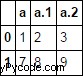
le paramètre pertinent est mangle_dupe_cols
à partir de la documentation
mangle_dupe_cols : boolean, default True
Duplicate columns will be specified as 'X.0'...'X.N', rather than 'X'...'X'
par défaut, tous vos 'a' les colonnes sont nommées 'a.0'...'a.N' comme spécifié ci-dessus.
si vous avez utilisé mangle_dupe_cols=False , en important ce csv produirait une erreur.
vous pouvez obtenir toutes vos colonnes avec
df.filter(like='a')
démonstration
from StringIO import StringIO
import pandas as pd
txt = """a, a, a, b, c, d
1, 2, 3, 4, 5, 6
7, 8, 9, 10, 11, 12"""
df = pd.read_csv(StringIO(txt), skipinitialspace=True)
df
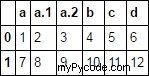
df.filter(like='a')