Voulez-vous remplacer toutes les occurrences d'un motif dans une chaîne ? Vous êtes au bon endroit !
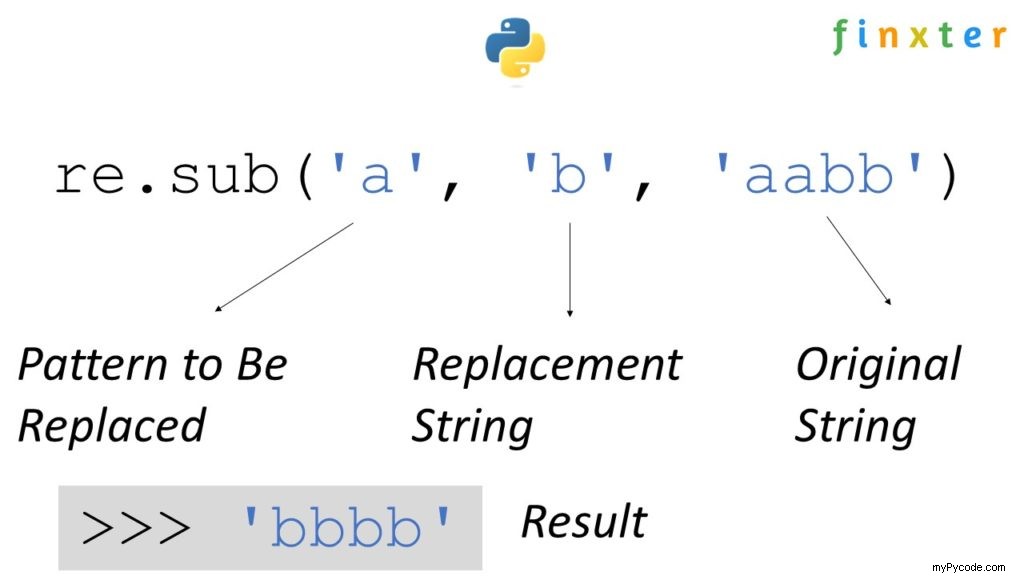
La fonction regex re.sub(P, R, S) remplace toutes les occurrences du modèle P avec le remplacement R dans la chaîne S . Il renvoie une nouvelle chaîne. Par exemple, si vous appelez re.sub('a', 'b', 'aabb') , le résultat sera la nouvelle chaîne 'bbbb' avec tous les caractères 'a' remplacé par 'b' .
Vous pouvez également regarder mon didacticiel vidéo pendant que vous lisez cet article :
Article connexe : Python Regex Superpower - Le guide ultime
Voulez-vous maîtriser la superpuissance des regex ? Découvrez mon nouveau livre La façon la plus intelligente d'apprendre les expressions régulières en Python avec l'approche innovante en 3 étapes pour un apprentissage actif :(1) étudiez un chapitre de livre, (2) résolvez un puzzle de code et (3) regardez une vidéo de chapitre éducatif.
Répondons à la question suivante :
Comment fonctionne re.sub() en Python ?
Le re.sub(pattern, repl, string, count=0, flags=0) renvoie une nouvelle chaîne où toutes les occurrences du pattern dans l'ancienne chaîne sont remplacés par repl .
Voici un exemple minimal :
>>> import re
>>> text = 'C++ is the best language. C++ rocks!'
>>> re.sub('C\+\+', 'Python', text)
'Python is the best language. Python rocks!'
>>>
Le texte contient deux occurrences de la chaîne 'C++' . Vous utilisez le re.sub() méthode pour rechercher toutes ces occurrences. Votre objectif est de remplacer tous ceux par la nouvelle chaîne 'Python' (Python est le meilleur langage après tout).
Notez que vous devez échapper le '+' symbole en 'C++' sinon cela signifierait au moins un regex .
Vous pouvez également voir que le sub() remplace tous les modèles correspondants dans la chaîne, pas seulement le premier.
Mais il y a plus ! Regardons la définition formelle du sub() méthode.
Spécification
re.sub(pattern, repl, string, count=0, flags=0)
La méthode a quatre arguments, dont deux sont facultatifs.
pattern:le modèle d'expression régulière pour rechercher les chaînes que vous souhaitez remplacer.repl:la chaîne ou la fonction de remplacement. S'il s'agit d'une fonction, elle doit prendre un argument (l'objet match) qui est passé pour chaque occurrence du modèle. La valeur de retour de la fonction de remplacement est une chaîne qui remplace la sous-chaîne correspondante.string:le texte que vous souhaitez remplacer.count(argument facultatif) :le nombre maximum de remplacements que vous souhaitez effectuer. Par défaut, vous utilisezcount=0qui se lit comme remplace toutes les occurrences du modèle .flags(argument optionnel) :un modificateur plus avancé qui permet de personnaliser le comportement de la méthode. Par défaut, vous n'utilisez aucun drapeau. Vous voulez savoir comment utiliser ces drapeaux ? Consultez cet article détaillé sur le blog Finxter.
Les trois premiers arguments sont obligatoires. Les deux arguments restants sont facultatifs.
Vous découvrirez ces arguments plus en détail plus tard.
Valeur de retour :
Une nouvelle chaîne où count occurrences des premières sous-chaînes qui correspondent au pattern sont remplacés par la valeur de chaîne définie dans le repl argument.
Exemple sous-minimal de Regex
Étudions quelques exemples supplémentaires, du plus simple au plus complexe.
L'utilisation la plus simple est avec seulement trois arguments :le modèle 'sing ‘, la chaîne de remplacement 'program' , et la chaîne que vous souhaitez modifier (text dans notre exemple).
>>> import re
>>> text = 'Learn to sing because singing is fun.'
>>> re.sub('sing', 'program', text)
'Learn to program because programing is fun.' Ignorez simplement l'erreur de grammaire pour l'instant. Vous avez compris :nous ne chantons pas, nous programmons.
Mais que se passe-t-il si vous voulez réellement corriger cette erreur de grammaire ? Après tout, c'est de la programmation , pas de programmation . Dans ce cas, nous devons remplacer 'sing' avec 'program' dans certains cas et 'sing' avec 'programm' dans d'autres cas.
Vous voyez où cela nous mène :le sub l'argument doit être une fonction ! Alors essayons ceci :
import re
def sub(matched):
if matched.group(0)=='singing':
return 'programming'
else:
return 'program'
text = 'Learn to sing because singing is fun.'
print(re.sub('sing(ing)?', sub, text))
# Learn to program because programming is fun.
Dans cet exemple, vous définissez d'abord une fonction de substitution sub . La fonction prend l'objet correspondant en entrée et renvoie une chaîne. S'il correspond à la forme plus longue 'singing' , il renvoie 'programming' . Sinon, il correspond à la forme plus courte 'sing' , il renvoie donc la chaîne de remplacement la plus courte 'program' Au lieu.
Comment utiliser l'argument Count de la sous-méthode Regex ?
Que faire si vous ne voulez pas substituer toutes les occurrences d'un modèle mais seulement un nombre limité d'entre elles ? Utilisez simplement le count dispute! Voici un exemple :
>>> import re
>>> s = 'xxxxxxhelloxxxxxworld!xxxx'
>>> re.sub('x+', '', s, count=2)
'helloworld!xxxx'
>>> re.sub('x+', '', s, count=3)
'helloworld!'
Dans la première opération de substitution, vous ne remplacez que deux occurrences du modèle 'x+' . Dans le second, vous remplacez les trois.
Vous pouvez également utiliser des arguments de position pour enregistrer certains caractères :
>>> re.sub('x+', '', s, 3)
'helloworld!'
Mais comme de nombreux codeurs ne connaissent pas le count argument, vous devriez probablement utiliser l'argument mot-clé pour la lisibilité.
Comment utiliser l'argument de drapeau facultatif ?
Comme vous l'avez vu dans la spécification, le re.sub() la méthode est livrée avec un quatrième flag facultatif argument :
re.sub(pattern, repl, string, count=0, flags=0)
À quoi sert le flags dispute ?
Les drapeaux vous permettent de contrôler le moteur d'expressions régulières. Parce que les expressions régulières sont si puissantes, elles sont un moyen utile d'activer et de désactiver certaines fonctionnalités (par exemple, s'il faut ignorer les majuscules lors de la correspondance avec votre regex).
| Syntaxe | Signification |
| re.ASCII | Si vous n'utilisez pas cet indicateur, les symboles spéciaux Python regex w, W, b, B, d, D, s et S correspondront aux caractères Unicode. Si vous utilisez cet indicateur, ces symboles spéciaux ne correspondront qu'aux caractères ASCII, comme leur nom l'indique. |
| re.A | Identique à re.ASCII |
| re.DEBUG | Si vous utilisez cet indicateur, Python affichera des informations utiles sur le shell qui vous aideront à déboguer votre regex. |
| re.IGNORECASE | Si vous utilisez cet indicateur, le moteur regex effectuera une correspondance insensible à la casse. Donc, si vous recherchez [A-Z], cela correspondra également à [a-z]. |
| re.I | Identique à re.IGNORECASE |
| re.LOCALE | N'utilisez jamais ce drapeau. Il est déprécié - l'idée était d'effectuer une correspondance insensible à la casse en fonction de vos paramètres régionaux actuels. Mais ce n'est pas fiable. |
| re.L | Identique à re.LOCALE |
| re.MULTILINE | Cet indicateur active la fonctionnalité suivante :l'expression régulière de début de chaîne « ^ » correspond au début de chaque ligne (plutôt qu'uniquement au début de la chaîne). Il en va de même pour la regex de fin de chaîne « $ » qui correspond désormais également à la fin de chaque ligne dans une chaîne multiligne. |
| re.M | Identique à re.MULTILINE |
| re.DOTALL | Sans utiliser cet indicateur, la regex point '.' correspond à tous les caractères sauf le caractère de nouvelle ligne 'n'. Activez ce drapeau pour vraiment faire correspondre tous les caractères, y compris le caractère de nouvelle ligne. |
| re.S | Identique à re.DOTALL |
| re.VERBOSE | Pour améliorer la lisibilité des expressions régulières compliquées, vous pouvez autoriser les commentaires et le formatage (multiligne) de la regex elle-même. C'est possible avec ce drapeau :tous les caractères blancs et les lignes qui commencent par le caractère '#' sont ignorés dans la regex. |
| re.X | Identique à re.VERBOSE |
Voici comment vous l'utiliseriez dans un exemple minimal :
>>> import re
>>> s = 'xxxiiixxXxxxiiixXXX'
>>> re.sub('x+', '', s)
'iiiXiiiXXX'
>>> re.sub('x+', '', s, flags=re.I)
'iiiiii'
Dans la deuxième opération de substitution, vous ignorez la capitalisation en utilisant le drapeau re.I qui est l'abréviation de re.IGNORECASE . C'est pourquoi il remplace même la majuscule 'X' caractères qui correspondent maintenant à la regex 'x+' , aussi.
Quelle est la différence entre Regex Sub et String Replace ?
En quelque sorte, le re.sub() est la variante la plus puissante du string.replace() méthode décrite en détail dans cet article du blog Finxter.
Pourquoi? Parce que vous pouvez remplacer toutes les occurrences d'un modèle regex plutôt que seulement toutes les occurrences d'une chaîne dans une autre chaîne.
Donc avec re.sub() vous pouvez faire tout ce que vous pouvez faire avec string.replace() — mais des choses de plus !
Voici un exemple :
>>> 'Python is python is PYTHON'.replace('python', 'fun')
'Python is fun is PYTHON'
>>> re.sub('(Python)|(python)|(PYTHON)', 'fun', 'Python is python is PYTHON')
'fun is fun is fun'
Le string.replace() la méthode remplace uniquement le mot minuscule 'python' tandis que le re.sub() remplace toutes les occurrences de variantes majuscules ou minuscules.
Notez que vous pouvez accomplir la même chose encore plus facilement avec le flags arguments.
>>> re.sub('python', 'fun', 'Python is python is PYTHON', flags=re.I)
'fun is fun is fun' Comment supprimer le modèle Regex en Python ?
Rien de plus simple que ça. Utilisez simplement la chaîne vide comme chaîne de remplacement :
>>> re.sub('p', '', 'Python is python is PYTHON', flags=re.I)
'ython is ython is YTHON'
Vous remplacez toutes les occurrences du modèle 'p' avec la chaîne vide '' . En d'autres termes, vous supprimez toutes les occurrences de 'p' . Lorsque vous utilisez le flags=re.I argument, vous ignorez les majuscules.
Méthodes Re associées
Il existe cinq méthodes d'expression régulière importantes que vous devez maîtriser :
- Le
re.findall(pattern, string)La méthode renvoie une liste de correspondances de chaînes. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.search(pattern, string)La méthode renvoie un objet match de la première correspondance. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.match(pattern, string)La méthode renvoie un objet match si l'expression régulière correspond au début de la chaîne. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.fullmatch(pattern, string)La méthode renvoie un objet match si l'expression régulière correspond à la chaîne entière. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.compile(pattern)La méthode prépare le modèle d'expression régulière et renvoie un objet regex que vous pouvez utiliser plusieurs fois dans votre code. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.split(pattern, string)La méthode renvoie une liste de chaînes en faisant correspondre toutes les occurrences du modèle dans la chaîne et en divisant la chaîne par celles-ci. Pour en savoir plus, consultez le didacticiel de notre blog. - Le
re.sub(pattern, repl, string, count=0, flags=0)La méthode renvoie une nouvelle chaîne où toutes les occurrences du modèle dans l'ancienne chaîne sont remplacées parrepl. Pour en savoir plus, consultez le didacticiel de notre blog.
Ces sept méthodes représentent 80 % de ce que vous devez savoir pour démarrer avec la fonctionnalité d'expression régulière de Python.
Résumé
Vous avez appris le re.sub(pattern, repl, string, count=0, flags=0) renvoie une nouvelle chaîne où toutes les occurrences du pattern dans l'ancien string sont remplacés par repl .