U kunt de roc-berekeningen opstarten (voorbeeld met vervangende nieuwe versies van y_true / y_pred uit de originele y_true / y_pred en bereken een nieuwe waarde voor roc_curve elke keer) en de schatting van een betrouwbaarheidsinterval op deze manier.
Om rekening te houden met de variabiliteit die wordt veroorzaakt door de splitsing van de treintest, kunt u de ShuffleSplit CV-iterator ook vaak gebruiken, een model op de splitsing van de trein passen, y_pred genereren voor elk model en verzamel zo een empirische verdeling van roc_curve s ook en bereken tenslotte betrouwbaarheidsintervallen daarvoor.
Bewerken :boosttrappen in python
Hier is een voorbeeld voor het bootstrappen van de ROC AUC-score uit de voorspellingen van een enkel model. Ik heb ervoor gekozen om de ROC AUC te bootstap om het gemakkelijker te kunnen volgen als een Stack Overflow-antwoord, maar het kan worden aangepast om in plaats daarvan de hele curve op te starten:
import numpy as np
from scipy.stats import sem
from sklearn.metrics import roc_auc_score
y_pred = np.array([0.21, 0.32, 0.63, 0.35, 0.92, 0.79, 0.82, 0.99, 0.04])
y_true = np.array([0, 1, 0, 0, 1, 1, 0, 1, 0 ])
print("Original ROC area: {:0.3f}".format(roc_auc_score(y_true, y_pred)))
n_bootstraps = 1000
rng_seed = 42 # control reproducibility
bootstrapped_scores = []
rng = np.random.RandomState(rng_seed)
for i in range(n_bootstraps):
# bootstrap by sampling with replacement on the prediction indices
indices = rng.randint(0, len(y_pred), len(y_pred))
if len(np.unique(y_true[indices])) < 2:
# We need at least one positive and one negative sample for ROC AUC
# to be defined: reject the sample
continue
score = roc_auc_score(y_true[indices], y_pred[indices])
bootstrapped_scores.append(score)
print("Bootstrap #{} ROC area: {:0.3f}".format(i + 1, score))
U kunt zien dat we een aantal ongeldige resamples moeten afwijzen. Bij echte gegevens met veel voorspellingen is dit echter een zeer zeldzame gebeurtenis en zou dit geen significante invloed moeten hebben op het betrouwbaarheidsinterval (u kunt proberen de rng_seed te variëren om te controleren).
Hier is het histogram:
import matplotlib.pyplot as plt
plt.hist(bootstrapped_scores, bins=50)
plt.title('Histogram of the bootstrapped ROC AUC scores')
plt.show()
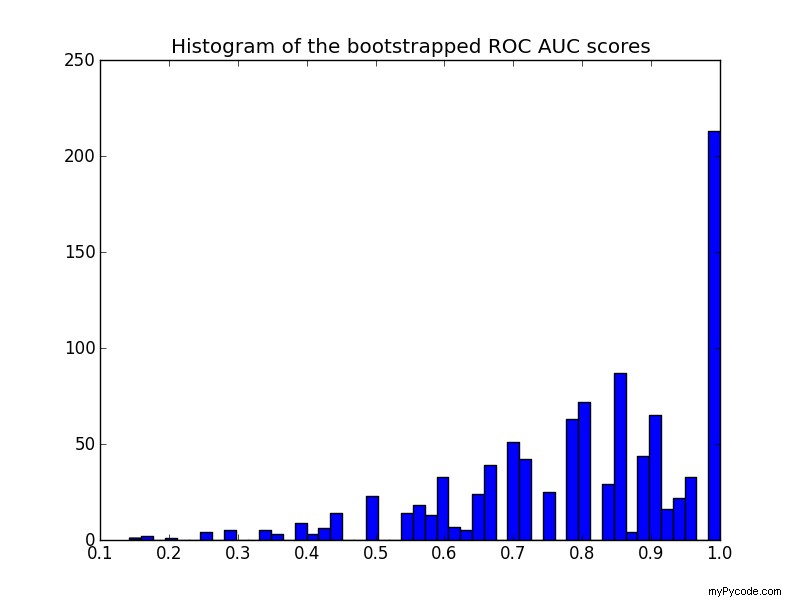
Merk op dat de opnieuw gesamplede scores worden gecensureerd in het bereik [0 - 1], wat een hoog aantal scores in de laatste bak veroorzaakt.
Om een betrouwbaarheidsinterval te krijgen kan men de steekproeven sorteren:
sorted_scores = np.array(bootstrapped_scores)
sorted_scores.sort()
# Computing the lower and upper bound of the 90% confidence interval
# You can change the bounds percentiles to 0.025 and 0.975 to get
# a 95% confidence interval instead.
confidence_lower = sorted_scores[int(0.05 * len(sorted_scores))]
confidence_upper = sorted_scores[int(0.95 * len(sorted_scores))]
print("Confidence interval for the score: [{:0.3f} - {:0.3}]".format(
confidence_lower, confidence_upper))
wat geeft:
Confidence interval for the score: [0.444 - 1.0]
Het betrouwbaarheidsinterval is erg breed, maar dit is waarschijnlijk een gevolg van mijn keuze van voorspellingen (3 fouten van 9 voorspellingen) en het totale aantal voorspellingen vrij klein.
Nog een opmerking over de plot:de scores zijn gekwantiseerd (veel lege histogrambakken). Dit is een gevolg van het kleine aantal voorspellingen. Je zou een beetje Gaussiaanse ruis op de partituren kunnen introduceren (of de y_pred waarden) om de verdeling af te vlakken en het histogram er beter uit te laten zien. Maar dan is de keuze van de afvlakkingsbandbreedte lastig.
Tot slot, zoals eerder vermeld, is dit betrouwbaarheidsinterval specifiek voor uw trainingsset. Om een betere schatting te krijgen van de variabiliteit van de ROC die wordt veroorzaakt door uw modelklasse en parameters, moet u in plaats daarvan herhaalde kruisvalidatie uitvoeren. Dit is echter vaak veel duurder omdat je een nieuw model moet trainen voor elke willekeurige trein-/testsplitsing.
DeLong-oplossing [GEEN bootstrapping]
Zoals sommigen hier suggereerden, een pROC aanpak zou fijn zijn. Volgens pROC documentatie worden betrouwbaarheidsintervallen berekend via DeLong:
DeLong is een asymptotisch exacte methode om de onzekerheid van een AUC te evalueren (DeLong et al. (1988)). Sinds versie 1.9 gebruikt pROC het door Sun en Xu (2014) voorgestelde algoritme dat een O(N log N)-complexiteit heeft en altijd sneller is dan bootstrapping. Standaard kiest pROC waar mogelijk de DeLong-methode.
Yandex Data School heeft een Fast DeLong-implementatie op hun openbare repo:
https://github.com/yandexdataschool/roc_comparison
Dus alle lof voor hen voor de DeLong-implementatie die in dit voorbeeld wordt gebruikt. Dus hier is hoe u een CI via DeLong krijgt:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 6 10:06:52 2018
@author: yandexdataschool
Original Code found in:
https://github.com/yandexdataschool/roc_comparison
updated: Raul Sanchez-Vazquez
"""
import numpy as np
import scipy.stats
from scipy import stats
# AUC comparison adapted from
# https://github.com/Netflix/vmaf/
def compute_midrank(x):
"""Computes midranks.
Args:
x - a 1D numpy array
Returns:
array of midranks
"""
J = np.argsort(x)
Z = x[J]
N = len(x)
T = np.zeros(N, dtype=np.float)
i = 0
while i < N:
j = i
while j < N and Z[j] == Z[i]:
j += 1
T[i:j] = 0.5*(i + j - 1)
i = j
T2 = np.empty(N, dtype=np.float)
# Note(kazeevn) +1 is due to Python using 0-based indexing
# instead of 1-based in the AUC formula in the paper
T2[J] = T + 1
return T2
def compute_midrank_weight(x, sample_weight):
"""Computes midranks.
Args:
x - a 1D numpy array
Returns:
array of midranks
"""
J = np.argsort(x)
Z = x[J]
cumulative_weight = np.cumsum(sample_weight[J])
N = len(x)
T = np.zeros(N, dtype=np.float)
i = 0
while i < N:
j = i
while j < N and Z[j] == Z[i]:
j += 1
T[i:j] = cumulative_weight[i:j].mean()
i = j
T2 = np.empty(N, dtype=np.float)
T2[J] = T
return T2
def fastDeLong(predictions_sorted_transposed, label_1_count, sample_weight):
if sample_weight is None:
return fastDeLong_no_weights(predictions_sorted_transposed, label_1_count)
else:
return fastDeLong_weights(predictions_sorted_transposed, label_1_count, sample_weight)
def fastDeLong_weights(predictions_sorted_transposed, label_1_count, sample_weight):
"""
The fast version of DeLong's method for computing the covariance of
unadjusted AUC.
Args:
predictions_sorted_transposed: a 2D numpy.array[n_classifiers, n_examples]
sorted such as the examples with label "1" are first
Returns:
(AUC value, DeLong covariance)
Reference:
@article{sun2014fast,
title={Fast Implementation of DeLong's Algorithm for
Comparing the Areas Under Correlated Receiver Oerating Characteristic Curves},
author={Xu Sun and Weichao Xu},
journal={IEEE Signal Processing Letters},
volume={21},
number={11},
pages={1389--1393},
year={2014},
publisher={IEEE}
}
"""
# Short variables are named as they are in the paper
m = label_1_count
n = predictions_sorted_transposed.shape[1] - m
positive_examples = predictions_sorted_transposed[:, :m]
negative_examples = predictions_sorted_transposed[:, m:]
k = predictions_sorted_transposed.shape[0]
tx = np.empty([k, m], dtype=np.float)
ty = np.empty([k, n], dtype=np.float)
tz = np.empty([k, m + n], dtype=np.float)
for r in range(k):
tx[r, :] = compute_midrank_weight(positive_examples[r, :], sample_weight[:m])
ty[r, :] = compute_midrank_weight(negative_examples[r, :], sample_weight[m:])
tz[r, :] = compute_midrank_weight(predictions_sorted_transposed[r, :], sample_weight)
total_positive_weights = sample_weight[:m].sum()
total_negative_weights = sample_weight[m:].sum()
pair_weights = np.dot(sample_weight[:m, np.newaxis], sample_weight[np.newaxis, m:])
total_pair_weights = pair_weights.sum()
aucs = (sample_weight[:m]*(tz[:, :m] - tx)).sum(axis=1) / total_pair_weights
v01 = (tz[:, :m] - tx[:, :]) / total_negative_weights
v10 = 1. - (tz[:, m:] - ty[:, :]) / total_positive_weights
sx = np.cov(v01)
sy = np.cov(v10)
delongcov = sx / m + sy / n
return aucs, delongcov
def fastDeLong_no_weights(predictions_sorted_transposed, label_1_count):
"""
The fast version of DeLong's method for computing the covariance of
unadjusted AUC.
Args:
predictions_sorted_transposed: a 2D numpy.array[n_classifiers, n_examples]
sorted such as the examples with label "1" are first
Returns:
(AUC value, DeLong covariance)
Reference:
@article{sun2014fast,
title={Fast Implementation of DeLong's Algorithm for
Comparing the Areas Under Correlated Receiver Oerating
Characteristic Curves},
author={Xu Sun and Weichao Xu},
journal={IEEE Signal Processing Letters},
volume={21},
number={11},
pages={1389--1393},
year={2014},
publisher={IEEE}
}
"""
# Short variables are named as they are in the paper
m = label_1_count
n = predictions_sorted_transposed.shape[1] - m
positive_examples = predictions_sorted_transposed[:, :m]
negative_examples = predictions_sorted_transposed[:, m:]
k = predictions_sorted_transposed.shape[0]
tx = np.empty([k, m], dtype=np.float)
ty = np.empty([k, n], dtype=np.float)
tz = np.empty([k, m + n], dtype=np.float)
for r in range(k):
tx[r, :] = compute_midrank(positive_examples[r, :])
ty[r, :] = compute_midrank(negative_examples[r, :])
tz[r, :] = compute_midrank(predictions_sorted_transposed[r, :])
aucs = tz[:, :m].sum(axis=1) / m / n - float(m + 1.0) / 2.0 / n
v01 = (tz[:, :m] - tx[:, :]) / n
v10 = 1.0 - (tz[:, m:] - ty[:, :]) / m
sx = np.cov(v01)
sy = np.cov(v10)
delongcov = sx / m + sy / n
return aucs, delongcov
def calc_pvalue(aucs, sigma):
"""Computes log(10) of p-values.
Args:
aucs: 1D array of AUCs
sigma: AUC DeLong covariances
Returns:
log10(pvalue)
"""
l = np.array([[1, -1]])
z = np.abs(np.diff(aucs)) / np.sqrt(np.dot(np.dot(l, sigma), l.T))
return np.log10(2) + scipy.stats.norm.logsf(z, loc=0, scale=1) / np.log(10)
def compute_ground_truth_statistics(ground_truth, sample_weight):
assert np.array_equal(np.unique(ground_truth), [0, 1])
order = (-ground_truth).argsort()
label_1_count = int(ground_truth.sum())
if sample_weight is None:
ordered_sample_weight = None
else:
ordered_sample_weight = sample_weight[order]
return order, label_1_count, ordered_sample_weight
def delong_roc_variance(ground_truth, predictions, sample_weight=None):
"""
Computes ROC AUC variance for a single set of predictions
Args:
ground_truth: np.array of 0 and 1
predictions: np.array of floats of the probability of being class 1
"""
order, label_1_count, ordered_sample_weight = compute_ground_truth_statistics(
ground_truth, sample_weight)
predictions_sorted_transposed = predictions[np.newaxis, order]
aucs, delongcov = fastDeLong(predictions_sorted_transposed, label_1_count, ordered_sample_weight)
assert len(aucs) == 1, "There is a bug in the code, please forward this to the developers"
return aucs[0], delongcov
alpha = .95
y_pred = np.array([0.21, 0.32, 0.63, 0.35, 0.92, 0.79, 0.82, 0.99, 0.04])
y_true = np.array([0, 1, 0, 0, 1, 1, 0, 1, 0 ])
auc, auc_cov = delong_roc_variance(
y_true,
y_pred)
auc_std = np.sqrt(auc_cov)
lower_upper_q = np.abs(np.array([0, 1]) - (1 - alpha) / 2)
ci = stats.norm.ppf(
lower_upper_q,
loc=auc,
scale=auc_std)
ci[ci > 1] = 1
print('AUC:', auc)
print('AUC COV:', auc_cov)
print('95% AUC CI:', ci)
uitgang:
AUC: 0.8
AUC COV: 0.028749999999999998
95% AUC CI: [0.46767194, 1.]
Ik heb ook gecontroleerd of deze implementatie overeenkomt met de pROC resultaten verkregen van R :
library(pROC)
y_true = c(0, 1, 0, 0, 1, 1, 0, 1, 0)
y_pred = c(0.21, 0.32, 0.63, 0.35, 0.92, 0.79, 0.82, 0.99, 0.04)
# Build a ROC object and compute the AUC
roc = roc(y_true, y_pred)
roc
uitgang:
Call:
roc.default(response = y_true, predictor = y_pred)
Data: y_pred in 5 controls (y_true 0) < 4 cases (y_true 1).
Area under the curve: 0.8
Dan
# Compute the Confidence Interval
ci(roc)
uitvoer
95% CI: 0.4677-1 (DeLong)

