Denne artikkelen omhandler beregning av persentiler. Persentiler er statistiske indikatorer som brukes til å beskrive spesifikke deler av en utvalgspopulasjon. De følgende avsnittene vil forklare hva persentiler er, hva de brukes til og hvordan de beregnes ved hjelp av Python. Som du vil se, tillater Python å løse dette problemet på flere måter, enten ved å definere en funksjon manuelt eller ved å utnytte Numpy .
Hva er prosentiler?
Persentiler er statistiske indikatorer som ofte brukes til å identifisere en viss del av en utvalgspopulasjon. Mer presist bruker vi en persentil for å indikere verdien (av variabelen som er under vurdering) som en bestemt prosentandel av utvalgspopulasjonen faller under. For eksempel, hvis vi vurderer høydefordelingen til alle engelskmennene som bor i Storbritannia; ved å si at høydeverdien på 180 cm identifiserer den 65. th persentil betyr det at 65 % av alle engelskmennene som bor i Storbritannia er kortere enn 180 cm . Som du kan forestille deg, er persentil ofte brukt i mange statistiske studier og når du rapporterer resultater fra undersøkelser eller målinger på store populasjoner.
Hvordan beregner man prosentiler?
La oss anta å ha samlet høyden på n =58 mennesker; for å evaluere persentilene som refereres til denne fordelingen, er det første trinnet å sortere alle verdiene i stigende rekkefølge. Anta at vi på dette tidspunktet blir bedt om å beregne den 75 th persentil av fordelingen; vi beregner den såkalte rangeringen k =persentil/100 . I dette tilfellet er k =75/100 =0,75 . Nå må vi multiplisere rangeringen for det totale antallet prøver i fordelingen (n, i dette tilfellet 58); vi får derfor k x n =0,75 x 58 =43,5 . Siden resultatet ikke er et helt tall, tilnærmer vi verdien til nærmeste hele tall (44 i dette tilfellet). Det neste trinnet består i å finne høydeverdien som tilsvarer den 44 th posisjon innenfor prøvefordelingen; den verdien tilsvarer den 75 th persentil. I tilfelle resultatet k x n er et helt tall, går vi videre ved å direkte finne den tilsvarende verdien i prøvefordelingen; det er allerede prosentilen vår.
Beregn prosentiler i Python
Nå som vi vet hva prosentiler er og hvordan de kan beregnes, vil vi se hvordan Python gjør denne oppgaven veldig enkel og rask. I den første delen vil vi løse problemet ved å definere en funksjon som utfører alle trinnene illustrert i forrige del, mens i den andre delen vil vi utnytte Numpy innebygd funksjon .percentile() .
Importere de passende bibliotekene
Vi starter skriptet vårt ved å importere bibliotekene som skal brukes gjennom eksemplet.
Vi må importere
-
mathfor å kunne runde av flytende tall til nærmeste heltall, - Numpy for funksjonen
.percentile(), og - Matplotlib for den siste delen, der vi vil plotte verdiene til persentilene på fordelingen.
import numpy as np import math import matplotlib.pyplot as plt
Skrive en Python-funksjon for å beregne prosentiler
I denne første delen skal vi se hvordan vi bygger opp en funksjon for å beregne persentilene. Målet med denne delen er rent didaktisk, som du vil se senere, Python tilbyr innebygde biblioteker som løser oppgaven automatisk. Det er imidlertid alltid viktig å forstå hvordan problemet løses og hvordan en spesifikk Python-funksjon fungerer.
def my_percentile(data, percentile):
n = len(data)
p = n * percentile / 100
if p.is_integer():
return sorted(data)[int(p)]
else:
return sorted(data)[int(math.ceil(p)) - 1]
Vi starter med å kalle funksjonen vår my_percentile , vil den ta prøvefordelingen og persentilen som vi ønsker å beregne som inputparametere. Som beskrevet ovenfor, er det første trinnet å evaluere størrelsen på distribusjonen vår (n); så beregner vi produktet "p" av prøvestørrelsen og rangeringen.
På dette tidspunktet må vi instansiere en if-setning , for å skille tilfellet der k x n er et helt tall fra tilfellet der det ikke er det. Vi utnytter Python metode .is_integer() for å vurdere om p er et helt tall; denne metoden returnerer True i det positive tilfellet.
Hvis p.is_integer() returnerer True , må vi søke etter p-th verdier i vår distribusjon (sortert i stigende rekkefølge). For å sortere fordelingen i stigende rekkefølge brukte vi funksjonen sorted() og pass som inngangsparameter selve distribusjonen. Det som er viktig å huske er å konvertere p fra float (siden det kommer fra den matematiske operasjonen gjort i forrige linje) til heltall; ellers får du en feilmelding som sier at indeksverdien til listen skal være et heltall.
Vi avslutter med å gi en else-setning som dekker tilfellet der verdien av p er ikke et helt tall; i dette tilfellet, ved å bruke funksjonen .ceil() (fra math bibliotek), vi anslår verdien av p til nærmeste høyere heltall.
Vi konverterer så dette tallet til et heltall og trekker fra 1 for å matche indekseringen som brukes i listene. Følgende kodelinjer kan du finne alle trinnene som er forklart så langt, i denne delen.
Beregne prosentiler ved hjelp av funksjonen vår
For å sjekke om funksjonen vår fungerer bra, må vi først definere en fordeling av verdier; for å gjøre det, kan vi utnytte Numpy funksjon .random.randn() , som trekker tilfeldige verdier fra normalfordelingen, må vi bare sende som input-parameter størrelsen på matrisen. Vi velger å lage en matrise med 10 000 verdier.
dist = np.random.randn(10000)
La oss nå prøve å beregne verdiene til den 5
th
, 25
th
, 50
th
, 75
th
og 95
th
persentiler. Vi kan derfor bygge en liste, kalt "perc_func ” som inneholder alle disse persentilene, evaluert gjennom funksjonen vår. Før vi gjør det, definerer vi en liste kalt «index ” som inneholder verdiene til persentilene som vi er interessert i. Etter det utnytter vi listeforståelse for å kalle funksjonen my_percentile() for hver persentil definert i listen «index ”.
index = [5, 25, 50, 75, 95] perc_func = [my_percentile(dist, i) for i in index]
På dette tidspunktet vises listen «perc_func " skal inneholde verdiene som tilsvarer alle persentilene som er oppført i listen "index ”.
Beregner prosentiler ved å bruke Numpy.percentiles()
Nå som vi vet hvordan vi beregner persentiler av en fordeling, kan vi også utnytte Numpy innebygd funksjon, for å gjøre det raskere og mer effektivt.
.percentile() funksjonen tar som inputparametere prøvefordelingen og persentilen som vi er interessert i. Den lar oss også bestemme hvilken metode som skal brukes i tilfelle produktet n x k er ikke et helt tall; Det er faktisk ikke bare en enkelt riktig måte å gjøre det på, tidligere bestemte vi oss for å tilnærme verdien til nærmeste heltall; men vi kan også velge å tilnærme det til det nærmeste høyere/lavere heltall eller å ta middelverdien mellom de lavere og høyere nærmeste heltall.
Alle disse alternativene kan velges ved å velge blant disse nøkkelordene for alternativet «interpolation " ['linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’].
Du finner den fullstendige dokumentasjonen på .percentile() funksjon her.
De ulike alternativene kan føre til litt forskjellige resultater, vi velger alternativet «nearest ”, for å matche metoden som brukes i funksjonen “my_percentile ". På en lignende måte som vi gjorde i forrige seksjon, lager vi en liste kalt «perc_numpy ” der vi lagrer verdiene til den 5.
th
, 25
th
, 50
th
, 75
th
og 95
th
persentiler, evaluert ved hjelp av Numpy . Følgende kodelinjer beskriver de nettopp forklarte prosedyrene.
# Using numpy for calculating percentiles perc_numpy = [np.percentile(dist, i, interpolation='nearest') for i in index]
Vi kan nå skrive ut de to listene og sjekke om de oppnådde resultatene er like.
print(perc_func) print(perc_numpy)
Plott prosentilene på distribusjonen
I begynnelsen av artikkelen definerte vi hva persentiler representerer.
Siden statistiske definisjoner kan være ganske vanskelige å forstå, kan vi vise fordelingen av verdier og se hvor de beregnede persentilene befinner seg i fordelingen.
For å gjøre det, utnytter vi Matplotlib og funksjonen .axvline() , som gjør det mulig å plotte vertikale linjer på et plott. Vi plasserer funksjonen axvline() inn i en for-løkke for å lage en vertikal linje for hver persentil i listen «perc_func ". For å markere prosentillinjene bedre bruker vi fargen rød.
# Plotting
plt.hist(dist, 50)
for i in range(len(index)):
plt.axvline(perc_func[i], color='r')
plt.show()
Det endelige resultatet vises i Figur 1; som du kan se, den 50. persentilen er plassert rett i midten av fordelingen, mens den 95 th persentil er den siste linjen og tilsvarer verdien under som vi kan finne 95 % av utvalgspopulasjonen.
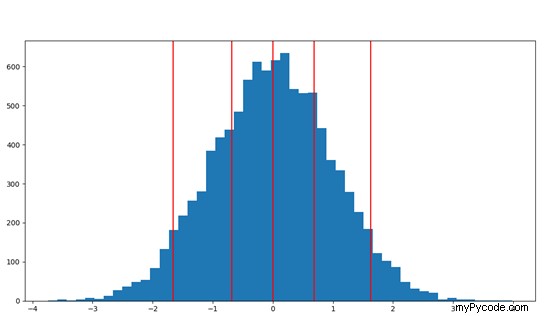
Figur 1: Representasjon av normalfordelingen brukt i eksemplet, med de vertikale røde linjene som tilsvarer (fra venstre til høyre) til den 5. . , 25 th , 50 th , 75 th og 95 th persentiler.
Konklusjoner
I denne artikkelen lærte vi om persentiler , hva de er, hva de representerer og hvordan de kan brukes til å beskrive en del av en prøvefordeling. Fra deres statistiske definisjon utviklet vi en Python-funksjon for å beregne persentilene til en prøvefordeling.
Etter det utforsket vi Numpy funksjon .percentile() som gjør det mulig å beregne persentiler av en prøvefordeling på en superrask og effektiv måte.
Vi sammenlignet deretter resultatene av de to metodene og sjekket at de var identiske.
Til slutt viste vi også grafisk prosentilene, som vi tidligere beregnet, på prøvefordelingen, for å få en bedre forståelse av deres faktiske betydning.

