Il y a au moins deux facteurs en jeu ici qui expliquent pourquoi vous obtenez des résultats différents :
- Il n'y a pas de définition unique de l'échelle mel.
Librosamettre en œuvre deux façons :Slaney et HTK. D'autres packages pourraient et vont utiliser des définitions différentes, conduisant à des résultats différents. Cela étant dit, l'image globale devrait être similaire. Cela nous amène au deuxième problème... python_speech_featurespar défaut met l'énergie en premier (indice zéro) coefficient (appendEnergyestTruepar défaut), ce qui signifie que lorsque vous demandez par ex. 13 MFCC, vous obtenez effectivement 12 + 1.
En d'autres termes, vous ne compariez pas 13 librosa contre 13 python_speech_features coefficients, mais plutôt 13 contre 12. L'énergie peut être de magnitude différente et donc produire une image assez différente en raison de l'échelle de couleurs différente.
Je vais maintenant démontrer comment les deux modules peuvent produire des résultats similaires :
import librosa
import python_speech_features
import matplotlib.pyplot as plt
from scipy.signal.windows import hann
import seaborn as sns
n_mfcc = 13
n_mels = 40
n_fft = 512
hop_length = 160
fmin = 0
fmax = None
sr = 16000
y, sr = librosa.load(librosa.util.example_audio_file(), sr=sr, duration=5,offset=30)
mfcc_librosa = librosa.feature.mfcc(y=y, sr=sr, n_fft=n_fft,
n_mfcc=n_mfcc, n_mels=n_mels,
hop_length=hop_length,
fmin=fmin, fmax=fmax, htk=False)
mfcc_speech = python_speech_features.mfcc(signal=y, samplerate=sr, winlen=n_fft / sr, winstep=hop_length / sr,
numcep=n_mfcc, nfilt=n_mels, nfft=n_fft, lowfreq=fmin, highfreq=fmax,
preemph=0.0, ceplifter=0, appendEnergy=False, winfunc=hann)
Comme vous pouvez le voir, l'échelle est différente, mais l'image globale semble vraiment similaire. Notez que je devais m'assurer qu'un certain nombre de paramètres passés aux modules est le même.
C'est le genre de chose qui m'empêche de dormir la nuit. Cette réponse est correcte (et extrêmement utile !) mais pas complète, car elle n'explique pas la grande différence entre les deux approches. Ma réponse ajoute un détail supplémentaire significatif mais n'obtient toujours pas de correspondances exactes.
Ce qui se passe est compliqué et mieux expliqué avec un long bloc de code ci-dessous qui compare librosa et python_speech_features à un autre paquet, torchaudio .
-
Tout d'abord, notez que l'implémentation de torchaudio a un argument,
log_melsdont la valeur par défaut (False) imite l'implémentation de librosa, mais si elle est définie sur True, elle imitera python_speech_features. Dans les deux cas, les résultats ne sont toujours pas exacts, mais les similitudes sont évidentes. -
Deuxièmement, si vous plongez dans le code de l'implémentation de torchaudio, vous verrez la note que la valeur par défaut n'est PAS une "implémentation de manuel" (les mots de torchaudio, mais je leur fais confiance) mais est fournie pour la compatibilité Librosa ; l'opération clé dans torchaudio qui passe de l'un à l'autre est :
mel_specgram = self.MelSpectrogram(waveform)
if self.log_mels:
log_offset = 1e-6
mel_specgram = torch.log(mel_specgram + log_offset)
else:
mel_specgram = self.amplitude_to_DB(mel_specgram)
-
Troisièmement, vous vous demanderez très raisonnablement si vous pouvez forcer librosa à agir correctement. La réponse est oui (ou du moins, "ça y ressemble") en prenant directement le spectrogramme mel, en prenant le log nautral de celui-ci, et en l'utilisant, plutôt que les échantillons bruts, comme entrée de la fonction librosa mfcc. Voir le code ci-dessous pour plus de détails.
-
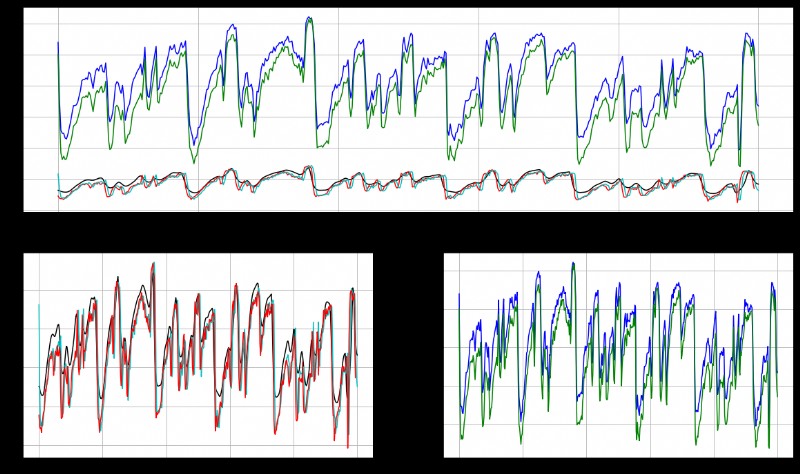
Enfin, soyez prudent et si vous utilisez ce code, examinez ce qui se passe lorsque vous examinez différentes fonctionnalités . La 0e caractéristique présente toujours de graves décalages inexpliqués, et les caractéristiques supérieures ont tendance à s'éloigner les unes des autres. Cela peut être quelque chose d'aussi simple que différentes implémentations sous le capot ou des constantes de stabilité numérique légèrement différentes, ou cela peut être quelque chose qui peut être corrigé avec un réglage fin, comme un choix de rembourrage ou peut-être une référence dans une conversion de décibel quelque part. Je ne sais vraiment pas.
Voici un exemple de code :
import librosa
import python_speech_features
import matplotlib.pyplot as plt
from scipy.signal.windows import hann
import torchaudio.transforms
import torch
n_mfcc = 13
n_mels = 40
n_fft = 512
hop_length = 160
fmin = 0
fmax = None
sr = 16000
melkwargs={"n_fft" : n_fft, "n_mels" : n_mels, "hop_length":hop_length, "f_min" : fmin, "f_max" : fmax}
y, sr = librosa.load(librosa.util.example_audio_file(), sr=sr, duration=5,offset=30)
# Default librosa with db mel scale
mfcc_lib_db = librosa.feature.mfcc(y=y, sr=sr, n_fft=n_fft,
n_mfcc=n_mfcc, n_mels=n_mels,
hop_length=hop_length,
fmin=fmin, fmax=fmax, htk=False)
# Nearly identical to above
# mfcc_lib_db = librosa.feature.mfcc(S=librosa.power_to_db(S), n_mfcc=n_mfcc, htk=False)
# Modified librosa with log mel scale (helper)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels, fmin=fmin,
fmax=fmax, hop_length=hop_length)
# Modified librosa with log mel scale
mfcc_lib_log = librosa.feature.mfcc(S=np.log(S+1e-6), n_mfcc=n_mfcc, htk=False)
# Python_speech_features
mfcc_speech = python_speech_features.mfcc(signal=y, samplerate=sr, winlen=n_fft / sr, winstep=hop_length / sr,
numcep=n_mfcc, nfilt=n_mels, nfft=n_fft, lowfreq=fmin, highfreq=fmax,
preemph=0.0, ceplifter=0, appendEnergy=False, winfunc=hann)
# Torchaudio 'textbook' log mel scale
mfcc_torch_log = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=True,
melkwargs=melkwargs)(torch.from_numpy(y))
# Torchaudio 'librosa compatible' default dB mel scale
mfcc_torch_db = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=False,
melkwargs=melkwargs)(torch.from_numpy(y))
feature = 1 # <-------- Play with this!!
plt.subplot(2, 1, 1)
plt.plot(mfcc_lib_log.T[:,feature], 'k')
plt.plot(mfcc_lib_db.T[:,feature], 'b')
plt.plot(mfcc_speech[:,feature], 'r')
plt.plot(mfcc_torch_log.T[:,feature], 'c')
plt.plot(mfcc_torch_db.T[:,feature], 'g')
plt.grid()
plt.subplot(2, 2, 3)
plt.plot(mfcc_lib_log.T[:,feature], 'k')
plt.plot(mfcc_torch_log.T[:,feature], 'c')
plt.plot(mfcc_speech[:,feature], 'r')
plt.grid()
plt.subplot(2, 2, 4)
plt.plot(mfcc_lib_db.T[:,feature], 'b')
plt.plot(mfcc_torch_db.T[:,feature], 'g')
plt.grid()
Honnêtement, aucune de ces implémentations n'est satisfaisante :
-
Python_speech_features adopte l'approche inexplicablement bizarre de remplacer la 0ème fonctionnalité par de l'énergie plutôt que de l'augmenter, et n'a pas d'implémentation delta couramment utilisée
-
Librosa est non standard par défaut sans avertissement et n'a pas de moyen évident d'augmenter l'énergie, mais possède une fonction delta hautement compétente ailleurs dans la bibliothèque.
-
Torchaudio imitera l'un ou l'autre, a également une fonction delta polyvalente, mais n'a toujours pas de moyen propre et évident d'obtenir de l'énergie.