Apprendre Python à travers des projets tels que le web scraping est génial. C'est ainsi que j'ai été initié à Python. Cela dit, pour augmenter la vitesse de votre scraping, vous pouvez faire trois choses :
- Changez l'analyseur html pour quelque chose de plus rapide. 'html.parser' est le plus lent de tous. Essayez de passer à 'lxml' ou 'html5lib'. (lire https://www.crummy.com/software/BeautifulSoup/bs4/doc/)

-
Supprimez les boucles et les regex car ils ralentissent votre script. Utilisez simplement les outils BeautifulSoup, le texte et la bande, et trouvez les bonnes balises. (voir mon script ci-dessous)
-
Étant donné que le goulot d'étranglement dans le web scraping est généralement IO, attendre d'obtenir des données à partir d'une page Web, l'utilisation de l'asynchrone ou du multithread augmentera la vitesse. Dans le script ci-dessous, j'ai utilisé le multithreading. L'objectif est d'extraire des données de plusieurs pages en même temps.
Donc, si nous connaissons le nombre maximum de pages, nous pouvons répartir nos requêtes en différentes plages et les extraire par lots :)
Exemple de code :
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import requests
from bs4 import BeautifulSoup as bs
data = defaultdict(list)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'}
def get_data(data, headers, page=1):
# Get start time
start_time = datetime.now()
url = f'https://www.jobstreet.co.id/en/job-search/job-vacancy/{page}/?src=20&srcr=2000&ojs=6'
r = requests.get(url, headers=headers)
# If the requests is fine, proceed
if r.ok:
jobs = bs(r.content,'lxml').find('div',{'id':'job_listing_panel'})
data['title'].extend([i.text.strip() for i in jobs.find_all('div',{'class':'position-title header-text'})])
data['company'].extend([i.text.strip() for i in jobs.find_all('h3',{'class':'company-name'})])
data['location'].extend([i['title'] for i in jobs.find_all('li',{'class':'job-location'})] )
data['desc'].extend([i.text.strip() for i in jobs.find_all('ul',{'class':'list-unstyled hidden-xs '})])
else:
print('connection issues')
print(f'Page: {page} | Time taken {datetime.now()-start_time}')
return data
def multi_get_data(data,headers,start_page=1,end_page=20,workers=20):
start_time = datetime.now()
# Execute our get_data in multiple threads each having a different page number
with ThreadPoolExecutor(max_workers=workers) as executor:
[executor.submit(get_data, data=data,headers=headers,page=i) for i in range(start_page,end_page+1)]
print(f'Page {start_page}-{end_page} | Time take {datetime.now() - start_time}')
return data
# Test page 10-15
k = multi_get_data(data,headers,start_page=10,end_page=15)
Résultats: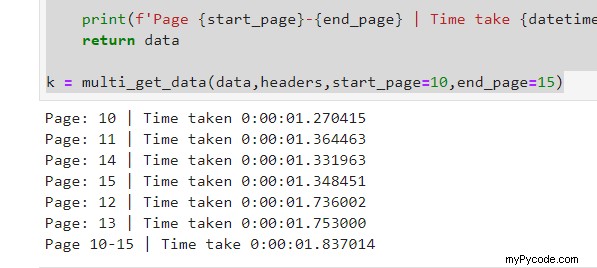
Explication de la fonction multi_get_data :
Cette fonction appellera la fonction get_data dans différents threads en passant les arguments souhaités. Pour le moment, chaque fil reçoit un numéro de page différent à appeler. Le nombre maximum de travailleurs est fixé à 20, ce qui signifie 20 threads. Vous pouvez augmenter ou diminuer en conséquence.
Nous avons créé des données variables, un dictionnaire par défaut, qui accepte les listes. Tous les threads rempliront ces données. Cette variable peut ensuite être convertie en json ou Pandas DataFrame :)
Comme vous pouvez le voir, nous avons 5 requêtes, chacune prenant moins de 2 secondes mais pourtant le total est toujours inférieur à 2 secondes;)
Profitez du web scraping.
Mettre à jour _:22/12/2019
Nous pourrions également gagner en vitesse en utilisant une session avec une seule mise à jour des en-têtes. Nous n'avons donc pas besoin de démarrer des sessions à chaque appel.
from requests import Session
s = Session()
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '\
'AppleWebKit/537.36 (KHTML, like Gecko) '\
'Chrome/75.0.3770.80 Safari/537.36'}
# Add headers
s.headers.update(headers)
# we can use s as we do requests
# s.get(...)
...
Le goulot d'étranglement est le serveur qui répond lentement à une requête simple.
Essayez de faire une demande parallèle.
Vous pouvez également utiliser des threads au lieu d'asyncio. Voici une question précédente expliquée pour paralléliser les tâches en Python :
Exécuter des tâches en parallèle en python
Veuillez noter qu'un serveur configuré intelligemment ralentirait toujours vos requêtes ou vous bannirait si vous scrapez sans autorisation.