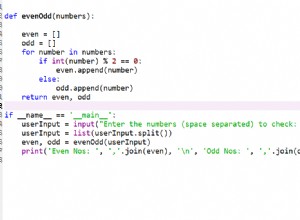
Lorsque vous convertissez le tableau en chaîne, il existe plusieurs nouvelles façons d'accéder au résultat :
>>> from pyspark.sql.functions import length, regexp_extract, array_join, reverse
>>>
>>> df = spark.createDataFrame([(1, [1, 2, 3]),
... (2, [2, 0]),
... (3, [0, 2, 3, 10]),
... (4, [0, 2, 3, 10, 0]),
... (5, [0, 1, 0, 0, 0]),
... (6, [0, 0, 0]),
... (7, [0, ]),
... (8, [10, ]),
... (9, [100, ]),
... (10, [0, 100, ]),
... (11, [])],
... schema=("id", "arr"))
>>>
>>>
>>> df.withColumn("trailing_zero_count",
... length(regexp_extract(array_join(reverse(df.arr), ""), "^(0+)", 0))
... ).show()
+---+----------------+-------------------+
| id| arr|trailing_zero_count|
+---+----------------+-------------------+
| 1| [1, 2, 3]| 0|
| 2| [2, 0]| 1|
| 3| [0, 2, 3, 10]| 0|
| 4|[0, 2, 3, 10, 0]| 1|
| 5| [0, 1, 0, 0, 0]| 3|
| 6| [0, 0, 0]| 3|
| 7| [0]| 1|
| 8| [10]| 0|
| 9| [100]| 0|
| 10| [0, 100]| 0|
| 11| []| 0|
+---+----------------+-------------------+
Depuis Spark 2.4, vous pouvez utiliser la fonction d'ordre supérieur AGGREGATE pour faire ça :
from pyspark.sql.functions import reverse
(
df.withColumn("arr_rev", reverse("A"))
.selectExpr(
"arr_rev",
"AGGREGATE(arr_rev, (1 AS p, CAST(0 AS LONG) AS sum), (buffer, value) -> (if(value != 0, 0, buffer.p), if(value=0, buffer.sum + buffer.p, buffer.sum)), buffer -> buffer.sum) AS result"
)
)
en supposant A est votre tableau avec des nombres. Ici, soyez prudent avec les types de données. Je lance la valeur initiale à LONG en supposant que les nombres à l'intérieur du tableau sont également longs.
Pour Spark 2.4+, vous devez absolument utiliser aggregate comme indiqué dans la réponse acceptée de @David Vrba.
Pour les modèles plus anciens, voici une alternative à l'approche des expressions régulières.
Commencez par créer des exemples de données :
import numpy as np
NROWS = 10
ARRAY_LENGTH = 5
np.random.seed(0)
data = [
(np.random.randint(0, 100, x).tolist() + [0]*(ARRAY_LENGTH-x),)
for x in np.random.randint(0, ARRAY_LENGTH+1, NROWS)
]
df = spark.createDataFrame(data, ["myArray"])
df.show()
#+--------------------+
#| myArray|
#+--------------------+
#| [36, 87, 70, 88, 0]|
#|[88, 12, 58, 65, 39]|
#| [0, 0, 0, 0, 0]|
#| [87, 46, 88, 0, 0]|
#| [81, 37, 25, 0, 0]|
#| [77, 72, 9, 0, 0]|
#| [20, 0, 0, 0, 0]|
#| [80, 69, 79, 0, 0]|
#|[47, 64, 82, 99, 88]|
#| [49, 29, 0, 0, 0]|
#+--------------------+
Parcourez maintenant vos colonnes en sens inverse et renvoyez null si la colonne est 0 , ou le ARRAY_LENGTH-(index+1) Par ailleurs. Fusionnez les résultats de ceci, ce qui renverra la valeur du premier index non nul - identique au nombre de 0 à la fin.
from pyspark.sql.functions import coalesce, col, when, lit,
df.withColumn(
"trailingZeroes",
coalesce(
*[
when(col('myArray').getItem(index) != 0, lit(ARRAY_LENGTH-(index+1)))
for index in range(ARRAY_LENGTH-1, -1, -1)
] + [lit(ARRAY_LENGTH)]
)
).show()
#+--------------------+--------------+
#| myArray|trailingZeroes|
#+--------------------+--------------+
#| [36, 87, 70, 88, 0]| 1|
#|[88, 12, 58, 65, 39]| 0|
#| [0, 0, 0, 0, 0]| 5|
#| [87, 46, 88, 0, 0]| 2|
#| [81, 37, 25, 0, 0]| 2|
#| [77, 72, 9, 0, 0]| 2|
#| [20, 0, 0, 0, 0]| 4|
#| [80, 69, 79, 0, 0]| 2|
#|[47, 64, 82, 99, 88]| 0|
#| [49, 29, 0, 0, 0]| 3|
#+--------------------+--------------+