Dans cet article, vous découvrirez comment générer des ajustements exponentiels en exploitant le curve_fit() fonction de la bibliothèque Scipy. curve_fit() de SciPy permet de créer des fonctions d'ajustement personnalisées avec lesquelles nous pouvons décrire des points de données qui suivent une tendance exponentielle.
- Dans la première partie de l'article, le
curve_fit()La fonction est utilisée pour s'adapter à la tendance exponentielle du nombre de cas de COVID-19 enregistrés en Californie (CA). - La deuxième partie de l'article traite des histogrammes d'ajustement, caractérisés, également dans ce cas, par une tendance exponentielle.
Avis de non-responsabilité :Je ne suis pas virologue, je suppose que le montage d'une infection virale est défini par des modèles plus compliqués et plus précis ; cependant, le seul but de cet article est de montrer comment appliquer un ajustement exponentiel pour modéliser (à un certain degré d'approximation) l'augmentation du nombre total de cas d'infection par le COVID-19.
Ajustement exponentiel du nombre total de cas de COVID-19 en Californie
Les données relatives à la pandémie de COVID-19 ont été obtenues sur le site officiel des « Centers for Disease Control and Prevention » (https://data.cdc.gov/Case-Surveillance/United-States-COVID-19-Cases- and-Deaths-by-State-o/9mfq-cb36) et téléchargé en tant que fichier .csv. La première chose à faire est d'importer les données dans une dataframe Pandas. Pour cela, les fonctions Pandas pandas.read_csv() et pandas.Dataframe() Étaient employés. La dataframe créée est composée de 15 colonnes, parmi lesquelles on peut trouver la submit_date, l'état, le total des cas, les cas confirmés et d'autres observables associés. Pour avoir un aperçu de l'ordre dans lequel ces catégories sont affichées, nous imprimons l'en-tête de la trame de données ; comme on peut le remarquer, le nombre total de cas est répertorié sous la voix "tot_cases".
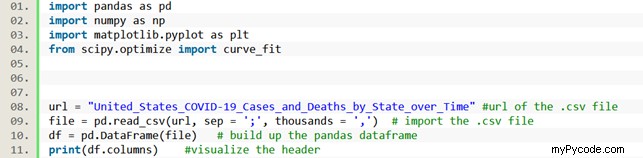
Puisque dans cet article nous ne nous intéressons qu'aux données relatives à la Californie, nous créons un sous-dataframe qui ne contient que les informations relatives à l'état de Californie. Pour ce faire, nous exploitons le potentiel de Pandas dans l'indexation des sous-sections d'une dataframe. Cette dataframe s'appellera df_CA (de Californie) et contiendra tous les éléments de la dataframe principale pour lesquels la colonne « state » est égale à « CA ». Après cette étape, nous pouvons construire deux tableaux, un (appelé tot_cases ) qui contient le nombre total de cas (le nom de la colonne d'en-tête respective est "tot_cases") et une qui contient le nombre de jours écoulés par le premier enregistrement (appelée jours ). Comme les données ont été enregistrées quotidiennement, pour construire le tableau "days", on construit simplement un tableau de nombres entiers équidistants de 0 à la longueur du tableau "tot_cases", de cette façon, chaque nombre fait référence au n° de jours écoulés depuis le premier enregistrement (jour 0).

À ce stade, nous pouvons définir la fonction qui sera utilisée par curve_fit() pour s'adapter au jeu de données créé. Une fonction exponentielle est définie par l'équation :
y =a*exp(b*x) +c
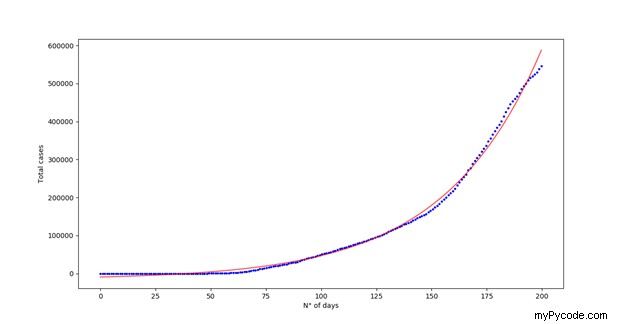
où a, b et c sont les paramètres d'ajustement. Nous allons donc définir la fonction exp_fit() qui renvoient la fonction exponentielle, y , précédemment défini. Le curve_fit() La fonction prend comme entrée nécessaire la fonction d'ajustement avec laquelle nous voulons ajuster les données, les tableaux x et y dans lesquels sont stockées les valeurs des points de données. Il est également possible de fournir des suppositions initiales pour chacun des paramètres d'ajustement en les insérant dans une liste appelée p0 = […] et les limites supérieure et inférieure de ces paramètres (pour une description complète du curve_fit() fonction, veuillez vous référer à https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html ). Dans cet exemple, nous ne fournirons que des suppositions initiales pour nos paramètres d'ajustement. De plus, nous n'ajusterons que le nombre total de cas des 200 premiers jours ; en effet, au fil des jours, le nombre de cas n'a plus suivi une tendance exponentielle (peut-être en raison d'une diminution du nombre de nouveaux cas). Pour ne faire référence qu'aux 200 premières valeurs des tableaux "days" et "tot_cases", nous exploitons le découpage de tableaux (par exemple, days[:200]).
La sortie de curve_fit() sont les paramètres d'ajustement, présentés dans le même ordre que celui utilisé lors de leur définition, dans la fonction d'ajustement. Gardant cela à l'esprit, nous pouvons construire le tableau qui contient les résultats ajustés, en l'appelant “fit_eq” .

Maintenant que nous avons construit le tableau d'ajustement, nous pouvons tracer à la fois les points de données d'origine et leur ajustement exponentiel.

Le résultat final sera un tracé comme celui de la figure 1 :
Application d'un ajustement exponentiel aux histogrammes
Maintenant que nous savons définir et utiliser un ajustement exponentiel, nous allons voir comment l'appliquer aux données affichées sur un histogramme. Les histogrammes sont fréquemment utilisés pour afficher les distributions de quantités spécifiques telles que les prix, les hauteurs, etc. Le type de distribution le plus courant est la distribution gaussienne ; cependant, certains types d'observables peuvent être définis par une distribution exponentielle décroissante. Dans une distribution exponentielle décroissante, la fréquence des observables décroît suivant une tendance exponentielle [A1]; un exemple possible est la durée de vie de la batterie de votre voiture (c'est-à-dire que la probabilité d'avoir une batterie qui dure pendant de longues périodes diminue de façon exponentielle). Le tableau à décroissance exponentielle sera défini en exploitant la fonction Numpy random.exponential(). Selon la documentation de Numpy, le random.exponential() la fonction tire des échantillons d'une distribution exponentielle ; il prend deux entrées, la "scale" qui est un paramètre définissant la décroissance exponentielle et la "taille" qui est la longueur du tableau qui sera généré. Une fois les valeurs aléatoires obtenues à partir d'une distribution exponentielle, nous devons générer l'histogramme ; pour ce faire, nous utilisons une autre fonction Numpy, appelée histogram(), qui génère un histogramme prenant en entrée la distribution des données (on met le binning à « auto », de cette manière la largeur des bins est automatiquement calculée). La sortie de histogram() est un tableau 2D ; le premier tableau contient les fréquences de la distribution tandis que le second contient les bords des cases. Comme nous ne nous intéressons qu'aux fréquences, nous affectons la première sortie à la variable « hist ». Pour cet exemple, nous allons générer le tableau contenant la position bin en utilisant le Numpy arange() fonction; les bacs auront une largeur de 1 et leur nombre sera égal au nombre d'éléments contenus dans le tableau "hist".

À ce stade, nous devons définir la fonction d'ajustement et appeler curve_fit() pour les valeurs de l'histogramme qui vient d'être créé. L'équation décrivant une décroissance exponentielle est similaire à celle définie dans la première partie; la seule différence est que l'exposant a un signe négatif, cela permet aux valeurs de décroître de façon exponentielle. Étant donné que les éléments du tableau "x", définis pour la position du bac, sont les coordonnées du bord gauche de chaque bac, nous définissons un autre tableau x qui stocke la position du centre de chaque bac (appelé "x_fit"); cela permet à la courbe d'ajustement de passer par le centre de chaque bac, ce qui donne une meilleure impression visuelle. Ce tableau sera défini en prenant les valeurs du côté gauche des bacs (éléments de tableau « x ») et en ajoutant la moitié de la taille du bac ; qui correspond à la moitié de la valeur de la deuxième position du bac (élément d'indice 1). Semblable à la partie précédente, nous appelons maintenant curve_fit(), générer le tableau d'ajustement et l'affecter à la variable "fit_eq".

Une fois la distribution ajustée, la dernière chose à faire est de vérifier le résultat en traçant à la fois l'histogramme et la fonction d'ajustement. Afin de tracer l'histogramme, nous allons utiliser la fonction matplotlib bar() , tandis que la fonction d'ajustement sera tracée en utilisant le classique plot() fonction.
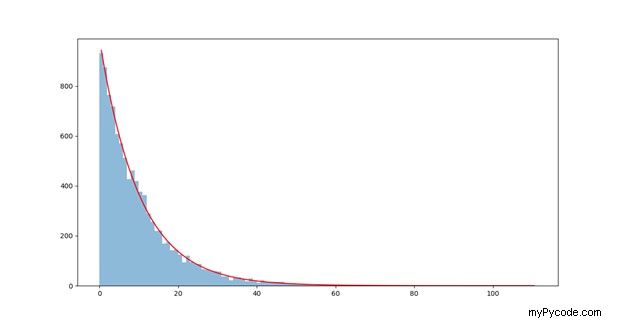
Le résultat final est affiché dans la Figure 2 :
Résumé
Dans ces deux exemples, le curve_fit() fonction a été utilisée pour appliquer différents ajustements exponentiels à des points de données spécifiques. Cependant, la puissance du curve_fit() fonction, est qu'il vous permet de définir vos propres fonctions d'ajustement personnalisées, qu'il s'agisse de fonctions linéaires, polynomiales ou logarithmiques. La procédure est identique à celle présentée dans cet article, la seule différence est dans la forme de la fonction qu'il faut définir avant d'appeler curve_fit() .
Code complet
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
url = "United_States_COVID-19_Cases_and_Deaths_by_State_over_Time" #url of the .csv file
file = pd.read_csv(url, sep = ';', thousands = ',') # import the .csv file
df = pd.DataFrame(file) # build up the pandas dataframe
print(df.columns) #visualize the header
df_CA = df[df['state'] == 'CA'] #initialize a sub-dataframe for storing only the values for the California
tot_cases = np.array((df_CA['tot_cases'])) #create an array with the total n° of cases
days = np.linspace(0, len(tot_cases), len(tot_cases)) # array containing the n° of days from the first recording
#DEFINITION OF THE FITTING FUNCTION
def exp_fit(x, a, b, c):
y = a*np.exp(b*x) + c
return y
#----CALL THE FITTING FUNCTION----
fit = curve_fit(exp_fit,days[:200],tot_cases[:200], p0 = [0.005, 0.03, 5])
fit_eq = fit[0][0]*np.exp(fit[0][1]*days[:200])+fit[0][2]
# #----PLOTTING-------
fig = plt.figure()
ax = fig.subplots()
ax.scatter(days[:200], tot_cases[:200], color = 'b', s = 5)
ax.plot(days[:200], fit_eq, color = 'r', alpha = 0.7)
ax.set_ylabel('Total cases')
ax.set_xlabel('N° of days')
plt.show()
#-----APPLY AN EXPONENTIAL FIT TO A HISTOGRAM--------
data = np.random.exponential(5, size=10000) #generating a random exponential distribution
hist = np.histogram(data, bins="auto")[0] #generating a histogram from the exponential distribution
x = np.arange(0, len(hist), 1) # generating an array that contains the coordinated of the left edge of each bar
#---DECAYING FIT OF THE DISTRIBUTION----
def exp_fit(x,a,b): #defining a decaying exponential function
y = a*np.exp(-b*x)
return y
x_fit = x + x[1]/2 # the point of the fit will be positioned at the center of the bins
fit_ = curve_fit(exp_fit,x_fit,hist) # calling the fit function
fit_eq = fit_[0][0]*np.exp(-fit_[0][1]*x_fit) # building the y-array of the fit
#Plotting
plt.bar(x,hist, alpha = 0.5, align = 'edge', width = 1)
plt.plot(x_fit,fit_eq, color = 'red')
plt.show()