Les cartes thermiques sont un type spécifique de tracé qui exploite la combinaison de schémas de couleurs et de valeurs numériques pour représenter des ensembles de données complexes et articulés. Ils sont largement utilisés dans les applications de science des données qui impliquent de grands nombres, comme la biologie, l'économie et la médecine.
Dans cette vidéo, nous verrons comment créer une carte thermique pour représenter le nombre total de cas de COVID-19 dans les différents pays des États-Unis, à différents jours. Pour arriver à ce résultat, nous allons exploiter Seaborn , un package Python qui fournit de nombreuses fonctions sophistiquées et puissantes pour tracer des données.
Voici le code à discuter :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#url of the .csv file
url = r"path of the .csv file"
# import the .csv file into a pandas DataFrame
df = pd.read_csv(url, sep = ';', thousands = ',')
# defining the array containing the states present in the study
states = np.array(df['state'].drop_duplicates())[:40]
#extracting the total cases for each day and each country
overall_cases = []
for state in states:
tot_cases = []
for i in range(len(df['state'])):
if df['state'][i] == state:
tot_cases.append(df['tot_cases'][i])
overall_cases.append(tot_cases[:30])
data = pd.DataFrame(overall_cases).T
data.columns = states
#Plotting
fig = plt.figure()
ax = fig.subplots()
ax = sns.heatmap(data, annot = True, fmt="d", linewidths=0, cmap = 'viridis', xticklabels = True)
ax.invert_yaxis()
ax.set_xlabel('States')
ax.set_ylabel('Day n°')
plt.show()
Plongeons-nous dans le code pour apprendre étape par étape la fonctionnalité de carte thermique de Seaborn.
Importation des bibliothèques requises pour cet exemple
Nous commençons notre script en important les bibliothèques demandées pour exécuter cet exemple ; à savoir Numpy, Pandas, Matplotlib et Seaborn.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Que contiennent les données ?
Comme mentionné dans la partie introduction, nous utiliserons les données COVID-19 qui ont également été utilisées dans l'article sur Scipy.curve_fit() fonction. Les données ont été téléchargées depuis le site officiel des « Centers for Disease Control and Prevention » sous forme de fichier .csv.
Le dossier rapporte de multiples informations concernant la pandémie de COVID-19 dans les différents pays américains, comme le nombre total de cas, le nombre de nouveaux cas, le nombre de décès etc…; tous ont été enregistrés chaque jour, pour plusieurs pays américains.
Nous allons générer une carte thermique qui affiche dans chaque emplacement le nombre total de cas enregistrés pour un jour particulier dans un pays américain particulier. Pour ce faire, la première chose à faire est d'importer le fichier .csv et de le stocker dans un Pandas DataFrame.
Importer les données avec Pandas
Les données sont stockées dans un fichier .csv; les différentes valeurs sont séparées par un point-virgule tandis que le symbole des milliers est indiqué par une virgule. Afin d'importer le fichier .csv dans notre script python, nous exploitons la fonction Pandas .read_csv() qui accepte en entrée le chemin du fichier et le convertit en un Pandas DataFrame.
Il est important de noter que, lors de l'appel de .read_csv(), nous spécifions le séparateur, qui dans notre cas est ";" en disant "sep =';'" et le symbole utilisé pour désigner les milliers, en écrivant "milliers =','". Toutes ces choses sont contenues dans les lignes de code suivantes :
#url of the .csv file url = r"path of the file" # import the .csv file into a pandas DataFrame df = pd.read_csv(url, sep = ';', thousands = ',')
Création des tableaux qui seront utilisés dans la heatmap
À ce stade, nous devons éditer le DataFrame créé afin d'extraire uniquement les informations qui seront utilisées pour la création de la heatmap.
Les premières valeurs que nous extrayons sont celles qui décrivent le nom des pays dans lesquels les données ont été enregistrées. Pour mieux identifier toutes les catégories qui composent le DataFrame, nous pouvons taper "df.columns" pour imprimer l'en-tête du fichier. Parmi les différentes catégories présentes dans l'en-tête, celle qui nous intéresse est "état", dans laquelle on peut trouver le nom de tous les états impliqués dans ce tableau.
Les données étant enregistrées quotidiennement, chaque ligne correspond aux données collectées pour une seule journée dans un état spécifique; par conséquent, les noms des états sont répétés le long de cette colonne. Comme nous ne voulons aucune répétition dans notre carte thermique, nous devons également supprimer les doublons du tableau.
Nous procédons plus loin en définissant un tableau Numpy appelé "states" dans lequel nous stockons toutes les valeurs présentes sous la colonne "state" du DataFrame ; dans la même ligne de code, on applique également la méthode .drop_duplicates() pour supprimer tout doublon de ce tableau. Puisqu'il y a 60 états dans le DataFrame, nous limitons notre analyse aux 40 premiers, afin de ne pas créer de problèmes graphiques dans les étiquettes de l'axe x de la carte thermique, en raison de l'espace limité de la fenêtre.
#defining the array containing the states present in the study states = np.array(df['state'].drop_duplicates())[:40]
L'étape suivante consiste à extraire le nombre total de cas, enregistré pour chaque jour dans chaque pays. Pour ce faire, nous exploitons deux boucles for imbriquées qui nous permettent de créer une liste contenant le n° de cas totaux (un nombre entier pour chaque jour) pour chaque pays présent dans le tableau "states" et de les ajouter dans une autre liste appelée "overall_cases". ” qui doit être défini avant d'appeler la boucle for.
#extracting the total cases for each day and each country overall_cases = []
Comme vous pouvez le voir dans le code suivant, dans la première boucle for, nous parcourons les différents états précédemment stockés dans le tableau « states » ; pour chaque état, nous définissons une liste vide appelée "tot_cases" dans laquelle nous ajouterons les valeurs se référant au nombre total de cas enregistrés à chaque jour.
for state in states:
tot_cases = []
Une fois que nous sommes dans la première boucle for (ce qui signifie que nous avons affaire à un seul état), nous initialisons une autre boucle for qui parcourt toutes les valeurs de cas totales stockées pour cet état particulier. Cette deuxième boucle for commencera à partir de l'élément 0 et parcourra toutes les valeurs de la colonne "state" de notre DataFrame. Nous y parvenons en exploitant les fonctions range et len.
for i in range(len(df['state'])):
Une fois dans cette seconde for boucle, nous voulons ajouter à la liste "tot_cases" uniquement les valeurs qui font référence à l'état qui nous intéresse actuellement (c'est-à-dire celui défini dans la première boucle for, identifié par la valeur de la variable "state"); nous le faisons en utilisant l'instruction if suivante :
if df['state'][i] == state:
tot_cases.append(df['tot_cases'][i])
Lorsque nous avons fini d'ajouter les valeurs du nombre total de cas pour chaque jour d'un pays particulier à la liste "tot_cases", nous quittons la boucle for interne et stockons cette liste dans la liste "overall_cases", qui deviendra alors une liste de listes. Dans ce cas également, nous limitons notre analyse aux 30 premiers jours, sinon nous n'aurions pas assez d'espace dans notre heatmap pour toutes les 286 valeurs présentes dans le DataFrame.
overall_cases.append(tot_cases[:30])
À la prochaine itération, le code commencera à analyser le deuxième élément du tableau "states", c'est-à-dire un autre pays, initialisera une liste vide appelée "tot_cases" et entrera dans la deuxième boucle for pour ajouter toutes les valeurs référées à ce pays au cours des différents jours et éventuellement, une fois terminé, ajouter la liste complète à la liste « overall_cases » ; cette procédure sera itérée pour tous les pays stockés dans le tableau « states ». A la fin, nous aurons extrait toutes les valeurs nécessaires à la génération de notre heatmap.
Créer le DataFrame pour la carte thermique
Comme déjà introduit dans la première partie, nous exploitons la fonction Seaborn .heatmap() pour générer notre carte thermique.
Cette fonction peut prendre en entrée un pandas DataFrame qui contient les lignes, les colonnes et toutes les valeurs pour chaque cellule que nous voulons afficher dans notre graphique. Nous générons donc un nouveau pandas DataFrame (nous l'appelons "data") qui contient les valeurs stockées dans la liste "overall_cases" ; de cette façon, chaque ligne de ce nouveau DataFrame est référée à un état spécifique et chaque colonne à un jour spécifique.
On transpose ensuite ce DataFrame en ajoutant « .T » à la fin de la ligne de code, puisque de cette façon on peut alors insérer le nom des états comme en-tête de notre Dataframe.
data = pd.DataFrame(overall_cases).T
Les noms des états étaient auparavant stockés dans le tableau "states", nous pouvons modifier l'en-tête du DataFrame à l'aide du code suivant :
data.columns = states
Le DataFrame qui sera utilisé pour générer la heatmap aura la forme suivante :
CO FL AZ SC CT NE KY WY IA ... LA ID NV GA IN AR MD NY OR 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 4 0 0 1 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0
Les index des lignes représentent le n° du jour dans lequel les données sont enregistrées tandis que les colonnes de l'en-tête sont le nom des états.
Générer la carte thermique
Après avoir généré la fenêtre de tracé habituelle avec les fonctions typiques de matplotlib, nous appelons la fonction Seaborn .heatmap() pour générer la carte thermique.
L'entrée obligatoire de cette fonction est le pandas DataFrame que nous avons créé dans la section précédente. Il existe alors plusieurs paramètres d'entrée optionnels qui peuvent améliorer notre carte de chaleur :
- épaisseurs de ligne permet d'ajouter un contour blanc à chaque cellule pour mieux les séparer, il suffit de préciser la largeur;
- xticklabels modifiez la notation le long de l'axe des abscisses, si elle est égale à True, toutes les valeurs du tableau tracées sur l'axe des abscisses seront affichées.
- Nous pouvons également choisir la palette de couleurs de la carte de chaleur en utilisant cmap et en spécifiant le nom d'une carte thermique disponible ("viridis" ou "magma" sont très fantaisistes mais aussi celle par défaut de Seaborn est vraiment cool) ;
- enfin, il est possible d'afficher la valeur numérique de chaque cellule en utilisant l'option annot =True ; la valeur numérique sera affichée au centre de chaque cellule.
Les lignes suivantes contiennent le code pour tracer la carte thermique. Une dernière observation concerne la commande .invert_yaxis(); puisque nous traçons la heatmap directement à partir d'un DataFrame pandas, l'index de ligne sera le "jour n°" ; par conséquent, il commencera à partir de 0 et augmentera au fur et à mesure que nous descendrons le long des lignes. En ajoutant .invert_yaxis(), nous inversons l'axe des y, ayant le jour 0 dans la partie inférieure de la carte thermique.
#Plotting
fig = plt.figure()
ax = fig.subplots()
ax = sns.heatmap(data, annot = True, fmt="d", linewidths=0, cmap = 'viridis', xticklabels = True)
ax.invert_yaxis()
ax.set_xlabel('States')
ax.set_ylabel('Day n°')
plt.show()
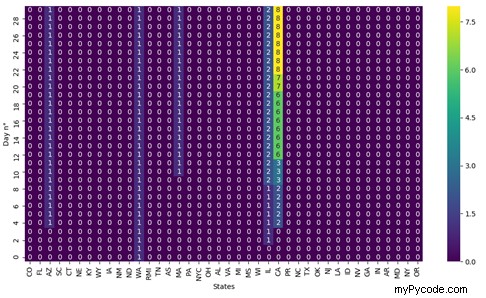
La figure 1 affiche la carte thermique obtenue par cet extrait de code.
Illustration 1 : Heatmap représentant le nombre total de cas de COVID-19 pour les 30 premiers jours de mesure (axe des ordonnées) dans les différents pays des États-Unis (axe des abscisses).
Comme vous pouvez le voir sur la figure 1, il y a beaucoup de zéros, c'est parce que nous avons décidé de tracer les données relatives aux 30 premiers jours de mesure, au cours desquels le nombre de cas enregistrés était très faible. Si nous décidions de tracer les résultats de tous les jours de mesure (du jour 0 au jour 286), nous obtiendrions le résultat affiché sur la figure 2 (dans ce dernier cas, nous avons placé annot égal à Faux car les nombres auraient été trop grands pour la taille de la cellule) :
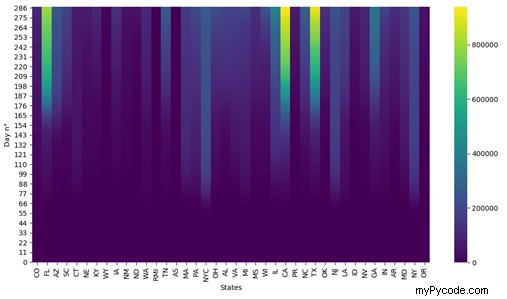
Illustration 2 : Carte thermique représentant le nombre de cas totaux de COVID-19 pour les 286 premiers jours de mesure (axe des ordonnées) dans les différents pays des États-Unis (axe des abscisses) ; cette fois annot =False , car les cellules sont trop petites pour accueillir le n° de cas totaux (qui devient très grand vers la partie supérieure de la heatmap).