Je suis toujours surpris de la façon dont les expressions régulières survécu à sept décennies de bouleversement technologique. Ils ressemblent beaucoup à ceux d'il y a 70 ans. Cela signifie que si vous maîtrisez les expressions régulières, vous vous construisez une compétence durable et très pertinente sur le marché d'aujourd'hui. Vous pourrez écrire en une seule ligne de code ce qui en prend des dizaines à d'autres !
Cet article concerne le re.split(pattern, string) méthode de la bibliothèque re de Python.
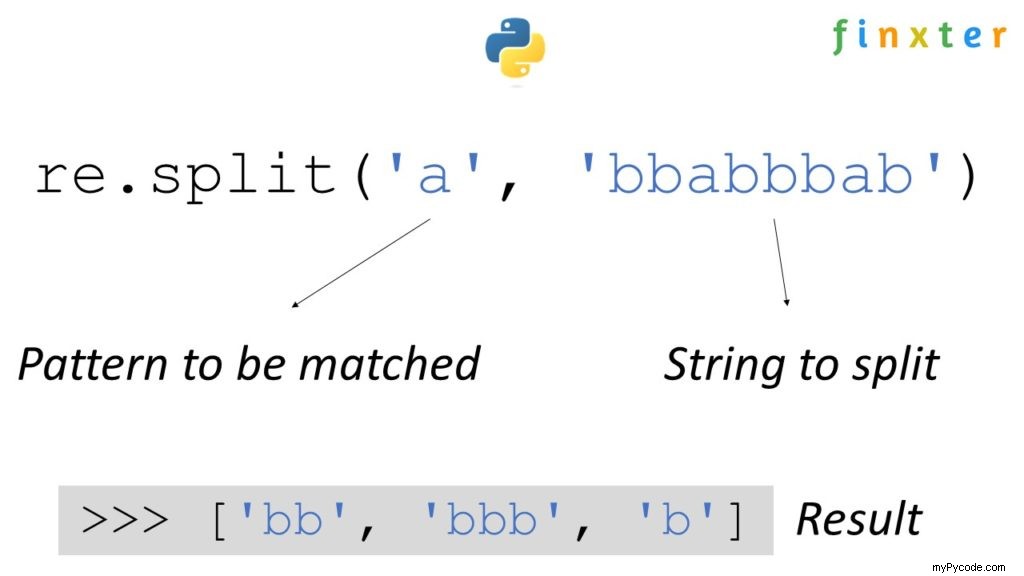
Le re.split(pattern, string) la méthode correspond à toutes les occurrences du pattern dans le string et divise la chaîne le long des correspondances résultant en une liste de chaînes entre les matchs. Par exemple, re.split('a', 'bbabbbab') résultats dans la liste des chaînes ['bb', 'bbb', 'b'] .
Voulez-vous maîtriser la superpuissance des regex ? Découvrez mon nouveau livre La façon la plus intelligente d'apprendre les expressions régulières en Python avec l'approche innovante en 3 étapes pour un apprentissage actif :(1) étudiez un chapitre de livre, (2) résolvez un puzzle de code et (3) regardez une vidéo de chapitre éducatif.
Comment fonctionne re.split() en Python ?
Le re.split(pattern, string, maxsplit=0, flags=0) La méthode renvoie une liste de chaînes en faisant correspondre toutes les occurrences du modèle dans la chaîne et en divisant la chaîne par celles-ci.
Voici un exemple minimal :
>>> import re
>>> string = 'Learn Python with\t Finxter!'
>>> re.split('\s+', string)
['Learn', 'Python', 'with', 'Finxter!']
La chaîne contient quatre mots séparés par des espaces blancs (en particulier :l'espace vide ' ' et le caractère tabulaire '\t' ). Vous utilisez l'expression régulière '\s+' pour faire correspondre toutes les occurrences d'un nombre positif d'espaces suivants. Les sous-chaînes correspondantes servent de délimiteurs. Le résultat est la chaîne divisée le long de ces délimiteurs.
Mais ce n'est pas tout! Examinons la définition formelle de la méthode de fractionnement.
Spécification
re.split(pattern, string, maxsplit=0, flags=0)
La méthode a quatre arguments, dont deux sont facultatifs.
pattern— le modèle d'expression régulière que vous souhaitez utiliser comme délimiteur.string— le texte que vous souhaitez décomposer en une liste de chaînes.maxsplit(argument facultatif) — le nombre maximal d'opérations de fractionnement (=la taille de la liste renvoyée). Par défaut, lemaxsplitl'argument est 0, ce qui signifie qu'il est ignoré.flags(argument facultatif) — un modificateur plus avancé qui vous permet de personnaliser le comportement de la fonction. Par défaut, le module regex ne considère aucun drapeau. Vous voulez savoir comment utiliser ces drapeaux ? Consultez cet article détaillé sur le blog Finxter.
Les premier et second arguments sont obligatoires. Les troisième et quatrième arguments sont facultatifs. Vous découvrirez ces arguments plus en détail plus tard.
Valeur de retour : La méthode regex split renvoie une liste de sous-chaînes obtenues en utilisant la regex comme délimiteur.
Exemple minimal de division d'expression régulière
Étudions quelques exemples supplémentaires, du plus simple au plus complexe.
L'utilisation la plus simple est avec seulement deux arguments :l'expression régulière du délimiteur et la chaîne à diviser.
>>> import re
>>> string = 'fgffffgfgPythonfgisfffawesomefgffg'
>>> re.split('[fg]+', string)
['', 'Python', 'is', 'awesome', '']
Vous utilisez un nombre arbitraire de 'f' ou 'g' caractères comme délimiteurs d'expressions régulières. Comment accomplissez-vous cela? En combinant la classe de caractères regex [A] et une ou plusieurs regex A+ dans l'expression régulière suivante :[fg]+ . Les chaînes intermédiaires sont ajoutées à la liste de retour.
Article connexe : Python Regex Superpower - Le guide ultime
Comment utiliser l'argument maxsplit ?
Que faire si vous ne voulez pas diviser toute la chaîne mais seulement un nombre limité de fois. Voici un exemple :
>>> string = 'a-bird-in-the-hand-is-worth-two-in-the-bush'
>>> re.split('-', string, maxsplit=5)
['a', 'bird', 'in', 'the', 'hand', 'is-worth-two-in-the-bush']
>>> re.split('-', string, maxsplit=2)
['a', 'bird', 'in-the-hand-is-worth-two-in-the-bush']
Nous utilisons le délimiteur simple regex '-' pour diviser la chaîne en sous-chaînes. Dans le premier appel de méthode, nous définissons maxsplit=5 pour obtenir six éléments de liste. Dans le deuxième appel de méthode, nous définissons maxsplit=3 pour obtenir trois éléments de liste. Pouvez-vous voir le motif ?
Vous pouvez également utiliser des arguments de position pour enregistrer certains caractères :
>>> re.split('-', string, 2)
['a', 'bird', 'in-the-hand-is-worth-two-in-the-bush']
Mais comme de nombreux codeurs ne connaissent pas le maxsplit argument, vous devriez probablement utiliser l'argument mot-clé pour la lisibilité.
Comment utiliser l'argument de drapeau facultatif ?
Comme vous l'avez vu dans la spécification, le re.split() la méthode est livrée avec un quatrième 'flag' facultatif argument :
re.split(pattern, string, maxsplit=0, flags=0)
À quoi sert l'argument flags ?
Les drapeaux vous permettent de contrôler le moteur d'expressions régulières. Parce que les expressions régulières sont si puissantes, elles sont un moyen utile d'activer et de désactiver certaines fonctionnalités (par exemple, s'il faut ignorer les majuscules lors de la correspondance avec votre regex).
| Syntaxe | Signification |
| re.ASCII | Si vous n'utilisez pas cet indicateur, les symboles spéciaux Python regex w, W, b, B, d, D, s et S correspondront aux caractères Unicode. Si vous utilisez cet indicateur, ces symboles spéciaux ne correspondront qu'aux caractères ASCII, comme leur nom l'indique. |
| re.A | Identique à re.ASCII |
| re.DEBUG | Si vous utilisez cet indicateur, Python affichera des informations utiles sur le shell qui vous aideront à déboguer votre regex. |
| re.IGNORECASE | Si vous utilisez cet indicateur, le moteur regex effectuera une correspondance insensible à la casse. Donc, si vous recherchez [A-Z], cela correspondra également à [a-z]. |
| re.I | Identique à re.IGNORECASE |
| re.LOCALE | N'utilisez jamais ce drapeau. Il est déprécié - l'idée était d'effectuer une correspondance insensible à la casse en fonction de vos paramètres régionaux actuels. Mais ce n'est pas fiable. |
| re.L | Identique à re.LOCALE |
| re.MULTILINE | Cet indicateur active la fonctionnalité suivante :l'expression régulière de début de chaîne « ^ » correspond au début de chaque ligne (plutôt qu'uniquement au début de la chaîne). Il en va de même pour la regex de fin de chaîne « $ » qui correspond désormais également à la fin de chaque ligne dans une chaîne multiligne. |
| re.M | Identique à re.MULTILINE |
| re.DOTALL | Sans utiliser cet indicateur, la regex point '.' correspond à tous les caractères sauf le caractère de nouvelle ligne 'n'. Activez ce drapeau pour vraiment faire correspondre tous les caractères, y compris le caractère de nouvelle ligne. |
| re.S | Identique à re.DOTALL |
| re.VERBOSE | Pour améliorer la lisibilité des expressions régulières compliquées, vous pouvez autoriser les commentaires et le formatage (multiligne) de la regex elle-même. C'est possible avec ce drapeau :tous les caractères blancs et les lignes qui commencent par le caractère '#' sont ignorés dans la regex. |
| re.X | Identique à re.VERBOSE |
Voici comment vous l'utiliseriez dans un exemple pratique :
>>> import re
>>> re.split('[xy]+', text, flags=re.I)
['the', 'russians', 'are', 'coming'] Bien que votre regex soit en minuscules, nous ignorons la capitalisation en utilisant le drapeau re.I qui est l'abréviation de re.IGNORECASE. Si nous ne le faisions pas, le résultat serait tout autre :
>>> re.split('[xy]+', text)
['theXXXYYYrussiansXX', 'are', 'Y', 'coming'] Comme la classe de caractères [xy] ne contient que des caractères d'espacement inférieur "x" et "y", leurs variantes majuscules apparaissent dans la liste renvoyée plutôt que d'être utilisées comme délimiteurs.
Quelle est la différence entre les méthodes re.split() et string.split() en Python ?
La méthode re.split() est beaucoup plus puissant. Le re.split(pattern, string) peut fractionner une chaîne le long de toutes les occurrences d'un modèle correspondant. Le modèle peut être arbitrairement compliqué. Ceci est en contraste avec le string.split(delimiter) méthode qui divise également une chaîne en sous-chaînes le long du délimiteur. Cependant, le délimiteur doit être une chaîne normale.
Un exemple où le plus puissant re.split() La méthode la plus efficace consiste à diviser un texte le long de n'importe quel caractère d'espace :
import re
text = '''
Ha! let me see her: out, alas! he's cold:
Her blood is settled, and her joints are stiff;
Life and these lips have long been separated:
Death lies on her like an untimely Frost
Upon the sweetest flower of all the field.
'''
print(re.split('\s+', text))
'''
['', 'Ha!', 'let', 'me', 'see', 'her:', 'out,', 'alas!',
"he's", 'cold:', 'Her', 'blood', 'is', 'settled,', 'and',
'her', 'joints', 'are', 'stiff;', 'Life', 'and', 'these',
'lips', 'have', 'long', 'been', 'separated:', 'Death',
'lies', 'on', 'her', 'like', 'an', 'untimely', 'Frost',
'Upon', 'the', 'sweetest', 'flower', 'of', 'all', 'the',
'field.', '']
'''
Le re.split() divise la chaîne selon n'importe quel nombre positif de caractères d'espacement. Vous ne pourriez pas obtenir un tel résultat avec string.split(delimiter) car le délimiteur doit être une chaîne de taille constante.
Méthodes Re associées
Il existe cinq méthodes d'expression régulière importantes que vous devez maîtriser :
- Le
re.findall(pattern, string)La méthode renvoie une liste de correspondances de chaînes. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.search(pattern, string)La méthode renvoie un objet match de la première correspondance. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.match(pattern, string)La méthode renvoie un objet match si l'expression régulière correspond au début de la chaîne. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.fullmatch(pattern, string)La méthode renvoie un objet match si l'expression régulière correspond à la chaîne entière. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.compile(pattern)La méthode prépare le modèle d'expression régulière et renvoie un objet regex que vous pouvez utiliser plusieurs fois dans votre code. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.split(pattern, string)La méthode renvoie une liste de chaînes en faisant correspondre toutes les occurrences du modèle dans la chaîne et en divisant la chaîne par celles-ci. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.sub(pattern, repl, string, count=0, flags=0)La méthode renvoie une nouvelle chaîne où toutes les occurrences du modèle dans l'ancienne chaîne sont remplacées parrepl. Pour en savoir plus, consultez le didacticiel de notre blog.
Ces cinq méthodes représentent 80 % de ce que vous devez savoir pour démarrer avec la fonctionnalité d'expression régulière de Python.

