プログラマーは通常、文字列を一連の文字と見なしますが、これは正確です。ただし、文字の保存方法はさまざまです。エンコーディングによっては、1 文字を格納するために 1 バイトを使用するものもあれば、2 バイトや 4 バイトを使用するものもあります。
この例は、文字エンコーディングを別のものに変更するとどうなるかを示しています。
例として、2 文字の文字列「PI」があり、1 文字を格納するのに 2 バイトのメモリが必要です。異なるタイプのエンコーディングを選択するとどうなるか見てみましょう。
文字列をバイトに変換
まず、エンコーディングを設定します。
str = 'PI'
str_utf8 = str.encode('utf8')
str_ascii = str.encode('ascii')
str_latin1 = str.encode('latin1')
str_utf16 = str.encode('utf16')
str_utf32 = str.encode('utf32')次に、これらの文字列とそのサイズを表示してみてください。
print(str, len(str))
print(str_utf8, len(str_utf8))
print(str_ascii, len(str_ascii))
print(str_latin1, len(str_latin1))
print(str_utf16, len(str_utf16))
print(str_utf32, len(str_utf32))結果は…
b'PI' 2 b'PI' 2 b'PI' 2 b'\xff\xfeP\x00I\x00' 6 b'\xff\xfe\x00\x00P\x00\x00\x00I\x00\x00\x00' 12
バイトを文字列に変換
これらの値を文字列に戻すには、次のコードを使用してください。
print(str_utf8.decode())
print(str_ascii.decode('ascii'))
print(str_latin1.decode('latin1'))
print(str_utf16.decode('utf16'))
print(str_utf32.decode('utf32'))この結果が得られます。
PI PI PI PI PI
ファイル内のバイトを文字列に変換
この例は、実際の例でバイトから文字列への変換を使用する方法を示しています。
まず、Windows のメモ帳で次のテキストを含むテキスト ファイルを作成しましょう:
このコンピュータは $900 の価値があります。
次のコードを使用する場合:
file_data = open('computer.txt', 'rb').read()
print(file_data)バイナリ テキストが表示されます。
b'This computer is worth $900.'
次のコードを使用して、バイナリ データを文字列にデコードします。
file_data = file_data.decode()
print(file_data)文字列は次のようになります:
This computer is worth $900.
「$」記号を「£」記号に変更しましょう。
このコンピュータは 900 ポンドの価値があります。
ファイルをメモ帳に保存しようとすると、次のメッセージが表示されます。
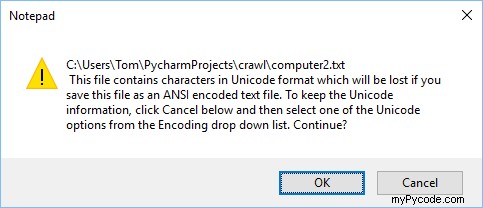
文字エンコーディングを変更せずにファイルを保存しようとすると、「£」文字が標準の ASCII テーブルから他の文字に変更されます。
どうすればよいでしょうか?
をクリックするだけです。>わかりました ファイル>> 名前を付けて保存… を選択して、エンコーディングを Unicode (UTF16) に変更します。 .適切なエンコーディングを選択します。
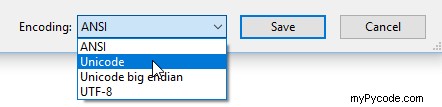
これで、ファイルを開くと、記号は変更されません。
このファイルを Python で開いてみましょう。
file_data = open('computer.txt', 'rb').read()
print(file_data)そのバイナリ バージョンはまったく判読できません。
b'\xff\xfeT\x00h\x00i\x00s\x00 \x00c\x00o\x00m\x00p\x00u\x00t\x00e\x00r\x00 \x00i\x00s\x00 \x00w\x00o\x00r\x00t\x00h\x00 \x00\xa3\x009\x000\x000\x00.\x00'
次のコードを追加してください。
file_data = file_data.decode('utf-16')
print(file_data)
テキストとして表示します。
このコンピュータは 900 ポンドの価値があります。