Cette expression n'est pas délimitée par le côté gauche et pourrait s'exécuter plus rapidement si tous les caractères souhaités étaient similaires à l'exemple que vous avez fourni dans votre question :
([a-z0-9;.-]+)(.*)
Ici, nous supposons que vous voudrez peut-être simplement filtrer ces caractères spéciaux dans les parties gauche et droite de vos chaînes d'entrée.
Vous pouvez inclure d'autres caractères et limites à l'expression, et vous pouvez même la modifier/changer en une expression plus simple et plus rapide, si vous le souhaitez.

Graphique descriptif RegEx
Ce graphique montre comment l'expression fonctionnerait et vous pouvez visualiser d'autres expressions dans ce lien :
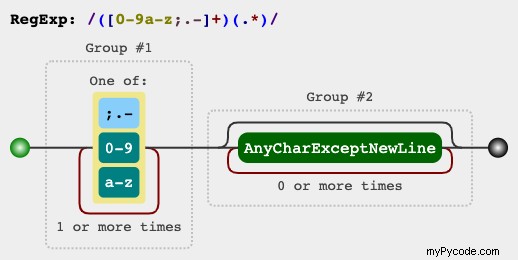
Si vous souhaitez ajouter d'autres limites dans le côté droit, vous pouvez simplement le faire :
([a-z0-9;.-]+)(.*)$
ou même vous pouvez lister vos caractères spéciaux à gauche et à droite du groupe de capture.
Test JavaScript
const regex = /([a-z0-9;.-]+)(.*)$/gm;
const str = `[email protected]#\$abc-123-4;5.def)(*&^;\\n`;
let m;
while ((m = regex.exec(str)) !== null) {
// This is necessary to avoid infinite loops with zero-width matches
if (m.index === regex.lastIndex) {
regex.lastIndex++;
}
// The result can be accessed through the `m`-variable.
m.forEach((match, groupIndex) => {
console.log(`Found match, group ${groupIndex}: ${match}`);
});
}
Test de performances
Cet extrait de code JavaScript montre les performances de cette expression à l'aide d'une simple boucle.
const repeat = 1000000;
const start = Date.now();
for (var i = repeat; i >= 0; i--) {
const string = '[email protected]#\$abc-123-4;5.def)(*&^;\\n';
const regex = /([[email protected]#$)(*&^;]+)([a-z0-9;.-]+)(.*)$/gm;
var match = string.replace(regex, "$2");
}
const end = Date.now() - start;
console.log("YAAAY! \"" + match + "\" is a match ");
console.log(end / 1000 + " is the runtime of " + repeat + " times benchmark test. ");
Test Python
import re
regex = r"([a-z0-9;.-]+)(.*)$"
test_str = "[email protected]#$abc-123-4;5.def)(*&^;\\n"
print(re.findall(regex, test_str))
Sortie
[('abc-123-4;5.def', ')(*&^;\\n')]
Vous pouvez y parvenir en utilisant le carat ^ caractère au début d'un jeu de caractères pour annuler son contenu. [^a-zA-Z0-9] correspondra à tout ce qui n'est pas une lettre ou un chiffre.
^[^a-zA-Z0-9]+|[^a-zA-Z0-9]+$
Pour couper les caractères non verbaux (\W supérieur ) à partir du début/de la fin, mais ajoutez également le trait de soulignement qui appartient aux caractères de mot [A-Za-z0-9_] vous pouvez supprimer le _ dans une classe de caractères avec \W .
^[\W_]+|[\W_]+$
Voir la démo sur regex101. Ceci est très similaire à la réponse de @ CAustin et au commentaire de @ sln.
Pour obtenir la démo inverse et faites correspondre tout du premier au dernier caractère alphanumérique :
[^\W_](?:.*[^\W_])?
Ou avec alternance
démo
(|[^\W_] pour les chaînes contenant un seul alnum).
[^\W_].*[^\W_]|[^\W_]
Les deux avec re.DOTALL pour les chaînes multilignes. Saveurs Regex sans essayer [\s\S]* au lieu de .*
démo

