scipy.interpolate.interp(1D, 2D, 3D)
Dans cet article, nous allons explorer comment effectuer des interpolations en Python, en utilisant la bibliothèque Scipy.
Scipy fournit de nombreuses fonctions utiles qui permettent le traitement et l'optimisation mathématiques de l'analyse des données. Plus précisément, en parlant d'interpolation de données, il fournit quelques fonctions utiles pour obtenir une interpolation rapide et précise, à partir d'un ensemble de points de données connus. Dans le texte suivant, nous analyserons trois scénarios d'interpolation différents ; interpolation unidimensionnelle interpolation bidimensionnelle et tridimensionnelle.
Les fonctions qui seront utilisées dans les extraits de code sont extraites du scipy.interpolate bibliothèque, et sont :.interp1d() , .interp2d() et .interpn() , respectivement.
Qu'est-ce que l'interpolation ?
D'un point de vue mathématique, l'interpolation indique le processus d'obtention de la valeur de points de données inconnus spécifiques situés entre d'autres points de données connus, après avoir décrit l'ensemble connu de points de données avec une fonction opportune.
Par exemple, si nous avons une série de points de données x0 , x1 , x2 ,…xn et nous connaissons les valeurs y0 , y1 , y2 ,…on (avec yn =f(xn )), grâce au processus d'interpolation, nous pouvons déterminer la valeur ym = f(xm ), où xm est un point situé entre deux des points déjà connus, c'est-à-dire lorsque x0
Les paragraphes suivants expliquent comment effectuer une interpolation lorsqu'il s'agit d'ensembles de données à 1, 2 ou 3 dimensions. Pour ce faire, nous nous appuierons sur la bibliothèque Python Scipy, plus précisément sur l'un de ses packages appelé interpolate qui fournissent la fonction .interp() pour effectuer de manière simple et immédiate cette tâche.
Interpolation 1D
Commençons par importer d'abord la fonction qui sera utilisée pour effectuer l'interpolation.
Comme déjà présenté, la fonction s'appelle interpolate.interp1d( ) et appartient au package Scipy. Puisque nous allons utiliser différentes fonctions d'interpolation pour chaque dimension (toutes appartenant à .interpolate ), nous allons juste importer .interpolate de la bibliothèque Scipy. Tout d'abord, nous devons créer un ensemble de données qui sera utilisé pour montrer le processus d'interpolation. Nous allons le faire en définissant un tableau x (en utilisant la fonction Numpy .linspace() ) de dix nombres équidistants, allant de 0 à 100. Le tableau y, à la place, sera défini par l'équation suivante :
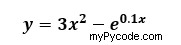
import numpy as np import matplotlib.pyplot as plt from scipy import interpolate #defining x and y arrays of the initial data set x = np.linspace(0, 100,10) y = 3*x**2 – np.exp(0.1*x)
Étant donné que le processus d'interpolation permet d'obtenir la valeur des points inconnus situés dans la plage des points déjà connus, nous définissons maintenant un autre tableau x qui contiendra plus de points que le premier tableau x ("x"). En particulier, nous exploitons à nouveau .linspace() pour construire un tableau de 100 nombres équidistants. Nous appelons alors ce tableau "x_new".
# x array that will be used for interpolating new point values x_new = np.linspace(0, 100, 100)
À ce stade, nous pouvons déjà interpoler notre ensemble de données initial et obtenir les valeurs des nouveaux points, que nous avons stockées dans le tableau "x_new". Pour ce faire, nous exploitons le .interpolate.interp1d() fonction; qui prend comme entrées obligatoires les tableaux x et y dans lesquels sont stockées les valeurs des points de données connus et renvoie en sortie la fonction d'interpolation avec laquelle on peut ensuite obtenir les valeurs des points inconnus. Une autre entrée facultative mais très importante qui peut être spécifiée dans le .interp1d() function est "kind", qui spécifie le type de fonction qui sera utilisé dans le processus d'interpolation. Il existe plusieurs options de "type", ce sont :
kind = ['linear', 'nearest', 'zero', 'slinear', 'quadratic', 'cubic', 'previous', 'next']
Les plus utilisés sont 'zero' , 'slinear' , 'quadratic' et 'cubic' , qui font référence à une interpolation spline d'ordre zéro, premier, deuxième ou troisième, respectivement. 'previous' et 'next' renvoyez simplement la valeur précédente ou suivante du point (veuillez vous référer à https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.interp1d.html pour la documentation complète sur .interp1d() ).
Afin de voir toutes ces différentes fonctions d'interpolation tracées ensemble, nous pouvons exploiter une boucle for et itérer le processus d'interpolation et de traçage des points de données, comme indiqué dans l'extrait de code ci-dessous.
kind = ['linear', 'nearest', 'zero', 'slinear', 'quadratic', 'cubic', 'previous', 'next']
fig = plt.figure()
ax = fig.subplots()
for i in kind:
#interpolation step
f = interpolate.interp1d(x, y, kind = i)
#y array that contains the interpolated data points
y_interp = f(x_new)
ax.plot(x_new, y_interp, alpha = 0.5, label = i)
ax.scatter(x,y)
plt.legend()
plt.show()
Comme vous pouvez le voir dans l'extrait de code, dans la boucle for , on fait l'interpolation en appelant la fonction .interp1d() et donner en entrée le tableau x et y défini en début de paragraphe; la fonction d'interpolation est alors affectée à la variable "f". A chaque étape d'itération, le "type" d'interpolation changera, en sélectionnant parmi les différents types contenus dans la liste "type". Pour obtenir finalement les valeurs des points inconnus, contenus dans le tableau « x_new », on définit le tableau « y_interp » en appliquant la fonction d'interpolation « f » qui vient d'être calculée au tableau « x_new ». Le résultat final est affiché dans la figure 1.
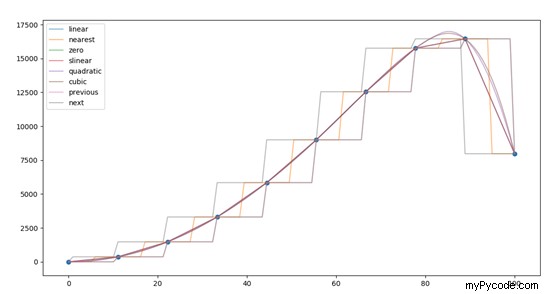
Illustration 1 : Différentes fonctions d'interpolation (types). Les points bleus sont les points de données initiaux connus ; comme on peut le voir, grâce au processus d'interpolation, nous sommes maintenant en mesure d'obtenir les valeurs de tous les points situés entre les points bleus.
Il est important de souligner que les seuls points connus à partir desquels nous avons dérivé tous les tracés illustrés à la figure 1 sont les points bleus (dix points). Grâce au processus d'interpolation, nous avons obtenu la valeur de tous les points situés entre la plage de ces dix points de données. En général, lors de l'interpolation d'un ensemble de données donné, il est important d'obtenir le plus d'informations possible sur la distribution des points de données connus ; cela aide à comprendre quel "type" de fonction d'interpolation donnera les meilleurs résultats. Cependant, dans la plupart des cas, les interpolations quadratique et cubique sont celles qui donnent les meilleurs résultats, comme vous pouvez le voir, elles se superposent pour presque tous les points de données.
Interpolation 2D
Maintenant que nous avons introduit la procédure d'interpolation sur des ensembles de données unidimensionnels, il est temps d'appliquer la même chose en deux dimensions. Comme vous le verrez, la procédure est très similaire; cette fois, la fonction qui sera utilisée s'appelle .interp2d() .
Puisque nous avons affaire à des points de données bidimensionnels, pour les tracer, nous devons créer une grille de points, puis attribuer une valeur spécifique à tous les points de la grille ; ce seront nos points de données initiaux connus à partir desquels nous interpolons les valeurs d'autres points de données.
Pour construire notre grille de points, nous définissons d'abord un tableau x et y (appelé "x" et "y") en utilisant .linspace() ; cette fois, les points sur notre grille seront de 13 et iront de zéro à quatre. Pour définir une grille à partir de ces deux tableaux, on utilise la fonction Numpy .meshgrid() . L'extrait de code suivant décrit la création de la grille.
x = np.linspace(0, 4, 13) y = np.linspace(0, 4, 13) X, Y = np.meshgrid(x, y)
Pour compléter la définition de notre ensemble initial de points de données, nous devons attribuer une valeur spécifique à tous les couples (x, y) de points sur la grille. Pour cela, nous définissons un nouveau tableau appelé Z, qui dépend des valeurs de X et Y (les points de la grille) et est défini par l'équation suivante :
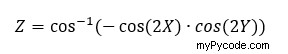
Z = np.arccos(-np.cos(2*X) * np.cos(2*Y))
De manière similaire à ce que nous avons fait dans le cas unidimensionnel, nous définissons maintenant une nouvelle grille plus dense qui contient les points qui seront interpolés à partir des valeurs (X, Y). Les 65 points de cette nouvelle grille vont toujours de 0 à quatre et sont stockés dans les tableaux « x2 » et « y2 ». Le processus est le même que celui utilisé pour définir la première grille.
#denser grid of points that we want to interpolate x2 = np.linspace(0, 4, 65) y2 = np.linspace(0, 4, 65) X2, Y2 = np.meshgrid(x2, y2)
La prochaine étape est l'interpolation; on appelle la fonction .interp2d() et affecter sa sortie (la fonction d'interpolation) à la variable "f". Toujours dans le cas bidimensionnel, nous pouvons choisir le "type" de fonction d'interpolation à utiliser dans le processus, cette fois il n'y a que trois options, "linéaire", "cubique" et "quantique", qui décrivent le type de splines utilisé dans l'interpolation (pour en savoir plus sur le concept de splines, veuillez vous référer à https://en.wikipedia.org/wiki/Spline_(mathematics) ). On affecte enfin à la variable Z2, les valeurs des points interpolés que l'on stocke précédemment dans les tableaux x2 et y2. Les lignes de code suivantes décrivent le processus d'interpolation.
#interpolation f = interpolate.interp2d(x, y, z, kind = ‘cubic’) Z2 = f(x2, y2)
Avec cette étape, nous avons terminé l'interpolation 2-D, et nous pouvons donc tracer les résultats afin d'avoir une représentation graphique de ce qui a été fait par la fonction. Pour une meilleure compréhension du processus d'interpolation en deux dimensions, nous traçons à la fois la grille initiale 13 × 13 (à gauche) et la grille interpolée 65 × 65 (à droite).
Nos tracés afficheront les grilles de points et décriront la valeur de chaque couple (x,y) avec une échelle de couleurs. Pour arriver à un tel résultat, on peut exploiter la fonction Matplotlib .pcolormesh() qui permet de créer un tracé en pseudo-couleur avec une grille rectangulaire non régulière (https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.pcolormesh.html ).
#Plotting fig = plt.figure() ax = fig.subplots(1,2) ax[0].pcolormesh(X, Y, Z) ax[1].pcolormesh(X2, Y2, Z2) plt.show()
Le résultat final est affiché dans la Figure 2 :
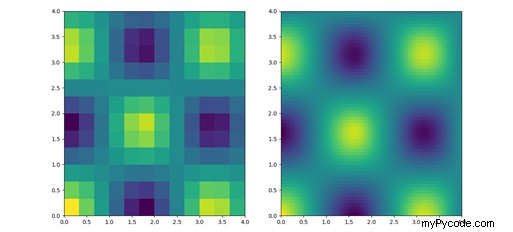
Illustration 2 : Résultat de .interp2d(); à partir d'une grille 13×13 (à gauche), on peut interpoler les valeurs attribuées à chaque couple (x, y) et obtenir les valeurs des couples de points le long d'une grille 65×65 (à droite).
Comme vous pouvez le voir sur la figure 2, grâce au processus d'interpolation 2D, nous avons densifié la première grille en interpolant la valeur des points supplémentaires contenus dans la plage des points de grille initiaux.
Interpolation 3D
Nous concluons cet article avec la dernière interpolation, nous augmentons à nouveau les dimensions et abordons le cas tridimensionnel. Pour accomplir cette tâche, nous exploitons la fonction .interpn(), qui peut être utilisé, plus généralement, pour des interpolations multidimensionnelles sur des grilles régulières (plus de documentation peut être trouvée ici https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.interpn.html ); cela signifie que nous pouvons utiliser cette fonction pour effectuer des interpolations sur des données avec n dimensions, avec n pouvant même être supérieur à 3.
Comme pour les autres cas, nous commençons notre code en définissant les tableaux qui constitueront notre grille 3D, cette fois nous aurons besoin de trois tableaux égaux, appelés « x », « y », « z ». Nous les stockons ensuite tous dans un tuple appelé "points" qui nous sera utile plus tard. De plus, nous définissons la grille 3D, en utilisant à nouveau .meshgrid() .
#arrays constituting the 3D grid x = np.linspace(0, 50, 50) y = np.linspace(0, 50, 50) z = np.linspace(0, 50, 50) points = (x, y, z) #generate a 3D grid X, Y, Z = np.meshgrid(x, y, z)
À ce point, nous devons attribuer une valeur à tous les triplets de (x, y, z) points sur la grille ; pour ce faire, nous définissons la fonction "func_3d(x,y,z)", qui, pour un ensemble spécifique de valeurs x,y et z, renvoie l'expression :
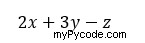
Comme vous pouvez le voir, la fonction dépend de trois variables indépendantes. Les valeurs de tous les triplets (x, y, z) seront stockées dans le tableau "values", définit en appelant la fonction "func_3d" sur tous les points X, Y, Z.
#evaluate the function on the points of the grid values = func_3d(X, Y, Z)
Puisqu'il ne serait pas possible de tracer la grille créée (cela donnerait un tracé en quatre dimensions); on définit juste un tableau contenant les triplets de points que l'on veut interpoler sous forme de listes. Dans notre cas, nous n'effectuerons l'interpolation que sur un seul triplet, défini dans le tableau "point".
point = np.array([2.5, 3.5, 1.5])
Nous appelons maintenant le .interpn() fonction pour effectuer l'interpolation. Contrairement aux deux fonctions précédentes, .interpn() n'a pas l'option "type", mais présente à la place celle appelée "méthode" ; la valeur par défaut est "linéaire". Les entrées de cette fonction sont le tuple contenant l'ensemble des trois tableaux qui composaient la grille 3D initiale (à savoir "x", "y" et "z", stockés dans le tuple "points"), les valeurs affectées à chaque triplet ( stocké dans le tableau "values") et le tableau contenant les coordonnées des points dans lesquels on veut effectuer l'interpolation (dans notre cas, un seul point, dont les coordonnées sont stockées dans "point"). Nous incluons tout cela dans une commande "print" afin d'obtenir directement le résultat de l'interpolation :
# points = the regular grid, #values =the data on the regular grid # point = the point that we want to evaluate in the 3D grid print(interpolate.interpn(points, values, point))
Le résultat final est 13,0 ; qui est la valeur interpolée pour le point de coordonnées (2.5, 3.5, 1.5).