Notez que factorplot est appelé 'catplot' dans les versions plus récentes de seaborn.
catplot ou factorplot sont des fonctions au niveau de la figure. Cela signifie qu'ils sont censés travailler au niveau d'une figure et non au niveau des axes.
Que se passe-t-il dans votre code :
f,axes=plt.subplots(1,2,figsize=(8,4))
- Cela crée la 'Figure 1'.
sns.factorplot(x="borough", y="pickups", hue="borough", kind='bar', data=n, size=4, aspect=2,ax=axes[0])
- Cela crée la 'Figure 2' mais au lieu de dessiner sur
Figure 2tu dis à seaborn de dessiner suraxes[0]à partir deFigure 1, doncFigure 2reste vide.
sns.factorplot(x="borough", y="pickups", hue="borough", kind='bar', data=low_pickups, size=4, aspect=2,ax=axes[1])
- Maintenant, cela crée encore une fois un chiffre :
Figure 3et là aussi, tu dis à seaborn de dessiner sur un axe deFigure 1,axes[1]c'est-à-dire.
plt.close(2)
- Ici vous fermez le
Figure 2vide créé par seaborn.
Alors maintenant, il vous reste Figure 1 avec les deux axes que vous avez en quelque sorte "injectés" dans le factorplot appels et avec le Figure 3 encore vide chiffre qui a été créé par le 2ème appel de factorplot mais ne jamais dire de contenu :(.
plt.show()
-
Et maintenant vous voyez
Figure 1avec 2 axes et leFigure 3avec une parcelle vide.C'est lorsqu'il est exécuté dans un terminal, dans un cahier, vous pouvez simplement voir les deux figures l'une en dessous de l'autre semblant être une figure à 3 axes.
Comment résoudre ce problème :
Vous avez 2 options :
1. Le plus rapide :
Fermez simplement Figure 3 avant plt.show() :
f,axes=plt.subplots(1,2,figsize=(8,4))
sns.factorplot(x="borough", y="pickups", hue="borough", kind='bar', data=n, size=4, aspect=2,ax=axes[0])
sns.factorplot(x="borough", y="pickups", hue="borough", kind='bar', data=low_pickups, size=4, aspect=2,ax=axes[1])
plt.close(2)
plt.close(3)
plt.show()
En gros, vous court-circuitez la partie de factorplot qui crée une figure et des axes sur lesquels dessiner en fournissant vos axes "personnalisés" à partir de Figure 1 .Probablement pas quoi factorplot a été conçu pour, mais bon, si ça marche, ça marche... et ça marche.
2. Le bon :
Laissez la fonction de niveau de figure faire son travail et créez ses propres figures. Ce que vous devez faire est de spécifier quelles variables vous voulez comme colonnes.
Puisqu'il semble que vous ayez 2 blocs de données, n et low_pickups , vous devez d'abord créer une seule trame de données avec la colonne dire cat soit n ou low_pickups :
# assuming n and low_pickups are a pandas.DataFrame:
# first add the 'cat' column for both
n['cat'] = 'n'
low_pickups['cat'] = 'low_pickups'
# now create a new dataframe that is a combination of both
comb_df = n.append(low_pickups)
Vous pouvez maintenant créer votre figure avec un seul appel à sns.catplot (ou sns.factorplot dans votre cas) en utilisant la variable cat en colonne :
sns.catplot(x="borough", y="pickups", col='cat', hue="borough", kind='bar', sharey=False, data=comb_df, size=4, aspect=1)
plt.legend()
plt.show()
Remarque :Le sharey=False est obligatoire car par défaut, ce serait vrai et vous ne verriez essentiellement pas les valeurs dans le 2ème panneau car elles sont considérablement plus petites que celles du premier panneau.
Version 2. donne alors : 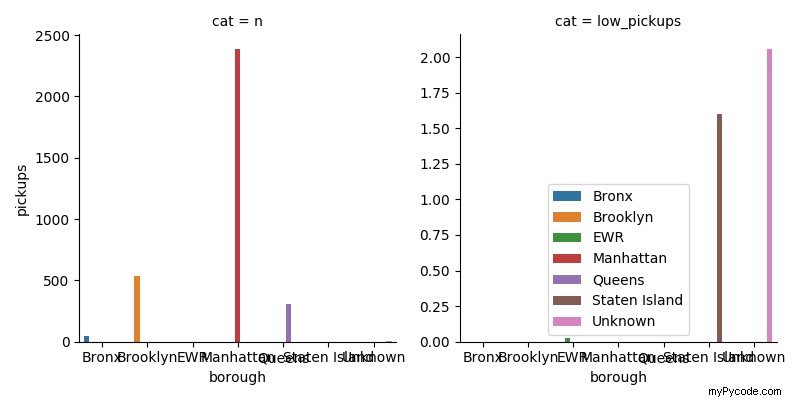
Vous aurez peut-être encore besoin d'un peu de style, mais je vous laisse faire;).
J'espère que cela vous a aidé !
Je suppose que c'est parce que FactorPlot lui-même utilise une sous-intrigue.
EDIT 2019-mars-10 18:43 GMT :Et cela est confirmé à partir du code source de Seaborn pour categorical.py :le catplot (et factorplot) utilise le sous-plot matplotlib. La réponse de @Jojo explique parfaitement ce qui se passe
def catplot(x=None, y=None, hue=None, data=None, row=None, col=None,
col_wrap=None, estimator=np.mean, ci=95, n_boot=1000,
units=None, order=None, hue_order=None, row_order=None,
col_order=None, kind="strip", height=5, aspect=1,
orient=None, color=None, palette=None,
legend=True, legend_out=True, sharex=True, sharey=True,
margin_titles=False, facet_kws=None, **kwargs):
... # bunch of code
g = FacetGrid(**facet_kws) # uses subplots
Et le code source axisgrid.py qui contient la définition FacetGrid :
class FacetGrid(Grid):
def __init(...):
... # bunch of code
# Build the subplot keyword dictionary
subplot_kws = {} if subplot_kws is None else subplot_kws.copy()
gridspec_kws = {} if gridspec_kws is None else gridspec_kws.copy()
# bunch of code
fig, axes = plt.subplots(nrow, ncol, **kwargs)
Alors oui, vous créiez beaucoup de sous-parcelles sans le savoir et vous les avez gâchées avec le ax=... paramètre.@ Jojo a raison.
Voici quelques autres options :
Option 1 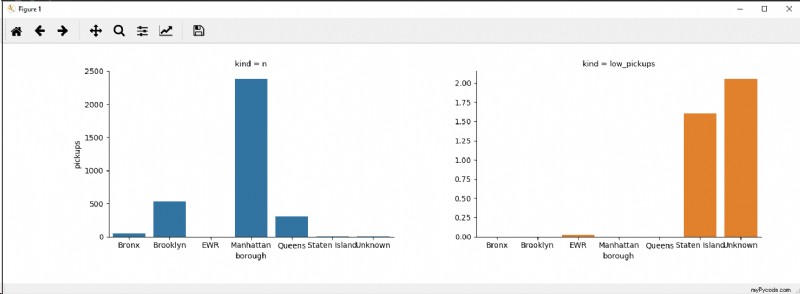
Option 2 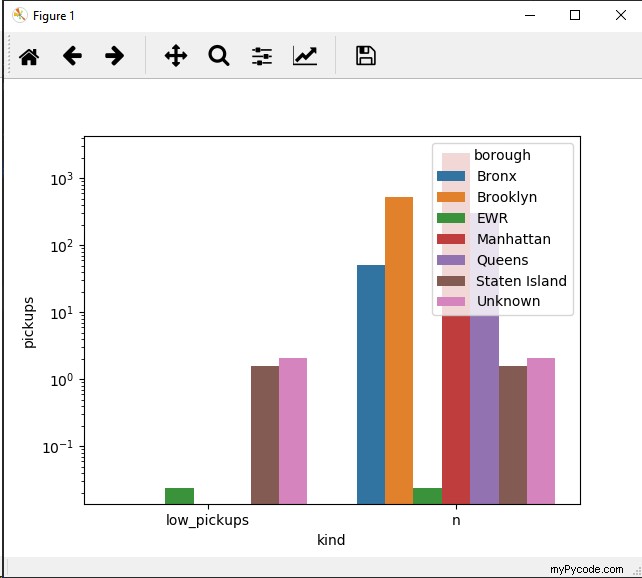
Attention, factorplot est obsolète dans les versions Seaborn supérieures.
import pandas as pd
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
print(pd.__version__)
print(sns.__version__)
print(matplotlib.__version__)
# n dataframe
n = pd.DataFrame(
{'borough': {0: 'Bronx', 1: 'Brooklyn', 2: 'EWR', 3: 'Manhattan', 4: 'Queens', 5: 'Staten Island', 6: 'Unknown'},
'kind': {0: 'n', 1: 'n', 2: 'n', 3: 'n', 4: 'n', 5: 'n', 6: 'n'},
'pickups': {0: 50.66705042597283, 1: 534.4312687082662, 2: 0.02417683628827999, 3: 2387.253281142068,
4: 309.35482385447847, 5: 1.6018880957863229, 6: 2.0571804140650674}})
# low_pickups dataframe
low_pickups = pd.DataFrame({'borough': {2: 'EWR', 5: 'Staten Island', 6: 'Unknown'},
'kind': {0: 'low_pickups', 1: 'low_pickups', 2: 'low_pickups', 3: 'low_pickups',
4: 'low_pickups', 5: 'low_pickups', 6: 'low_pickups'},
'pickups': {2: 0.02417683628827999, 5: 1.6018880957863229, 6: 2.0571804140650674}})
new_df = n.append(low_pickups).dropna()
print(n)
print('--------------')
print(low_pickups)
print('--------------')
print(new_df)
g = sns.FacetGrid(data=new_df, col="kind", hue='kind', sharey=False)
g.map(sns.barplot, "borough", "pickups", order=sorted(new_df['borough'].unique()))
plt.show()
Sorties console :
0.24.1
0.9.0
3.0.2
borough kind pickups
0 Bronx n 50.667050
1 Brooklyn n 534.431269
2 EWR n 0.024177
3 Manhattan n 2387.253281
4 Queens n 309.354824
5 Staten Island n 1.601888
6 Unknown n 2.057180
--------------
borough kind pickups
0 NaN low_pickups NaN
1 NaN low_pickups NaN
2 EWR low_pickups 0.024177
3 NaN low_pickups NaN
4 NaN low_pickups NaN
5 Staten Island low_pickups 1.601888
6 Unknown low_pickups 2.057180
--------------
borough kind pickups
0 Bronx n 50.667050
1 Brooklyn n 534.431269
2 EWR n 0.024177
3 Manhattan n 2387.253281
4 Queens n 309.354824
5 Staten Island n 1.601888
6 Unknown n 2.057180
2 EWR low_pickups 0.024177
5 Staten Island low_pickups 1.601888
6 Unknown low_pickups 2.057180
Ou essayez ceci :
g = sns.barplot(data=new_df, x="kind", y="pickups", hue='borough')#, order=sorted(new_df['borough'].unique()))
g.set_yscale('log')
J'ai dû utiliser une échelle logarithmique car les valeurs de données sont assez étalées sur une vaste plage. Vous pouvez envisager de faire des catégories (voir la coupe des pandas)
EDIT 2019-mars-10 18:43 GMT :comme @Jojo l'a indiqué dans sa réponse, la dernière option était en effet :
sns.catplot(data=new_df, x="borough", y="pickups", col='kind', hue='borough', sharey=False, kind='bar')
N'a pas eu le temps de terminer l'étude, donc tout le mérite lui revient !