe 3 Mary 4 Sue 5 Sally
Nommer la colonne
Le chiffre 0 n'est pas très descriptif pour le nom de la colonne, alors changeons cela en utilisant ce code.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list}
data = pd.DataFrame(named_column)
print(data)La chaîne dans la clé du dictionnaire ci-dessus devient le nom de la colonne, dans ce cas "Nom".
Name 0 Sam 1 Bob 2 Joe 3 Mary 4 Sue 5 Sally
Ajouter une colonne
Pour ajouter une colonne à une base de données Pandas, nous pouvons faire quelque chose comme ça.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green']}
data = pd.DataFrame(named_column)
print(data)Juste comme ça, nous avons maintenant une nouvelle colonne "Couleur préférée".
Name Favorite Color 0 Sam Blue 1 Bob Red 2 Joe Green 3 Mary Blue 4 Sue Red 5 Sally Green
Ajoutons une autre colonne comme ceci.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
print(data)Name Favorite Color Favorite Food 0 Sam Blue Italian 1 Bob Red Mediterranean 2 Joe Green Thai 3 Mary Blue Chinese 4 Sue Red Mexican 5 Sally Green Spanish
Ok, ce Dataframe a l'air plutôt bien. Nous avons des lignes et des colonnes, et des informations utiles stockées dans ces lignes et colonnes. Le format de ces données commence-t-il à vous sembler familier ? Oui, c'est vrai, cela ressemble à une sorte de feuille de calcul Excel ! C'est un bon concept à comprendre. Un DataFrame dans les pandas est analogue à une feuille de calcul Excel. Alors qu'un classeur Excel peut contenir plusieurs feuilles de calcul, les pandas DataFrames existent indépendamment.
Sélectionner des données de colonne
Une fois que vous avez une base de données pandas avec laquelle travailler, vous pouvez commencer à en sélectionner les données à votre guise. Le code suivant sélectionnera toutes les valeurs de la colonne "Couleur préférée".
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
selected_column = data['Favorite Color']
print(selected_column)0 Blue 1 Red 2 Green 3 Blue 4 Red 5 Green Name: Favorite Color, dtype: object
Sélectionner une valeur dans une Dataframe
Maintenant, nous voulons obtenir la couleur préférée d'une seule personne. Imaginez que nous voulions la couleur préférée de Joe. Comment fait-on cela? Eh bien, nous pouvons voir que Joe est dans la ligne d'index de 2, nous pouvons donc fournir cet index lors de la sélection d'une valeur. De cette façon, nous spécifions que nous voulons la valeur où la colonne "Couleur préférée" et la ligne de la valeur d'index 2 se croisent.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
selected_column = data['Favorite Color'][2]
print(selected_column)Green
Sélectionner des lignes avec iloc
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
selected_column = data['Favorite Color'][2]
selected_row = data.iloc[2]
print(selected_row)Cela nous fournit toutes les données trouvées dans cette ligne. Nous avons le nom, la couleur préférée et la nourriture préférée de Joe.
Name Joe Favorite Color Green Favorite Food Thai Name: 2, dtype: object
Pour obtenir les informations de Sue, nous pourrions le faire facilement en modifiant simplement la valeur d'index transmise à iloc.
selected_row = data.iloc[4]Name Sue Favorite Color Red Favorite Food Mexican Name: 4, dtype: object
Sélectionner une valeur de ligne
Tout comme nous pourrions fournir un index pour sélectionner une valeur spécifique lors de la sélection d'une colonne, nous pouvons faire de même lors de la sélection de lignes. Prenons juste la nourriture préférée de Sue.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
selected_column = data['Favorite Color'][2]
selected_row = data.iloc[4]['Favorite Food']
print(selected_row)Mexican
Manipuler des données de trame de données
Tout comme dans une feuille de calcul, vous pouvez appliquer des formules aux données pour créer de nouvelles colonnes de données basées sur des données existantes. Créons une formule qui ajoute une nouvelle colonne "À propos de moi" au dataframe.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
data = pd.DataFrame(named_column)
formula_result = []
for i in range(len(data)):
formula_result.append(f'{data.iloc[i]["Name"]} likes {data.iloc[i]["Favorite Food"]}'
f' food and the color {data.iloc[i]["Favorite Color"]}')
data['About Me'] = formula_result
print(data)Name ... About Me 0 Sam ... Sam likes Italian food and the color Blue 1 Bob ... Bob likes Mediterranean food and the color Red 2 Joe ... Joe likes Thai food and the color Green 3 Mary ... Mary likes Chinese food and the color Blue 4 Sue ... Sue likes Mexican food and the color Red 5 Sally ... Sally likes Spanish food and the color Green [6 rows x 4 columns]
Ça a l'air plutôt bien ! Avez-vous remarqué que la trame de données est un peu différente maintenant ? Vous voyez ces trois points… dans les rangées de données ? Cela se produit parce que Pandas tronquera la sortie s'il y a beaucoup de données à afficher. Vous pouvez remplacer ce comportement en utilisant pd.set_option(‘display.max_columns’, None) comme ça.
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
pd.set_option('display.max_columns', None)
data = pd.DataFrame(named_column)
formula_result = []
for i in range(len(data)):
formula_result.append(f'{data.iloc[i]["Name"]} likes {data.iloc[i]["Favorite Food"]}'
f' food and the color {data.iloc[i]["Favorite Color"]}')
data['About Me'] = formula_result
print(data) Name Favorite Color Favorite Food \
0 Sam Blue Italian
1 Bob Red Mediterranean
2 Joe Green Thai
3 Mary Blue Chinese
4 Sue Red Mexican
5 Sally Green Spanish
About Me
0 Sam likes Italian food and the color Blue
1 Bob likes Mediterranean food and the color Red
2 Joe likes Thai food and the color Green
3 Mary likes Chinese food and the color Blue
4 Sue likes Mexican food and the color Red
5 Sally likes Spanish food and the color Green Hmm, c'est un peu ce que nous voulons, mais notez qu'il imprime certaines des valeurs, puis crée un saut de ligne et imprime le reste de nos nouvelles valeurs. Que faire si vous souhaitez imprimer l'intégralité de la trame de données sans colonnes tronquées ni sauts de ligne dans la sortie. Je vous donne :
pd.set_option(‘display.max_columns’, Aucun)
pd.set_option(‘display.expand_frame_repr’, False)
import pandas as pd
simple_list = ['Sam', 'Bob', 'Joe', 'Mary', 'Sue', 'Sally']
named_column = {'Name': simple_list,
'Favorite Color': ['Blue', 'Red', 'Green', 'Blue', 'Red', 'Green'],
'Favorite Food': ['Italian', 'Mediterranean', 'Thai', 'Chinese', 'Mexican', 'Spanish']}
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
data = pd.DataFrame(named_column)
formula_result = []
for i in range(len(data)):
formula_result.append(f'{data.iloc[i]["Name"]} likes {data.iloc[i]["Favorite Food"]}'
f' food and the color {data.iloc[i]["Favorite Color"]}')
data['About Me'] = formula_result
print(data)Cela nous donne toute la sortie que nous recherchons !
Name Favorite Color Favorite Food About Me 0 Sam Blue Italian Sam likes Italian food and the color Blue 1 Bob Red Mediterranean Bob likes Mediterranean food and the color Red 2 Joe Green Thai Joe likes Thai food and the color Green 3 Mary Blue Chinese Mary likes Chinese food and the color Blue 4 Sue Red Mexican Sue likes Mexican food and the color Red 5 Sally Green Spanish Sally likes Spanish food and the color Green
Enregistrer une trame de données dans un fichier
Si vous souhaitez stocker le contenu de votre dataframe dans un fichier maintenant, c'est facile à faire avec le .to_csv() méthode.
data.to_csv('dataframe_to_file.csv')Un nouveau fichier est apparu dans notre projet !
Notre application Microsoft préférée, Excel, est également capable d'ouvrir le fichier nouvellement créé.
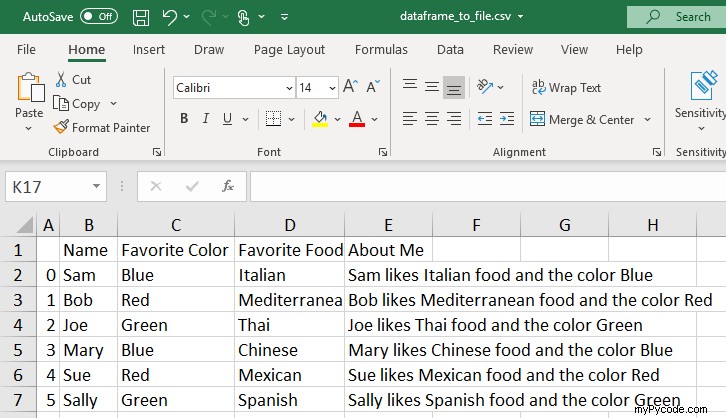
Lors de l'enregistrement d'une trame de données dans un fichier à l'aide de .to_csv(), le délimiteur par défaut est bien sûr une virgule. Cela peut être changé si vous aimez utiliser le sep= paramètre. Créons maintenant une version délimitée par des tabulations de notre fichier.
data.to_csv('dataframe_to_file_tabs.csv', sep='\t')

Enregistrement de la trame de données pandas dans un fichier texte
Même si la méthode que nous utilisons pour écrire une trame de données dans un fichier est nommée .to_csv(), vous n'êtes pas limité aux seuls fichiers .csv. Dans ce prochain extrait, nous enregistrerons la trame de données dans un fichier texte avec une extension .txt à l'aide d'un séparateur personnalisé. Notez que le "délimiteur" doit être une chaîne d'un caractère. Ici, nous allons utiliser le caractère "+", puis afficher les résultats avec le délimiteur en surbrillance afin que nous puissions le voir clairement.
data.to_csv('dataframe_to_text_file.txt', sep='+')

Charger la trame de données à partir du fichier
Pour charger un fichier dans un dataframe, vous pouvez utiliser la fonction .read_csv() comme nous le voyons ci-dessous.
import pandas as pd
data = pd.read_csv('dataframe_to_file.csv')
print(data)Unnamed: 0 ... About Me 0 0 ... Sam likes Italian food and the color Blue 1 1 ... Bob likes Mediterranean food and the color Red 2 2 ... Joe likes Thai food and the color Green 3 3 ... Mary likes Chinese food and the color Blue 4 4 ... Sue likes Mexican food and the color Red 5 5 ... Sally likes Spanish food and the color Green [6 rows x 5 columns]
Pour voir les données non tronquées lors de la lecture d'un fichier dans une trame de données, nous pouvons utiliser les options pratiques pd.set_option('display.max_columns', None) et pd.set_option('display.expand_frame_repr', False).
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
data = pd.read_csv('dataframe_to_file.csv')
print(data)Unnamed: 0 Name Favorite Color Favorite Food About Me 0 0 Sam Blue Italian Sam likes Italian food and the color Blue 1 1 Bob Red Mediterranean Bob likes Mediterranean food and the color Red 2 2 Joe Green Thai Joe likes Thai food and the color Green 3 3 Mary Blue Chinese Mary likes Chinese food and the color Blue 4 4 Sue Red Mexican Sue likes Mexican food and the color Red 5 5 Sally Green Spanish Sally likes Spanish food and the color Green
Comment utiliser sqlite avec pandas
Il est possible de lire des données dans des pandas à partir d'une base de données SQLite. Nous pouvons emprunter un exemple de base de données à partir d'une application différente à utiliser à cette fin. Pour utiliser cette technique, nous pouvons importer sqlite3, configurer une variable de connexion, puis utiliser la fonction pd.read_sql() comme ceci.
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
print(data)id ... calls 0 416 ... AMC,MRNA,TSLA,BYND,SNAP,CHPT,NCTY,GOOGL,VXRT,N... 1 418 ... AMC,SNAP,FSR,PFE,AMD,MRNA,ZEV,AMZN,BAC,SBUX,NV... 2 419 ... FUBO,AMC,COIN,AMD,BA,AMZN,CAT,SPCE,CHPT,RBLX,N... 3 424 ... MRNA,IP,AMC,AMZN,MU,SONO,HYRE,ROKU,AMD,HOOD,PC... 4 425 ... WISH,AMZN,AMD,SPCE,BABA,LAZR,EBAY,AMC,ZNGA,MRN... .. ... ... ... 117 738 ... INTC,TSLA,LCID,NIO,AMZN,BA,AMD,UAA,CLX,HOOD,SK... 118 740 ... AMZN,TSLA,BA,HOOD,NIO,AMD,TWTR,AFRM,AMC,BHC,FL... 119 743 ... AMD,AFRM,PLUG,NVDA,HOOD,TTWO,BA,UPS,TLRY,XOM,F... 120 746 ... UPST,XOM,AMD,Z,FCX,GO,NFLX,RBLX,DWAC,AMRN,FDX,... 121 748 ... PYPL,AMD,FB,GOOGL,RBLX,SQ,WFC,PENN,QCOM,AMGN,T... [122 rows x 4 columns]
Utiliser head() et tail()
Vous voudrez peut-être consulter le premier ou le dernier ensemble d'enregistrements dans la trame de données. Cela peut être accompli en utilisant les fonctions head() ou tail(). Par défaut, head() affichera les 5 premiers résultats et tail() affichera les 5 derniers résultats. Un entier peut être passé à l'une ou l'autre des fonctions si vous voulez voir, par exemple, les 7 premiers enregistrements ou les 10 derniers enregistrements. Voici quelques exemples de head() et tail().
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
print(data.head())id ... calls 0 416 ... AMC,MRNA,TSLA,BYND,SNAP,CHPT,NCTY,GOOGL,VXRT,N... 1 418 ... AMC,SNAP,FSR,PFE,AMD,MRNA,ZEV,AMZN,BAC,SBUX,NV... 2 419 ... FUBO,AMC,COIN,AMD,BA,AMZN,CAT,SPCE,CHPT,RBLX,N... 3 424 ... MRNA,IP,AMC,AMZN,MU,SONO,HYRE,ROKU,AMD,HOOD,PC... 4 425 ... WISH,AMZN,AMD,SPCE,BABA,LAZR,EBAY,AMC,ZNGA,MRN... [5 rows x 4 columns]
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
print(data.head(7))id ... calls 0 416 ... AMC,MRNA,TSLA,BYND,SNAP,CHPT,NCTY,GOOGL,VXRT,N... 1 418 ... AMC,SNAP,FSR,PFE,AMD,MRNA,ZEV,AMZN,BAC,SBUX,NV... 2 419 ... FUBO,AMC,COIN,AMD,BA,AMZN,CAT,SPCE,CHPT,RBLX,N... 3 424 ... MRNA,IP,AMC,AMZN,MU,SONO,HYRE,ROKU,AMD,HOOD,PC... 4 425 ... WISH,AMZN,AMD,SPCE,BABA,LAZR,EBAY,AMC,ZNGA,MRN... 5 427 ... TWTR,AMD,AMC,WISH,HOOD,FANG,SONO,SNAP,SPCE,BYN... 6 430 ... PFE,MSFT,BABA,AMZN,TSLA,AAPL,MRNA,NIO,WISH,BBW... [7 rows x 4 columns]
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
print(data.tail(10))id ... calls 112 724 ... AMD,NVDA,LAZR,AFRM,BHC,MRNA,GM,AA,PTON,HZO,MAR... 113 727 ... AMD,TSLA,NVDA,AMC,PTON,NFLX,AMZN,DISH,NRG,FB,L... 114 731 ... TSLA,NVDA,AMD,AMC,AAPL,FB,MSFT,AAL,RBLX,AMZN,B... 115 734 ... NVDA,TSLA,AMC,MSFT,AMD,AMZN,FB,BABA,BAC,EW,ZM,... 116 736 ... AMC,T,MSFT,FB,CVX,NVDA,BABA,AMD,RUN,PLTR,INTC,... 117 738 ... INTC,TSLA,LCID,NIO,AMZN,BA,AMD,UAA,CLX,HOOD,SK... 118 740 ... AMZN,TSLA,BA,HOOD,NIO,AMD,TWTR,AFRM,AMC,BHC,FL... 119 743 ... AMD,AFRM,PLUG,NVDA,HOOD,TTWO,BA,UPS,TLRY,XOM,F... 120 746 ... UPST,XOM,AMD,Z,FCX,GO,NFLX,RBLX,DWAC,AMRN,FDX,... 121 748 ... PYPL,AMD,FB,GOOGL,RBLX,SQ,WFC,PENN,QCOM,AMGN,T... [10 rows x 4 columns]
Filtrer dans un dataframe
La trame de données que nous extrayons de la base de données sqlite contient plus de 100 lignes. Nous pouvons vouloir filtrer cela pour limiter la quantité de données consultées, comment pouvons-nous faire cela ? Il existe une syntaxe spéciale pour celle mise en évidence ci-dessous.
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
filtered_row = data[data['created_at'].str.contains('2022-01-24')]
print(filtered_row) id ... calls 114 731 ... TSLA,NVDA,AMD,AMC,AAPL,FB,MSFT,AAL,RBLX,AMZN,B... [1 rows x 4 columns]
Remplacer des valeurs dans un dataframe
Pour remplacer une ou plusieurs valeurs dans une trame de données, nous pouvons utiliser la fonction .replace(). Voici un exemple de cette technique.
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
replaced_ticker = data.replace(to_replace='AMC', value='replaced!', regex=True)
print(replaced_ticker)id ... calls 0 416 ... replaced!,MRNA,TSLA,BYND,SNAP,CHPT,NCTY,GOOGL,... 1 418 ... replaced!,SNAP,FSR,PFE,AMD,MRNA,ZEV,AMZN,BAC,S... 2 419 ... FUBO,replaced!,COIN,AMD,BA,AMZN,CAT,SPCE,CHPT,... 3 424 ... MRNA,IP,replaced!,AMZN,MU,SONO,HYRE,ROKU,AMD,H... 4 425 ... WISH,AMZN,AMD,SPCE,BABA,LAZR,EBAY,replaced!,ZN...
Supprimer des colonnes
Pour supprimer une colonne du dataframe, utilisez simplement la fonction .drop() comme ceci.
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
removed_column = data.drop('calls', axis=1)
print(removed_column)id created_at updated_at 0 416 2021-08-09 20:29:27.252553 2021-08-09 20:29:27.252553 1 418 2021-08-10 18:36:36.024030 2021-08-10 18:36:36.024030 2 419 2021-08-11 14:41:28.597140 2021-08-11 14:41:28.597140 3 424 2021-08-12 20:18:08.020679 2021-08-12 20:18:08.020679 4 425 2021-08-13 18:27:07.071109 2021-08-13 18:27:07.071109 .. ... ... ... 117 738 2022-01-27 21:18:50.158205 2022-01-27 21:18:50.159205 118 740 2022-01-28 22:12:43.995624 2022-01-28 22:12:43.995624 119 743 2022-01-31 20:52:06.498233 2022-01-31 20:52:06.498233 120 746 2022-02-01 21:01:50.009382 2022-02-01 21:01:50.009382 121 748 2022-02-02 21:17:53.769019 2022-02-02 21:17:53.769019 [122 rows x 3 columns]
Suppression de lignes du dataframe
Dans cet exemple, nous allons supprimer des lignes de données du dataframe tout en spécifiant plusieurs étiquettes à la fois à l'aide d'une liste.
import pandas as pd
import sqlite3
connection = sqlite3.connect('db.sqlite3')
data = pd.read_sql('select * from stockapp_call', connection)
removed_row = data.iloc[0:3].drop(['id', 'created_at', 'updated_at'], axis=1)
print(removed_row)calls 0 AMC,MRNA,TSLA,BYND,SNAP,CHPT,NCTY,GOOGL,VXRT,N... 1 AMC,SNAP,FSR,PFE,AMD,MRNA,ZEV,AMZN,BAC,SBUX,NV... 2 FUBO,AMC,COIN,AMD,BA,AMZN,CAT,SPCE,CHPT,RBLX,N...
Qu'est-ce qu'un résumé de la trame de données Pandas ?
Le pandas.DataFrame La structure des données rend le travail avec des données bidimensionnelles très efficace. Nous avons vu plusieurs façons de créer et de travailler avec un Pandas DataFrame ainsi que la façon d'effectuer certaines des fonctions courantes telles que l'accès, la modification, l'ajout, le tri, le filtrage et la suppression de données lorsque vous travaillez avec des DataFrames.

